
ASCII 码表
回忆上次内容
-
通过 help()可以从 python 命令行模式进入到帮助模式
- 通过 q 退出
-
ord(c)和 chr(i)
- 这是俩函数
-
这俩是一对,相反相成的
ord通过字符找到对应的数字chr通过数字找到对应的字符
字符的本质是数字
-
Python 里面的字符对应着一些数字
a对应 97b对应 98c对应 99
- 可是,为什么是这样的对应关系,谁规定的,必须的么?🤔
小写字母
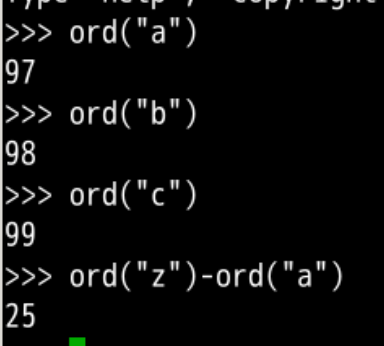
#输出a,b,c
ord("a")
ord("b")
ord("c")
#输出z-a的数字差距,相对序号
ord("z")-ord("a")
#输出a的相对序号
ord("a")-ord("a")
- a、b、c 这些字符是挨着的
- 正好从0到25,总共26个数字🔢
- 对应数字也是挨着的
编码规律
- 从 a-z 应该都是挨着的
- 26 个英文字母之间,数值差距是 25,说明都是挨着的
-
为什么是从 97 开始?
- 应该还有别的字符
- 除了小写字母之外、大写字母、数字、符号他们都是如何的分布的呢?
- 我想把所有 ASCII 字符 0-127 全都打出来
- 可以么?
遍历范围

for i in range(0,128):
print(i,end=",")
- 我们先把0-127 挨牌儿捋一遍

- 然后如何找到数字对应的字符呢?
对应字符
- 通过数字找到对应的字符是chr

for i in range(0,128):
print(hex(i),chr(i),sep=":",end=" ")
-
print(hex(i),chr(i),sep=":",end=" ")
-
hex(i)
- 输出i的十六进制状态
-
chr(i)
- 输出i的字符状态
-
sep=':'
- 分隔符为冒号
-
end=" "
- 结束时输出3个空格
-
- 结果如何呢?
结果
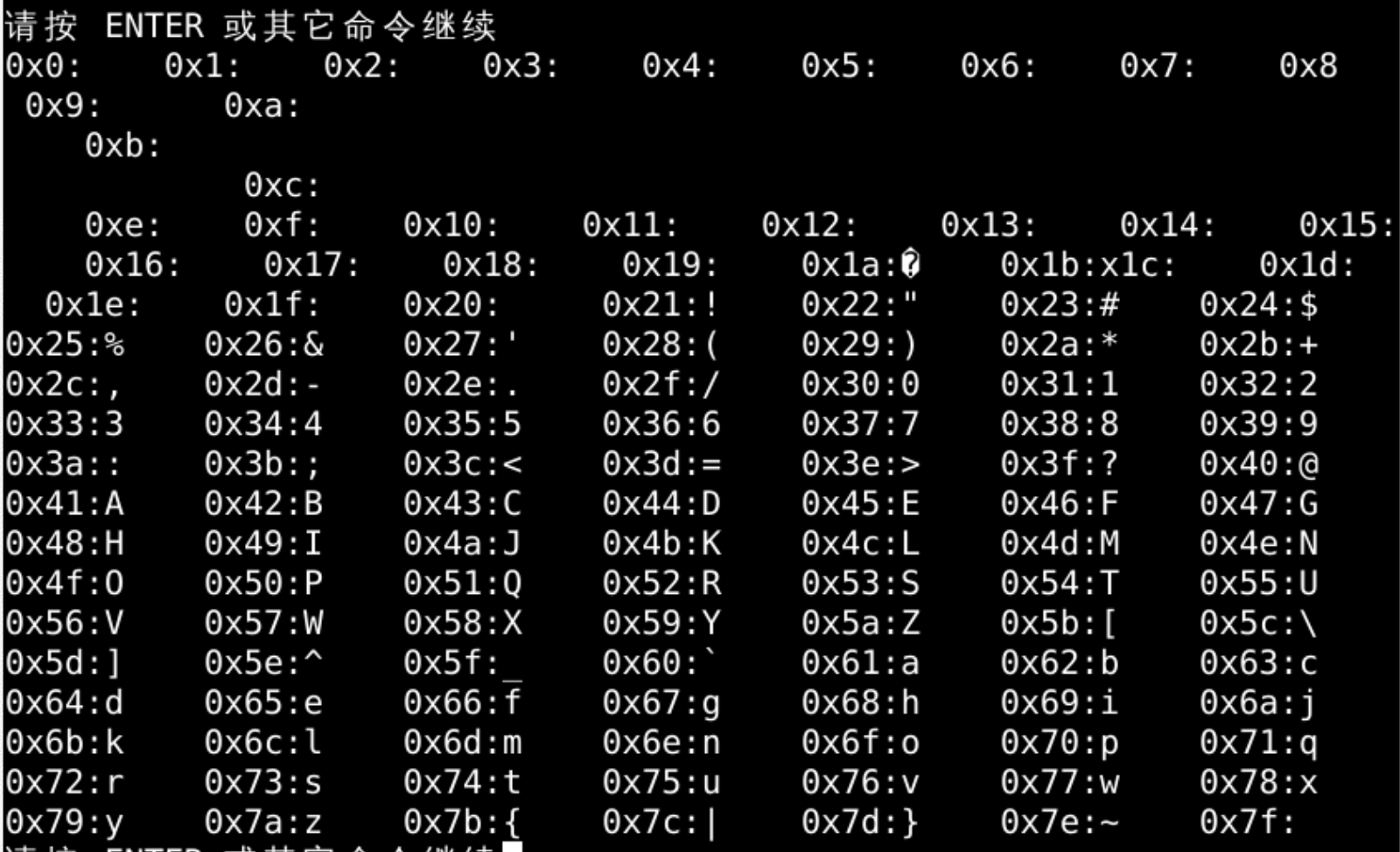
- 这不是很整齐啊
- 为什么在 0xa-0xc 好像换行很突然
- 后面可以看到字符和序号一一对应的关系
- 不过不是很明确
- 有什么方式可以看起来更明确么?
安装 ASCII
sudo apt install ascii
- Dec 对应的是 10 进制数
- Hex 对应的是 16 进制数
- 后面的是具体字符
-
字符包括
- 控制
- 符号
- 英文大小写字母
- 这样就把各种字符和一个二进制数字对应起来了

- 这个 ASCII 什么时候开始有的呢?
ASCII 码表
-
1967 年的时候就有了最初这个 ASCII 码表🔡
-
当时计算机用高电平和低电平分别表示 0 和 1
- 实际上计算机中所有的数据都是 0 和 1
- 这建立起了
字符和二进制数的映射关系
-
-
字符和二进制数的映射关系如果不一致- 面对同一个二进制数 01010101
- 就会映射到不同的字符
- 人们看到不同的字符就认为是乱码
-
当时美国的工程师定义了一套编码规则
-
ASCIIAmericanStandardCode forInformationInterchange
- 美国信息交换标准代码
-
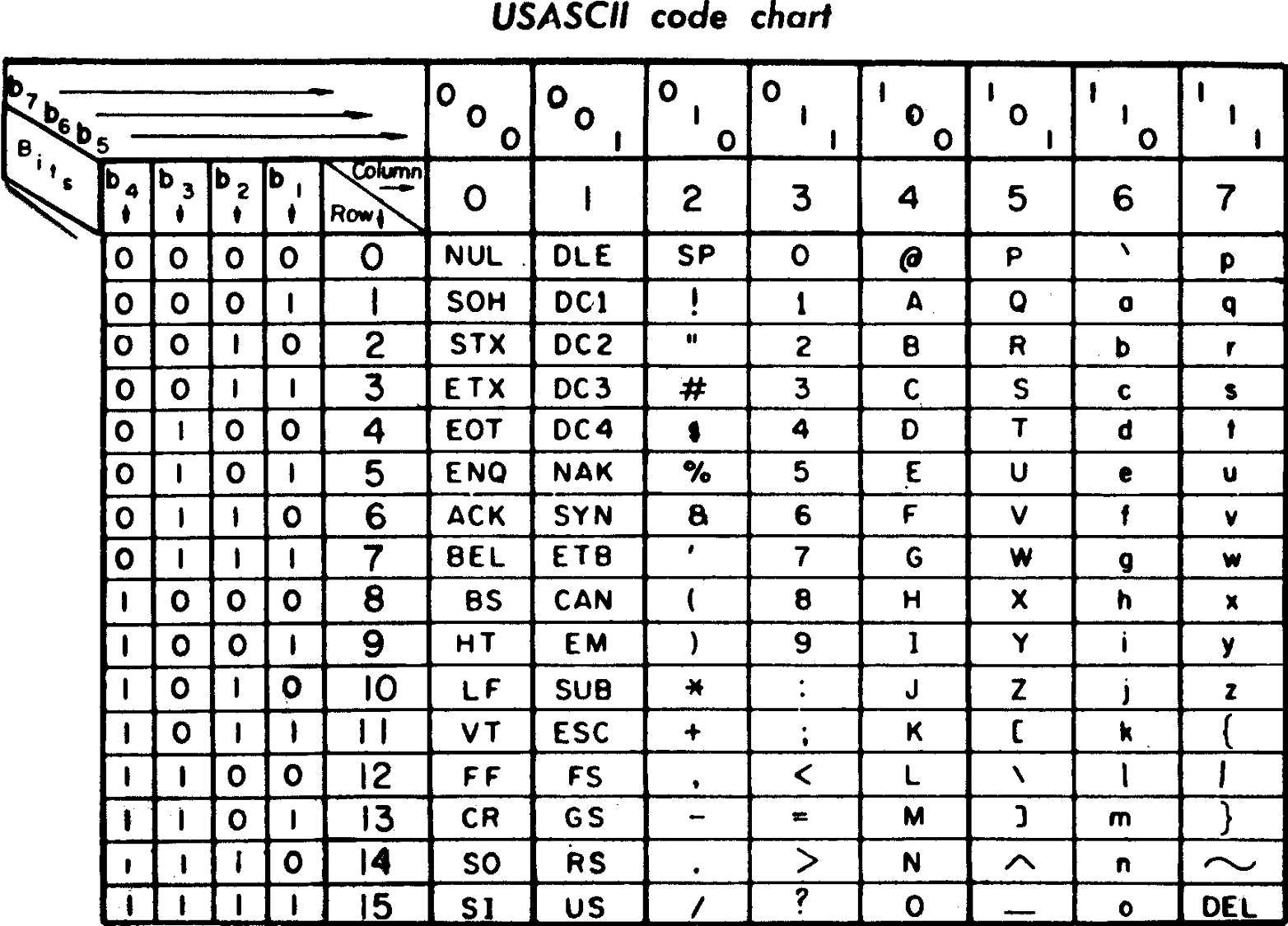
由来
-
这标准是美国信息交换标准代码是由美国国家标准学会制定的
- (American National Standard Institute , ANSI )
- 最初是美国标准
-
后来是国际标准化组织定为国际标准
- (International Organization for Standardization, ISO)
- 称为 ISO 646 标准
-
最后一次更新则是在 1986 年
- 到目前为止共定义了 128 个字符
解码 ASCII
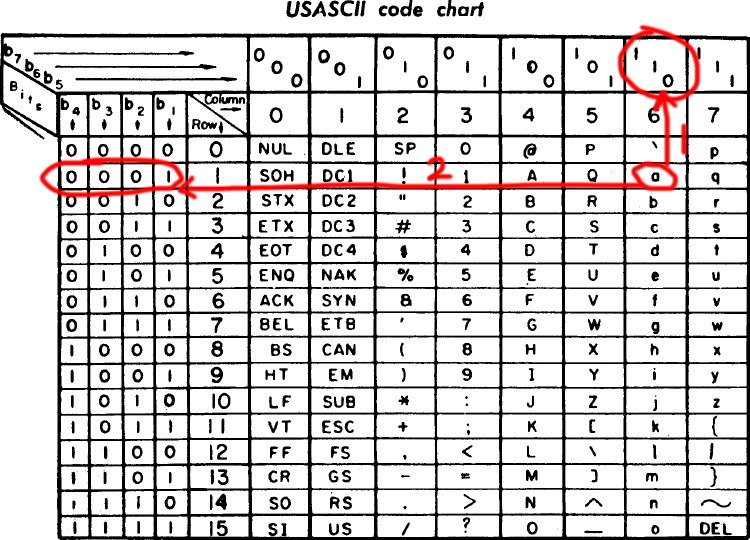
-
我们找到小写的
a-
先向上找到
110- 这是他的
765位 - 高三位
- 这是他的
-
再向左找到
0001- 这是他的
4321位 - 第四位
- 这是他的
- 在前面加一个
0 - 得到(
01100001)2进制 - 对应着(
97)10进制数 - 也就是(
0x61)16进制数 - 刚好对应一个字节
-
对应关系
-
1 个 字节 byte
- 正好 8 个 bit 位
- 相当于 2 位 16 进制数
- 16 进制数 更容易读出
- 十六进制数很适合输出字节状态
- 听起来找到了字符和字节状态之间的映射对应关系
- 我们能在游乐场上验证一下吗?
游乐场
- 进入 python3 帮助模式
-
我们可以查询 hex
- hex 对应 hexadicimal 十六进制
- help(hex)
动手
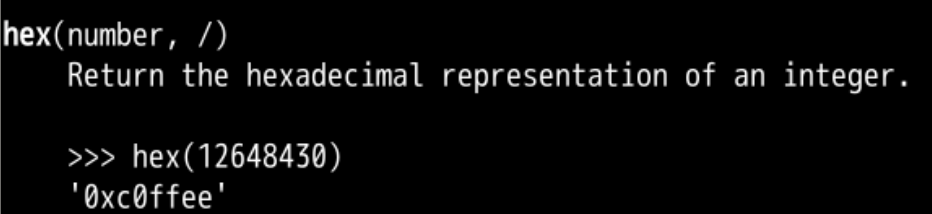
#得到a的序号
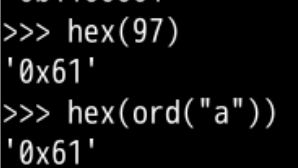
ord("a")
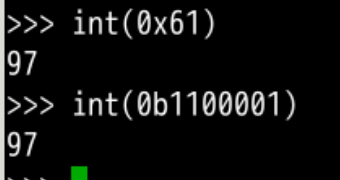
#输出97对应的16进制形式
hex(97)
#找到a对应的16进制形式数字对应的字符
hex(ord("a"))
-
0x61就是十六进制的610x是十六进制的前缀标志
- 可是为什么 16 进制使用
0x作为前缀?
0x 前缀
-
x 的起源
- 0x 的 x 是取自 hex 的 x

-
0 的起源
- 变量名开头不许是数字
- 0 开头肯定是数字
- 但正常情况下写数字不会用 0 开头
- 这保证 0 开头很容易和 10 进制区分开
-
在 C 语言之前的 B 语言用 0 开头表示 8 进制
-
C 语言继承了类似设定
- 0 开头表示数字
- 0x 开头表示 16 进制数
-
-
python 也继续继承
- 字符对应着数字
- 数字也可以转化为字符
-
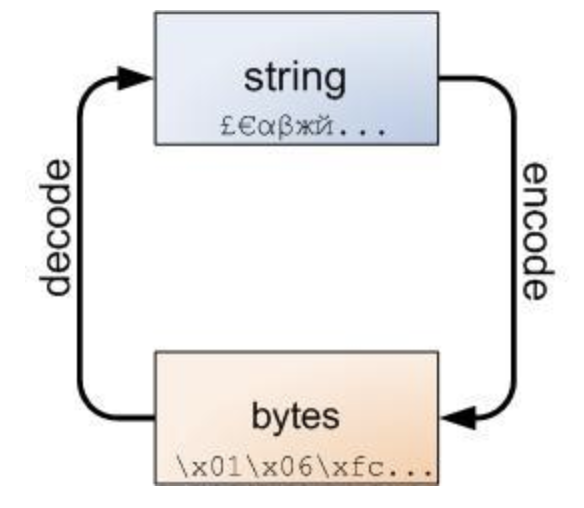
字符和二进制数之间的关系其实是
- 编码 encode
- 解码 decode
编码解码
-
编码
- 就是用预先规定的方法将文字、数字、其它对象编成数码
- 将信息、数据转换成规定的电脉冲信号
- 简单来说就是给大白菜编个号

-
解码是编码的逆过程
- 用特定方法,把数码还原成它所代表的内容
- 将电脉冲信号、光信号、无线电波等转换成它所代表的信息、数据等的过程
- 简单说就是扫条码知道这个是一个大白菜并知道价格等

- 我们用python试试编码解码
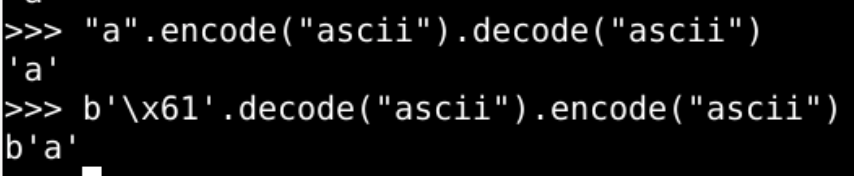
encode和decode
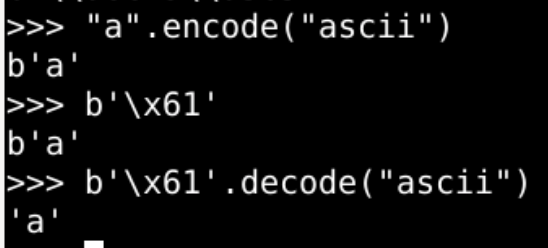
- str(字符串)
'a'encode(编码)之后 为 bytes(字节序列)b'\x61'
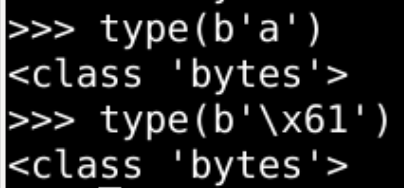
- bytes(字节序列)
b'\x61'decode(解码)之后为 为 str(字符串)'a' - 编码(encode) 和解码(decode) 互为逆运算
-
很像
- 字符(chr)和 序号(ord)
编码解码
- 可以先编码再解码
- 也可以先解码再编码
- 绕来绕去
- 也没做神马😁
- 掌握这个基础是最起码
- 基本功要练得硬桥硬马
- 实战方能稳扎稳打
- 否则以后各种乱码
- 字节除了用十六进制显示之外
- 还可以用二进制显示么?
bin(number)
- 这次我们来试试把数字转化为二进制形式
-
查询 bin
- bin 对应 binary 二进制


动手
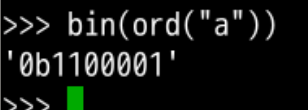
#得到a的序号
ord("a")
#输出97对应的16进制形式
bin(97)
#找到a对应的十六进制形式
bin(ord("a"))
0b1100001是二进制数1100001-
0b是 2 进制数的前缀标志- 正如
0x是 16 进制数的前缀标志
- 正如
和 ASCII 表对比
- 验证成功
- 这充分证明了我们用的确实是 ASCII 表!!!👏👏
- 废话!🦧
- 我们会用 hex、bin 把 10 进制数转化为八进制、二进制形式
- 能把其他进制转化回十进制么?
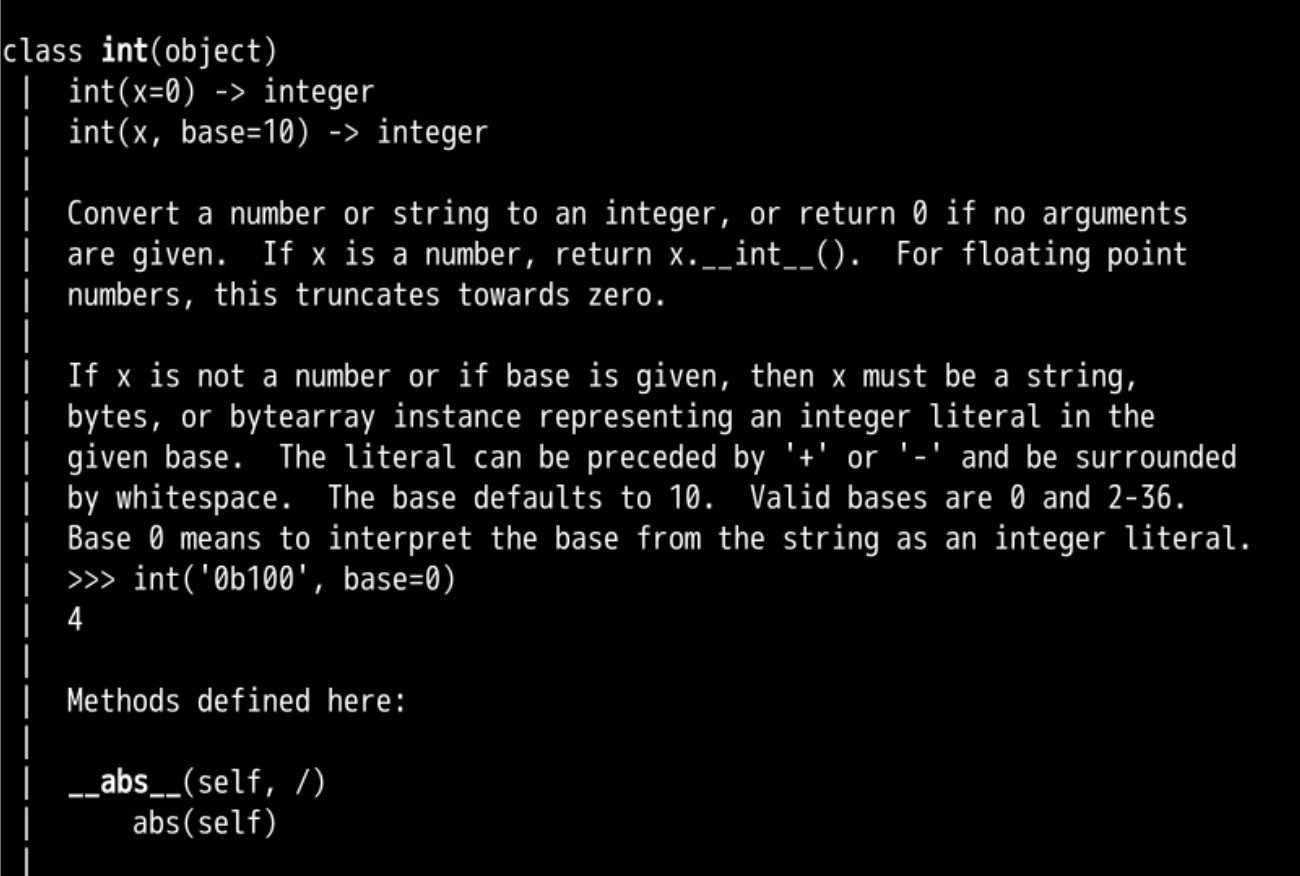
其他进制 转化为回 10进制 int(number)
- 用的是 int
- 这个 int 什么来历?
- 我们 help()里面去找找
大小字母差值
0x41-0x5A这个范围是大写字母0x61-0x7A这个范围是小写字母
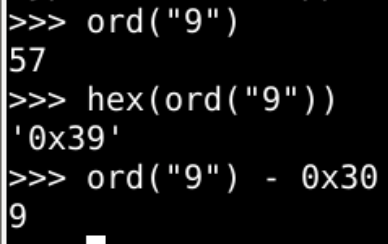
#输出a的ASCII吗
ord("a")
#输出A的ASCII吗
ord("A")
#输出大小写之差
ord("a")-ord("A")
#差值的16进制形式
hex(ord("a")-ord("A"))
#差值的2进制形式
bin(ord("a")-ord("A"))
- 大写字母和小写字母相差(
32)10进制 - 正好是(
0x20)16进制
- 为什么不多不少
- 就差 0x20 呢?
- 怎么那么寸呢?🤔
ASCII 码表趣事
-
其实最初不是相差 0x20
- 这个 0x20 正好是一个二进制位
- 对应 b6 这个位
- 之前 ibm 的 EBCDIC 编码并不是这样的
- 那为什么要改成这样子呢?
-
有了这种对应关系之后
- 做大小写不敏感的字符串查找就快多了
-
这个 0x20 发生在 1963 年 5 月
- The X3.2.4 task group voted its approval for the change to ASCII at its May 1963 meeting.
- Locating the lowercase letters in columns 6 and 7 caused the characters to differ in bit pattern from the upper case by a single bit, which simplified case-insensitive character matching and the construction of keyboards and printers.
-
如果是大写字母
- 修改1位之后,都变成小写字母
- 然后直接查找就好了
ASCII 码表范围
0x41-0x5A这个范围是大写字母0x61-0x7A这个范围是小写字母-
0x30-0x39这个范围是数字- 数字的编码减去
0x30正好得到数字本身
- 数字的编码减去
- 我们再来看看 ASCII
ASCII
0x20-0x7F之间有各种符号-
0x00-0x1F之间的东西是什么?- 目前还不知道
- 也许有一天可以进行进一步地探索
-
可以肯定都是
- 很多字符来自与更早之前的摩斯电码
更早之前的摩斯电码
-
ASCII 也不是从无到有的
- 在 ASCII 之前就有摩斯电码
- 也是一种编码方法
- 《oeasy 教您玩转电路基础》第 18 话介绍过
-
下图是他的编码表
- 分成长和短两种信号,就是嘀和嗒

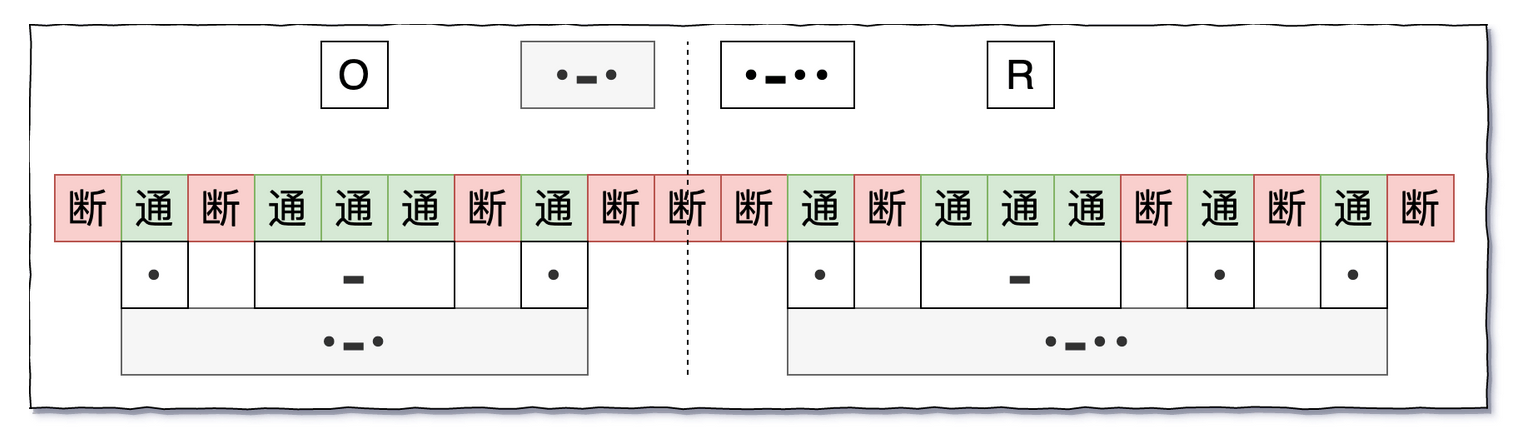
摩斯电码通信规则
- 下图是他的通信规则
- 三个断确认本字符结束了
- 三个断也就是字符之间的分隔符
- 录入状态并不是 0、1 两种状态
- 而是长、短、暂停三种状态
- 为什么这样编码呢?
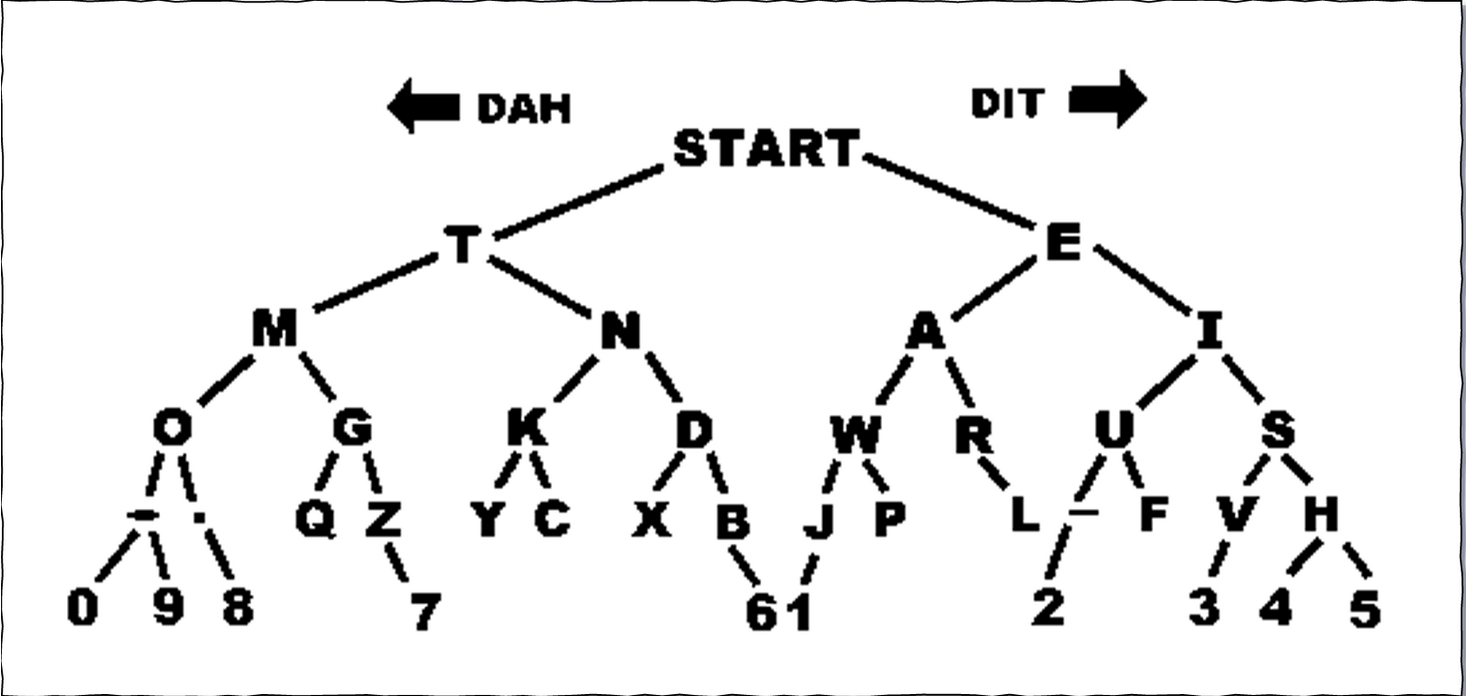
效率问题
-
编码的规则是常用的字符点击次数少
-
按照字符出现概率分配对应点击数量
T、E出现频率最高- 所以用一次点击电键的数量
- 本质上是一棵霍夫曼树
-
-
当时完全由人进行发射和接收
- 每个人发送数据的速度是不固定的
- 每个人接收数据的速度取决于发送人的发送速度
- 现查表是来不及的
- 需要熟悉编码表和常用缩写
-
这就是早期使用电来进行编码的过程
- 我们现在回到 ASCII 码
- 最后我们来总结一下
总结
-
数制可以转化
- bin(n)可以把数字转化为
2进制 - hex(n)可以把数字转化为
16进制 - int(n)可以把数字转化为
10进制
- bin(n)可以把数字转化为
-
编码和解码可以转化
- encode 编码
- decode 解码
-
ASCII 码表范围
0x41-0x5A这个范围是大写字母0x61-0x7A这个范围是小写字母-
0x30-0x39这个范围是数字- 数字的编码减去
0x30正好得到数字本身
- 数字的编码减去
0x20-0x7F之间有各种符号0x00-0x1F之间的东西是什么?🤔
- 我们下次再说

 浙公网安备 33010602011771号
浙公网安备 33010602011771号