
Odoo 11 Backend
Table of Contents
命令入口
odoo-bin 脚本
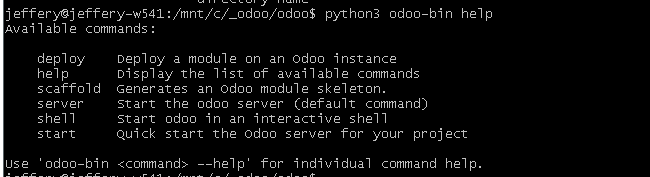
支持的子命令
help
deploy
scaffold
server
shell
start
子命令注册
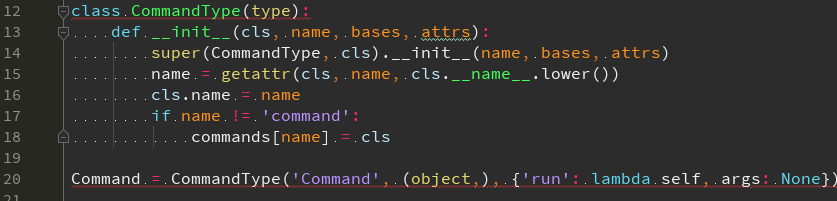
command 基类, 往 commands 注册 支持的子命令, 等定义 接口 run()…. 每个子命令必须实现它
服务器
运行 子命令 server ,
检查运行用户、pg用户、读取配置、显示主要配置
启动server

加载 全局 addons… load_server_wide_modules() #L864 service\server.py
此时 initialize_sys_path() , 并 import odoo模块, 名称空间为 'odoo.addons.'+module_name
# 默认全局加载的模块为 web
根据 配置 运行 具体模式server 的 run(preload, stop) 方法 ; 支持以下集中模式
- 多线程 --> ThreadedServer
- 多进程 --> PreforkServer
- gevent --> GeventServer
运行 server 时, 根据配置 确定server ,然后将 wsgi应用 传递给 它, 也就是将 self.app 指定为 wsgi 应用 odoo.service.wsgi_server.application
, 以便在启动http server后,以此wsgi 应用来响应请求
thread 模式
对于 Thread 模式, 通过 run 入口 调用 http_spawn() 以线程模式启动 wsgi服务器

以 werkzeug.serving.ThreadedWSGIServer 模式 启动 wsgi application
prefork 模式
对于 Prefork 模式, 通过 run 入口 调用 worker_spawn() 依次调用对应的 worker,
http worker --> WorkerHTTP
cron worker --> WorkerCron
long_polling 进程
在 worker_spawn 初始化 对应的 worker 后 调用 run() 启动它
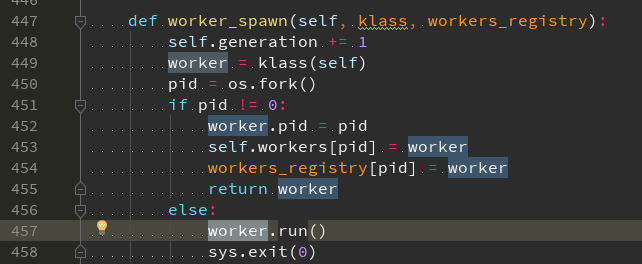
对于 http worker ,,, 则 调用WorkerHTTP,self.workers_http), 启动 BaseWSGIServerNoBind(self.multi.app)
使用 werkzeug 启动 wsgi 服务器werkzeug.serving.BaseWSGIServer.__init__(self,"127.0.0.1",0,app)
gevent模式
对于 gevent 模式, 以 gevent.wsgi 方式启动 服务器

说明: gevent模式专用于 longpooling
wsgi 应用
封装了2个 wsgi 处理器
- xmlrpc
- http root # 也就是在 http.py 里面定义的 class Root
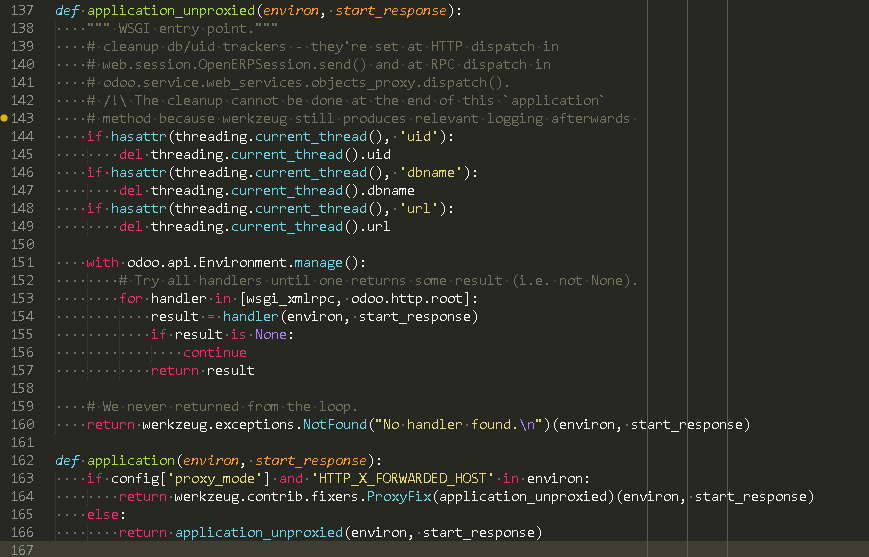
响应客户端请求
当对 http server发起请求时, http server将请求转发给 wsgi应用
当wsgi 接收到 请求时, 尝试调用所有支持的 wsgi 处理器[handler]对请求进行处理,
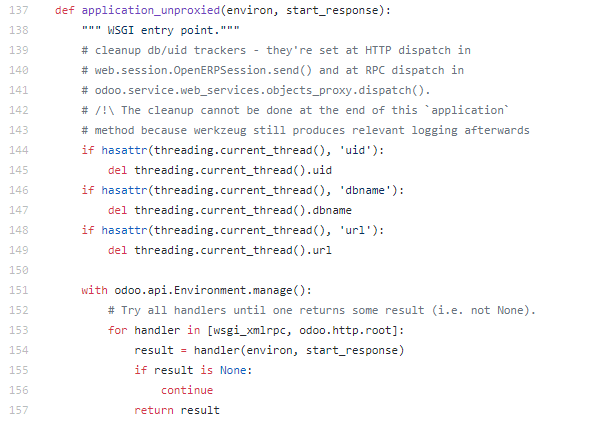
调用的先后顺序为
wsgi_xmlrpc(environ,start_response)
odoo.http.root(environ,start_response)
如果handler处理不了,则返回 "No handler found." 错误
xmlrpc
调用 xmlrpc 处理器 #L102 wsgi_xmlrpc wsgi_server.py
验证xmlrpc 调用请求,取出 xmlrpc 调用的服务,方法,以及参数, 传递给 odoo.http.dispatch_rpc(service,method,params),返回 最终 dispath() 方法
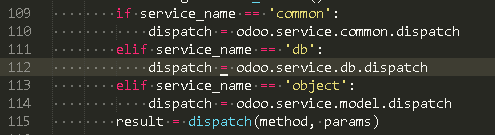
各个服务将调用相应的模块的dispatch() 方法来 分发 远程调用
- common --> odoo.service.common
- db --> odoo.service.db
- object --> odoo.service.model
每个服务都实现了 dispatch 方法
web
odoo web 将 http请求分为2种
- jsonrequest
- httprequest
它们都继承webreqeust
http.root # odoo/http.py#L1294
http Root() 初始初始化,并 将请求通过 dispatch() 进行分发
先判断是否 第一次加载 addons, 如是, 则 加载 模块 ,并使用 静态文件 处理器的 dispatch 方法 分发请求
如果不是 第一次加载 addons, 则调用 root 的 dispatch() 方法 分发请求

加载 模块,目的是 加载所有包含了 静态文件 和 controller的 odoo addons

对于静态文件的addons, 则将 使用 disablecachemiddleware 对 wsgi 应用 进行 处理
对于其他的,则使用 root 的 dispatch 方法, 根据 请求的不同情形 进行分发
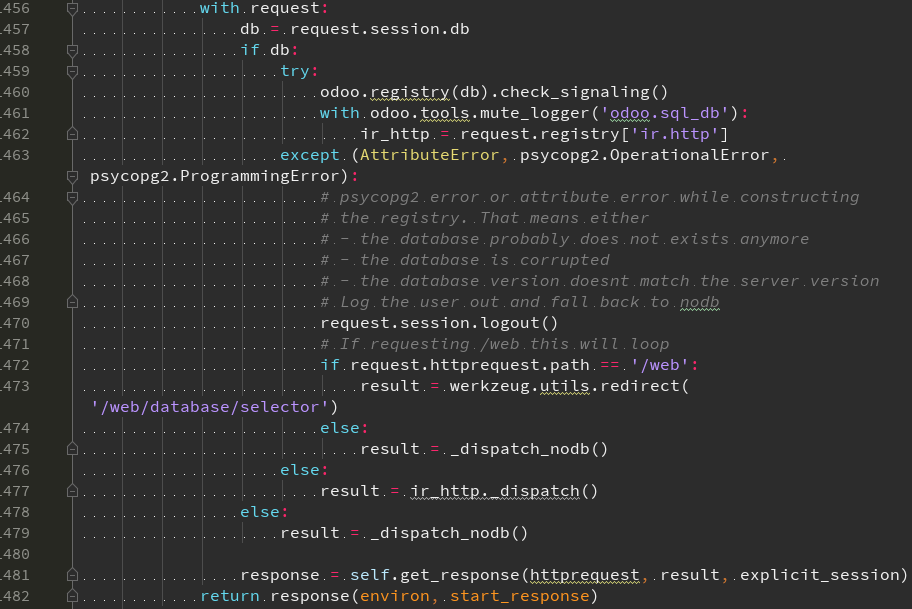
可能的情形
- http请求不包含 db 时, 分发到创建数据库
-
http请求包含 db 时, 检查注册表信号【如果注册表还没有 ready, 则先 准备好注册表】
- 如果在检查注册表信号,或者调取ir_http 出现异常, 则 分发到创建数据库 或则 选择数据库
- 然后通过注册表获取 ir_http 对象,将请求交给 ir_http dispatch 进行路由选择, 然后交给相应的 http Endpoint 进行处理
同时,在做实际的dispatch() 之前,先对 web request 进行识别, 判断到底是 jsonrequest 还是 httpreqeust
根据请求数据 判别 request 类型, 然后用 对应的 request 方式进行数据处理

http路由处理
ir_http dispatch 通过 _find_handler() 调用 ir.http 类方法 routing_map()获取 路由表 # L227 ir_http.py
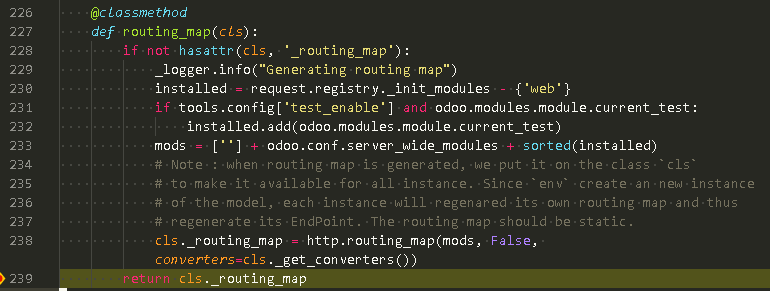
根据已经 安装的 模块, 经由 http.routing_map() 得到 route map.
例如,
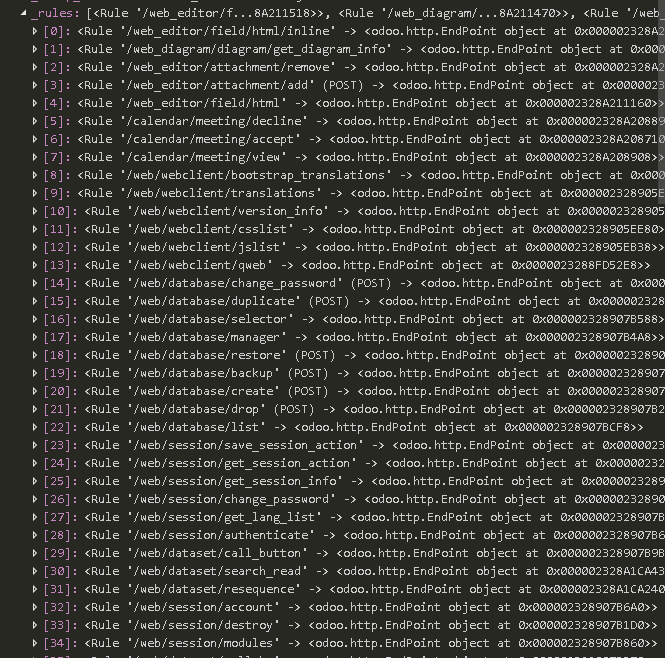
根据 route_map 选择 对应的 endpoint 处理 web 请求
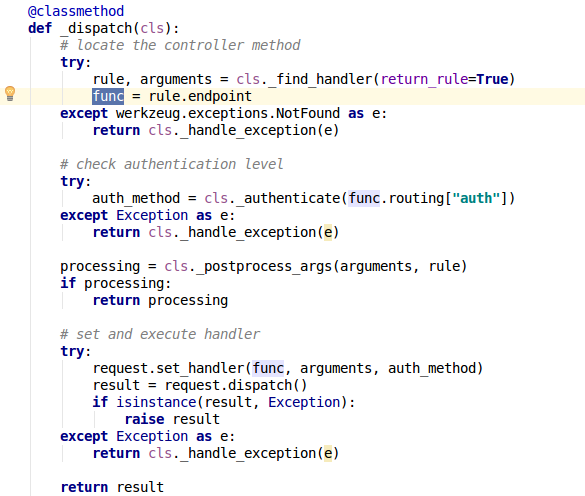
调用 web 请求的 dispatch() 方法 对请求进行处理, 而相应的 request 最终会 调用
父类 Request 方法 _call_function() 调用 endpoint 处理 request…
HTTP request
如果是 http 类型, 调用 HttpRequest.dispatch() 处理
使用 对应的 endpoint 处理 reqeust.. 并返回结果
JSON request
如果是 http 类型, 调用 JsonRequest.dispatch() 处理
对应的endpoint 处理 请求, 返回结果 经 _json_response 处理为 jsonrpc 返回数据规范
路由注册
在加载odoo addons的时候,如果是controller 会往 controllers_per_module{} 注册 控制器类, 注册内容是
{ 模块:[ (模块名.类名, 类)] }
例如
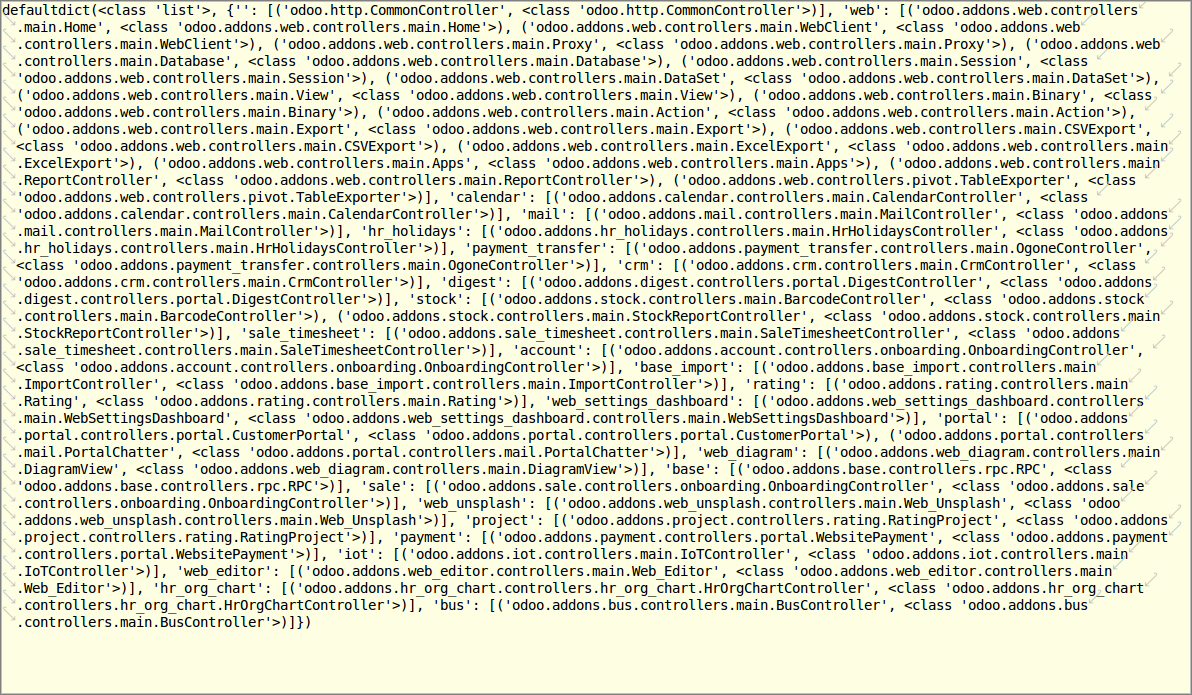
生成路由表时, 从 注册表读出已安装的模块, 然后从上面数据读出控制器类,并读出 方法的 routing 属性
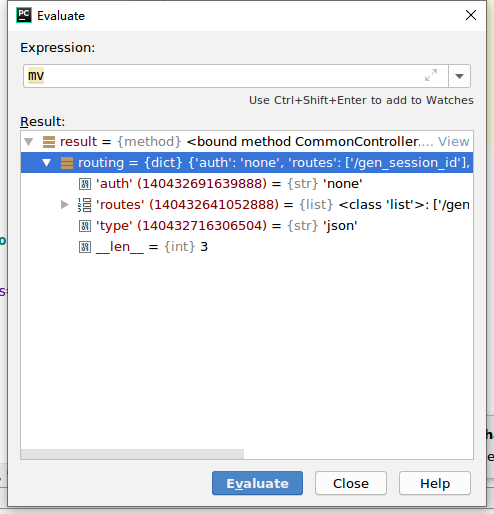
routing属性,是在往 控制器方法修饰 route 时, 注入进去的
注册表
registry , 每个数据库 一个 注册表, 在 每个 odoo实例 的 registry 对象 的 registries 属性记录 全部的 注册表
主要 方法
|
load() |
加载 模型, 构建 model class |
|
setup_models() |
设置 base , 设置 字段, 设置 计算字段 |
|
init_models() |
初始模型,调用 model 的 auto_init() 和 init( ) 操作数据库, 建立 数据库表 , 增加字段 字段 , 增加 约束 /// 在此 实现 MPTT 【 预排序遍历树 】 // 提示, 可以在model 定制 init() 改变 数据库初始化逻辑 |
注册表创建或更新
wsgi 应用 Dispatch 请求时, dispatch 逻辑里,在检查注册表时, 先尝试 获取 注册表, 然后检查 "信号" # odoo/odoo/http.py:1445

注册表获取 # odoo/odoo/__init__.py:76

根据db 创建 注册表, 加载 模块 # odoo/odoo/modules/registry.py:61
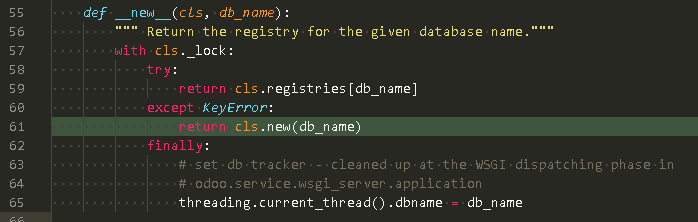
加载 模块 # odoo/odoo/modules/registry.py:85
模块
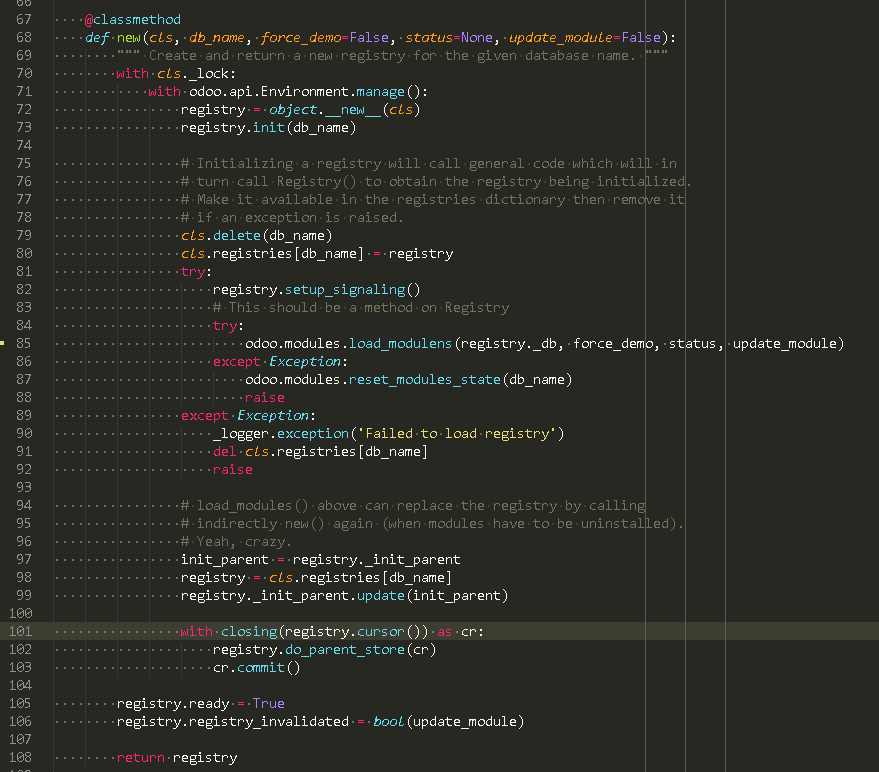
模块信息
load_information_from_description_file()
迁移钩子 migration hook
在 安装/升级 模块时, 执行 migrations
Migrations 定义:
This class manage the migration of modules
Migrations files must be python files containing a `migrate(cr, installed_version)`
function. Theses files must respect a directory tree structure: A 'migrations' folder
which containt a folder by version. Version can be 'module' version or 'server.module'
version (in this case, the files will only be processed by this version of the server).
Python file names must start by `pre` or `post` and will be executed, respectively,
before and after the module initialisation. `end` scripts are run after all modules have
been updated.
Example:
<moduledir>
`-- migrations === 目录名必须
|-- 1.0 === 版本号, odoo服务版本号,或者模块版本号
| |-- pre-update_table_x.py === 升级前执行脚本
| |-- pre-update_table_y.py
| |-- post-create_plop_records.py === 升级后执行脚本
| |-- end-cleanup.py === 最终执行脚本
| `-- README.txt # not processed
|-- 9.0.1.1 # processed only on a 9.0 server
| |-- pre-delete_table_z.py
| `-- post-clean-data.py
`-- foo.py # not processed
当 迁移脚本的 版本 处于 已安装的版本, 和当前版本直接时, 才 会执行
if parsed_installed_version < parse_version(convert_version(version)) <= current_version:
模块依赖关系图
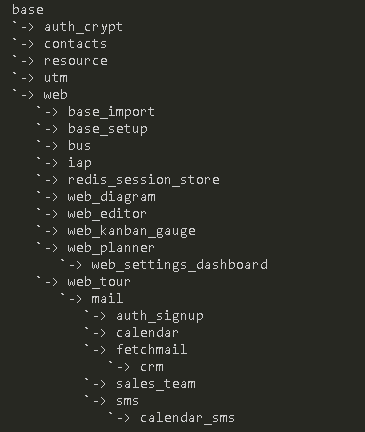
模块安装/升级/卸载
代码 odoo/odoo/modules/loading.py
背景知识点: python 环境 sys.modules
- 调用 initialize_sys_path() 引入 odoo 模块, 加入到 sys.modules
- 如果数据库还没建立,初始化数据库, 对应的SQL 文件 odoo/odoo/addons/base/base.sql
- 获取 注册表
- 初始化 模块依赖关系图
-
按 模块依赖关系图, 运行以下逻辑 load_module_graph()
- 运行预迁移脚本
- 加载 odoo模块,如果 模块指定了 post_load 运行它 # load_openerp_module()
- 对于新安装模块, 运行模块指定的 pre_init_hook
- 往注册表加载 模块
- 对于新安装/升级的模块, 通过注册表 设置模型 setup_models(), 初始化模型 init_models()
- 对于新安装/升级的模块, 加载 数据 以及 演示数据
- 运行迁移后脚本
- 如果在config 设置了overwrite_existing_translations,则更新翻译,
- 验证 视图
- 对于新安装模块, 运行模块指定的 post_init_hook
- 计算 依赖模块, 再次 按 模块依赖关系图 运行 模块安装/升级 逻辑
- 运行最终迁移脚本
- 完成安装并清理
- 如果是 卸载模块, 执行 卸载,并重置 注册表 // 卸载时,从数据库表 ir_model_data 删除相关数据, 将模块标记为 uninstalled
- 验证 自定义视图
- 运行 模型注册钩子 _register_hook()
load_openerp_module 处理 odoo 名称 空间
odoo.addons.[addons_name].models.[model_name]
别名
openerp.addons. *
# 注意
此外,在引入 odoo模块的时候,通过 MetaModel 将 addons 登记 module_to_models, 以便 注册表 在 load 模型时, 构建 model.
模块登记
在 模块加载 逻辑的 第二步, 更新 数据库表 ir_module_module 往里面 登记 需要 加载的模块
模型初始化
往注册表 加载 模块时, 调用 model 的 build_model()方法 建立 模型 # L233 load() registry.py
def load(self, cr, module):
""" Load a given module in the registry, and return the names of the
modified models.
At the Python level, the modules are already loaded, but not yet on a
per-registry level. This method populates a registry with the given
modules, i.e. it instanciates all the classes of a the given module
and registers them in the registry.
"""
from .. import models
lazy_property.reset_all(self)
# Instantiate registered classes (via the MetaModel automatic discovery
# or via explicit constructor call), and add them to the pool.
model_names = []
for cls in models.MetaModel.module_to_models.get(module.name, []):
# models register themselves in self.models
model = cls._build_model(self, cr)
model_names.append(model._name)
return self.descendants(model_names, '_inherit', '_inherits')
根据 addons depends 以及 _inherit 来决定 model 继承
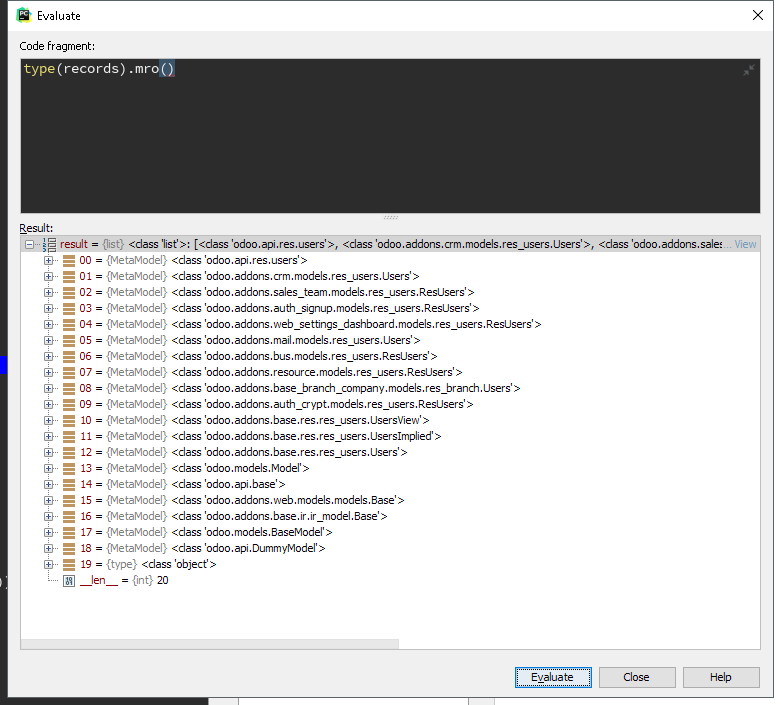
例如 , 通过 type(env['res.users']).mro() 查看 继承 顺序, 调用 supper() 时, 调用父级的先后顺序
env['res.users'] 为 空记录集
type(env['res.users']) 得到 记录集对应的模型, 类型 [ class ]
例如, res.users 模型
模块数据加载
在 模块 加载时, 通过 _load_data() 调用 tools.convert_file() 将 data file 导入到 db
tools.convert_file(cr, module_name, filename, idref, mode, noupdate, kind, report)
convert_file()
def convert_file(cr, module, filename, idref, mode='update', noupdate=False, kind=None, report=None, pathname=None):
if pathname is None:
pathname = os.path.join(module, filename)
ext = os.path.splitext(filename)[1].lower()
with file_open(pathname, 'rb') as fp:
if ext == '.csv':
convert_csv_import(cr, module, pathname, fp.read(), idref, mode, noupdate)
elif ext == '.sql':
convert_sql_import(cr, fp)
elif ext == '.yml':
convert_yaml_import(cr, module, fp, kind, idref, mode, noupdate, report)
elif ext == '.xml':
convert_xml_import(cr, module, fp, idref, mode, noupdate, report)
elif ext == '.js':
pass # .js files are valid but ignored here.
else:
raise ValueError("Can't load unknown file type %s.", filename)
记录集
实例化一个 model..
records=object.__new__(cls)
然后 给它的 属性 _ids 赋值
这样, 就可以 通过 __getitem__() 获取 字段数据, __setitem__() 设置 字段数据
记录集 操作
Recordsets are immutable, but sets of the same model can be combined using various set operations, returning new recordsets. Set operations do not preserve order.
- record in set returns whether record (which must be a 1-element recordset) is present in set. record not in set is the inverse operation # __contains__()
- set1 <= set2 and set1 < set2 return whether set1 is a subset of set2 (resp. strict) # __le__()
- set1 >= set2 and set1 > set2 return whether set1 is a superset of set2 (resp. strict)# __ge__()
- set1 | set2 returns the union of the two recordsets, a new recordset containing all records present in either source# __or__()
- set1 & set2 returns the intersection of two recordsets, a new recordset containing only records present in both sources# __and__()
- set1 - set2 returns a new recordset containing only records of set1 which are notin set2 # __sub__()
数据读写
_read_from_database()
调用 cursor 执行 数据库 读取, 同时 更新 record cache.
# store result in cache
for vals in result:
record = self.browse(vals.pop('id'), self._prefetch)
record._cache.update(record._convert_to_cache(vals, validate=False))
read()
create()
write()
unlink()
约束
模型的 _constraints 属性和 _sql_constraints 属性
其中 _constraints 已废弃,改用 @api. Constraints()
SQL 约束
(name, sql_definition, message)
模型初始化 db 时,往 db 建立约束, _add_sql_constraints () #L2175 model.py
Python 约束
通过 _validate_fields() 验证 #L933 model.py /// create() 和 write() 时调用。
通过返回 true, 否则返回异常
detailed,,,
_constraints
list of (constraint_function, message, fields) defining Python constraints. The fields list is indicative
Deprecated since version 8.0: use constrains()
_sql_constraints
list of (name, sql_definition, message) triples defining SQL constraints to execute when generating the backing table
默认值
模型 defaults 属性
通过上下文默认值,用户默认值, 模型默认值[ 字段默认值,父级默认值] 进行维护
上下文默认值
default_ 开头, 加上 字段
用户默认值
self.env['ir.default'].get_model_defaults(self._name)
模型默认值
字段默认值
field.default
父级字段默认值
if field and field.inherited:
field = field.related_field
parent_fields[field.model_name].append(field.name)
具体 逻辑

default_get() #L974 model.py
实践用法:
改写 default_get() 改变默认值
视图和字段
Web client 通过 rpc 调用 load_views 得到视图定义
@api.model
def load_views(self, views, options=None):
""" Returns the fields_views of given views, along with the fields of
the current model, and optionally its filters for the given action.
:param views: list of [view_id, view_type]
:param options['toolbar']: True to include contextual actions when loading fields_views
:param options['load_filters']: True to return the model's filters
:param options['action_id']: id of the action to get the filters
:return: dictionary with fields_views, fields and optionally filters
"""
options = options or {}
result = {}
toolbar = options.get('toolbar')
result['fields_views'] = {
v_type: self.fields_view_get(v_id, v_type if v_type != 'list' else 'tree',
toolbar=toolbar if v_type != 'search' else False)
for [v_id, v_type] in views
}
result['fields'] = self.fields_get()
if options.get('load_filters'):
result['filters'] = self.env['ir.filters'].get_filters(self._name, options.get('action_id'))
return result
底层 2个 方法:
fields_view_get 获取视图定义

fields_get 获取字段定义

权限
ACL 记录在 ir.model.access
Record rule 记录在 ir.rule

对于 admin ,,, user_id =1 旁路
if self._uid == 1:
# User root have all accesses
return True

对于 admin ,,, user_id =1 旁路
if self._uid == SUPERUSER_ID:
return

在 增create() 删 unlink() 改 write() 查 search() 时, 调用 check_access_rights() 以及 check_access_rule() 检查是否有权限
视图之权限处理
调用 _apply_group() 将 无权限访问的 node 去除
对于 field 设置了 权限的, 将 字段设置为 readonly
服务
wsgi 应用
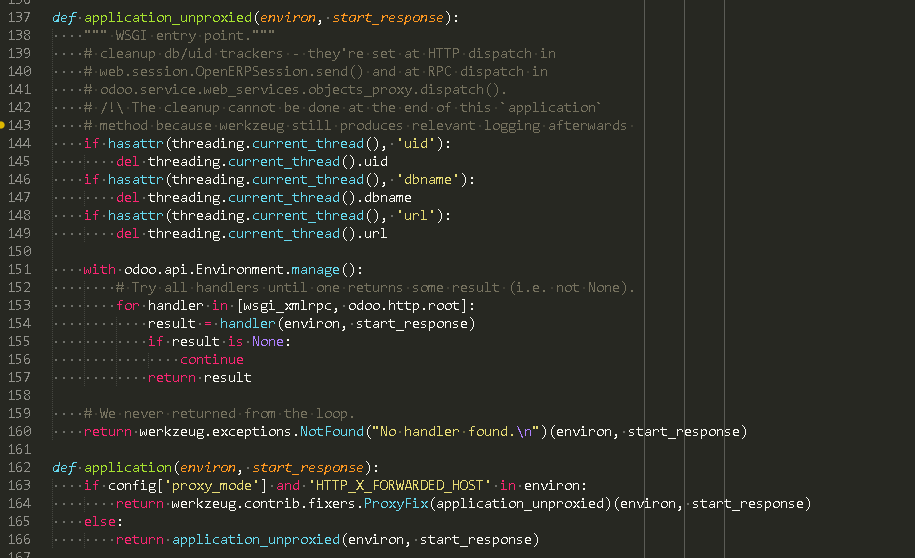
导出 xmlrpc 和 http 服务
WSGI application 被 server 使用
XML RPC 服务
http.py dispatch_rpc()
根据不同的名称空间,转发给对应的 handler
Web服务
http.py Root.dispatch()
# 通过 Root 类 的 __call__() 调用 dispatch()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号