【Anchor-based and Anchor-free 性能差距的本质是训练时候的正负样本分配策略】Adaptive Training Sample Selection (ATSS) 论文精读
原始题目:Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
中文翻译:通过 自适应训练样本选择 缩小 Anchor-based and Anchor-free Detection 之间的差距
发表时间:2019年12月5日
平台:arxiv
来源: 中国科学院自动化研究所-模式识别与智能系统实验室
文章链接:https://arxiv.org/abs/1912.02424
开源代码:https://github.com/sfzhang15/ATSS
摘要
In this paper, we first point out that the essential difference between anchor-based and anchor-free detection is actually how to define positive and negative training samples, which leads to the performance gap between them.
If they adopt the same definition of positive and negative samples during training, there is no obvious difference in the final performance, no matter regressing from a box or a point.
how to select positive and negative training samples is important for current object detectors.
propose an Adaptive Training Sample Selection (ATSS) to automatically select positive and negative samples according to statistical characteristics of object.
本文主要贡献是什么?
摘要是引言的概括。本文指出所谓 anchor-free detectors 的性能比 anchor-based detectors 差的原因是:选择正负训练样本的方法不同。从一个 box 回归还是一个 point 回归并没有什么不同。还有在一个 位置 平铺多个 anchors 并没有什么用。
所以本文的核心在于 怎么选择训练时候的正负样本。提出了新的方法:Adaptive Training Sample Selection (ATSS)
1. Introduction
目标检测任务哪种方法是主导?anchor-based detectors 有哪两种?
anchor-based detectors 主导。
- one-stage methods
- two-stage methods
anchor-based detectors 是怎么做的?
first tile a large number of preset anchors on the image, then predict the category and refine the coordinates of these anchors by one or several times, finally output these refined anchors as detection results.
为什么 anchor-based 的 两阶段方法对 一阶段方法有更高的精度?
Because two-stage methods refine anchors several times more than one-stage methods, the former one has more accurate results while the latter one has higher computational efficiency. (两阶段方法比一阶段方法细化的次数多)
最近,学术界为什么更关注 anchor-free detectors,anchor-free detectors 是什么?
由于 FPN and Focal Loss 的出现。 anchor-free detectors 是没有预设的 anchors,直接找到对象。
anchor-free detectors 有哪两种?
- keypoint-based methods:first locate several pre-defined or self-learned keypoints and then bound the spatial extent of objects.
- center-based methods: use the center point or region of objects to define positives and then predict the four distances from positives to the object boundary.
anchor-free detectors 的好处?
- 消除与 anchor 相关的超参数
- 达到 anchor-based 相似的性能
- 这二个好处使得 anchor free detectors 在泛化能力上更有潜力
两种 anchor-free detectors 有什么区别?哪个和 anchor-based 的方法更近?
keypoint-based methods follow the standard keypoint estimation pipeline that is different from anchor-based detectors.
center-based detectors are similar to anchorbased detectors, which treat points as preset samples instead of anchor boxes.
the one-stage anchor-based detector RetinaNet and the center-based anchor-free detector FCOS 有什么不同?
(1)The number of anchors tiled per location. RetinaNet tiles several anchor boxes per location, while FCOS tiles one anchor point1 per location.
(2)The definition of positive and negative samples. RetinaNet resorts to the Intersection over Union (IoU) for positives and negatives, while FCOS utilizes spatial and scale constraints to select samples.
(3)The regression starting status. RetinaNet regresses the object bounding box from the preset
anchor box, while FCOS locates the object from the anchor point.
RetinaNet 和 FCOS 两个性能好呢?
anchor-free FCOS 好于 anchor-based RetinaNe。
那么上述三个因素哪个导致其性能好呢?
实验表明(如果它们在训练过程中选择相同的正样本和负样本,无论从 a box 回归还是从 a point 回归,最终性能都没有明显的差距。),the definition of positive and negative training samples 导致了它们性能的差异。那么说明 因素1和因素3 不重要,也就是 tiling multiple anchors per location on the image to detect objects is not necessary.(目标检测在每个位置不需要多个 anchors)
How to select positive and negative training samples?
提出了 a new Adaptive Training Sample Selection (ATSS) to automatically select positive and negative samples based on object characteristics.
使用 Adaptive Training Sample Selection (ATSS) 达到了什么性能?
不引入任何开销下,the MS COCO:AP 50.7%。
本文有啥贡献?
- anchor-based and anchor-free detectors 的性能差异来自 怎么选择训练时候的正负样本
- ATSS 方法 according to statistical characteristics of object,选择训练时候的正负样本
- 一张图像的每个位置平铺多个 anchors 没用
- MS COCO 实现 SOTA.
2. Related Work
目标检测算法的分类有哪些?
CNN-based object detection:
- anchor-based
- two-stage
- one-stage
- anchor-free
- keypoint-based
- center-based
介绍下 Anchor-based 的 Two-stage 方法的 Faster R-CNN?
Faster R-CNN 算法主导 Two-stage 方法。它包含 a separate region proposal network (RPN) and a region-wise prediction network (R-CNN).
Faster R-CNN 后面有什么改进?
- architecture redesign and reform
- context and attention mechanism
- multiscale training and testing
- training strategy and loss function
- feature fusion and enhancement
- better proposal and balance
现在 SOTA 由 两阶段方法占据。
介绍下 Anchor-based 的 one-stage 方法的 SSD?
SSD 计算效率高。 SSD spreads out anchor boxes on multi-scale layers within a ConvNet to directly predict object category and anchor box offsets.
SSD 后面有什么改进?
- fusing context information from different layers
- training from scratch
- introducing new loss function
- anchor refinement and matching
- architecture redesign
- feature enrichment and alignment
one-stage 目前性能近似与 Two-stage ,并且推理更快。
介绍下 Anchor-free 的 Keypoint-based 方法?
first locates several pre-defined or self-learned keypoints, and then generates bounding boxes to detect objects.
Keypoint-based 有哪些算法?
- CornerNet
- CornerNet-Lite
- The second stage of Grid R-CNN
- ExtremeNet
- Objects as points
- CenterNet
- RepPoints
介绍下 Anchor-free 的 Center-based 方法?
regards the center (e.g., the center point or part) of object as foreground to define positives, and then predicts the distances from positives to the four sides of the object bounding box for detection.
Center-based 有哪些算法?
- YOLOv1
- DenseBox
- GA-RPN
- FSAF
- FCOS
- CSP
- FoveaBox
3. Difference Analysis of Anchor-based and Anchor-free Detection
we just tile one square anchor per location for RetinaNet, which is quite similar to FCOS.
实验细节:略
Classification
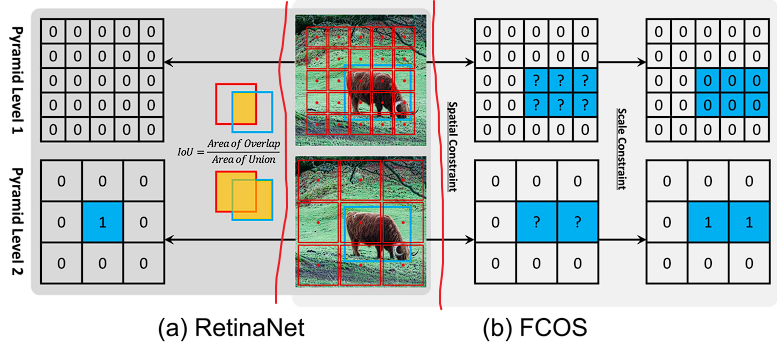
Figure 1: Definition of positives ( 1 ) and negatives ( 0 ). Blue box, red box and red point are ground-truth, anchor box and anchor point. (a) RetinaNet uses IoU to select positives ( 1 ) in spatial and scale dimension simultaneously. (b) FCOS first finds candidate positives ( ? ) in spatial dimension, then selects final positives ( 1 ) in scale dimension.
RetinaNet 怎么选择训练时候的正负样本的?
RetinaNet utilizes IoU to divide the anchor boxes from different pyramid levels into positives and negatives. It first labels the best anchor box of each object and the anchor boxes with \(IoU > θ_p\) as positives, then regards the anchor boxes with \(IoU < θ_n\) as negatives, finally other anchor boxes are ignored during training.
FCOS 怎么选择训练时候的正负样本的?
FCOS uses spatial and scale constraints to divide the anchor points from different pyramid levels. It first considers the anchor points within the ground-truth box as candidate positive samples, then selects the final positive samples from candidates based on the scale range defined for each pyramid level注 , finally those unselected anchor points are negative samples.
注:There are several preset hyperparameters in FCOS to define the scale range for five pyramid levels: [m2, m3] for P3, [m3, m4] for P4, [m4,m5] for P5, [m5, m6] for P6 and [m6, m7] for P7.
RetinaNet 和 FCOS 选择训练时候的正负样本策略有什么不同?哪个更优?
FCOS first uses the spatial constraint to find candidate positives in the spatial dimension,
then uses the scale constraint to select final positives in the scale dimension.
In contrast, RetinaNet utilizes IoU to directly select the final positives in the spatial and scale dimension simultaneously.
这两种策略 produce different positive and negative samples.
实验表明,the spatial and scale constraint strategy 优于 the IoU strategy.
Regression
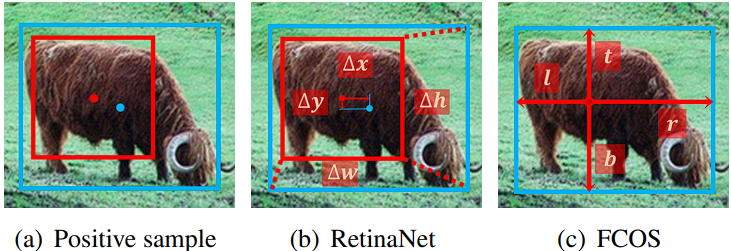
Figure 2: (a) Blue point and box are the center and bound of object, red point and box are the center and bound of anchor. (b) RetinaNet regresses from anchor box with four offsets. (c) FCOS regresses from anchor point with four distances.
RetinaNet 和 FCOS 回归有什么不同?
RetinaNet regresses from the anchor box with four offsets between the anchor box and the object box. 图2(b)
FCOS regresses from the anchor point with four distances to the bound of object. 图2(c)
It means that for a positive sample, the regression starting status of RetinaNet is a box
while FCOS is a point.
从 a box 和 a point 回归会导致模型性能改变吗?
实验结果表明: the regression starting status(a box or a point) 对性能没什么用。
one-stage anchor-based detectors and center-based anchorfree detectors 的根本区别在哪里?
how to define positive and negative training samples.
4. Adaptive Training Sample Selection(ATSS)
训练目标检测器的时候,正负样本有什么用?
When training an object detector, we first need to define positive and negative samples for classification, and then use positive samples for regression.
ATSS 有什么优点?
almost has no hyperparameters and is robust to different settings.
先前的训练时候的样本分配策略有什么缺点?
Previous sample selection strategies have some sensitive hyperparameters, such as IoU thresholds in anchor-based detectors and scale ranges in anchor-free detectors. After these hyperparameters are set, all ground-truth boxes must select their positive samples based on the fixed rules, which are suitable for most objects, but some outer objects will be neglected. Thus, different settings of these hyperparameters will have very different results.
ATSS 的步骤是什么样的?
- For each ground-truth box \(g\) on the image, we first find out its candidate positive samples. As described in Line 3 to 6, on each pyramid level, we select \(k\) anchor boxes whose center are closest to the center of \(g\) based on L2 distance. Supposing there are L feature pyramid levels, the ground-truth box \(g\) will have \(k × L\) candidate positive samples.
- After that, we compute the IoU between these candidates and the ground-truth \(g\) as \(D_g\) in Line 7, whose mean and standard deviation are computed as \(m_g\) and \(v_g\) in Line 8 and Line 9.
- With these statistics, the IoU threshold for this ground-truth \(g\) is obtained as \(t_g = m_g+v_g\) in Line 10.
- Finally, we select these candidates whose IoU are greater than or equal to the threshold \(t_g\) as final positive samples in Line 11 to 15.
- Notably, we also limit the positive samples’ center to the ground-truth box as shown in Line 12.
- Besides, if an anchor box is assigned to multiple ground-truth boxes, the one with the highest IoU will be selected. The rest are negative samples.

1). 对于每个 gt,在每个特征金字塔层都选出 k(默认k=9)个 候选anchors,这些候选 anchors 是中心到 gt box 中心最近的 k 个,若有 L 个金字塔特征层则每个 gt 都会选出 k*L 个候选anchors;
2). 对于每个gt box,计算其每个 候选anchor和它的 IoU,从而进一步计算出这些 IoU 的均值和标准差,然后将 IoU 阀值设置为均值和标准差之和;
3). 对于每个 gt,在 候选anchors 中选出 IoU不小于阀值 并且 中心在也这个 gt box 内的作为正样本,其余则为负样本.
关于 ATSS 的几个问题?
为什么 Selecting candidates based on the center distance between anchor box and object?
For RetinaNet, the IoU is larger when the center of anchor box is closer to the center of object. For FCOS, the closer anchor point to the center of object will produce higher-quality detections. Thus, the closer anchor to the center of object is the better candidate.
为什么 Using the sum of mean and standard deviation as the IoU threshold ?
The IoU mean \(m_g\) of an object is a measure of the suitability of the preset anchors for this object. A high \(m_g\) as shown in Figure 3(a) indicates it has high-quality candidates and the IoU threshold is supposed to be high.
A low \(m_g\) as shown in Figure 3(b) indicates that most of its candidates are low-quality and the IoU threshold should be low.
Besides, the IoU standard deviation \(v_g\) of an object is a measure of which layers are suitable to detect this object. A high \(v_g\) as shown in Figure 3(a) means there is a pyramid level specifically suitable for this object, adding \(v_g\) to \(m_g\) obtains a high threshold to select positives only from that level. A low \(v_g\) as shown in Figure 3(b) means that there are several pyramid levels suitable for this object, adding \(v_g\) to \(m_g\) obtains a low threshold to select appropriate positives from these levels.
Using the sum of mean \(m_g\) and standard deviation \(v_g\) as the IoU threshold \(t_g\) can adaptively select enough positives for each object from appropriate pyramid levels in accordance of statistical characteristics of object.
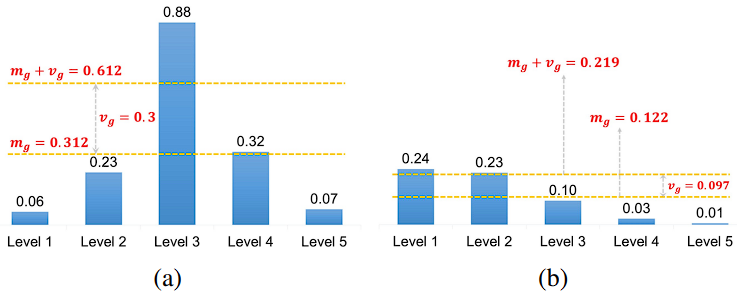
Figure 3: Illustration of ATSS. Each level has one candidate with its IoU. (a) A ground-truth with a high \(m_g\) and a high \(v_g\). (b) A ground-truth with a low \(m_g\) and a low \(v_g\).
为什么 Limiting the positive samples’ center to object ?
The anchor with a center outside object is a poor candidate and will be predicted by the features outside the object, which is not conducive(有益的) to training and should be excluded(排除).
为什么 Maintaining fairness between different objects?
According to the statistical theory, about 16% of samples are in the confidence interval \([m_g + v_g, 1]\) in theory. Although the IoU of candidates is not a standard normal distribution, the statistical results show that each object has about \(0.2 ∗ kL\) positive samples, which is invariant to its scale, aspect ratio and location.
In contrast, strategies of RetinaNet and FCOS tend to have much more positive samples for larger objects, leading to unfairness between different objects.
为什么 Keeping almost hyperparameter-free?
only has one hyperparameter k, 并且对 k 的值不敏感,所以几乎是 almost hyperparameter-free。
5. Conclusion
略

 浙公网安备 33010602011771号
浙公网安备 33010602011771号