【目标检测】重读经典之 SSD: Single Shot MultiBox Detector
| 原始题目 | SSD: Single Shot MultiBox Detector |
|---|---|
| 中文名称 | SSD: 一阶段 多框 检测器 |
| 发表时间 | 2015年12月8日 |
| 平台 | ECCV 2016 |
| 来源 | 北卡罗来纳大学教堂山分校 |
| 文章链接 | https://arxiv.org/abs/1512.02325 |
| 开源代码 | Caffe: https://github.com/weiliu89/caffe/tree/ssd Pytorch: https://github.com/amdegroot/ssd.pytorch TensorFlow: https://github.com/balancap/SSD-Tensorflow |
| 作者幻灯片 | http://www.cs.unc.edu/~wliu/papers/ssd_eccv2016_slide.pdf |
摘要
本文提出一种使用单个深度神经网络检测图像中目标的方法。
- 所提出的方法称为
SSD,将 bounding boxes 的输出空间 离散化(discretizes) 为一组默认 boxes,这些 boxes 具有每个特征地图位置 不同的 aspect ratios 和 scales 。 - 在预测时,网络为 每个默认 boxes 中每个对象类别的存在生成分数,并对 box 进行调整,以更好地匹配对象形状。
- 此外,该网络结合了来自不同分辨率的多个特征图的预测,以自然地处理各种大小的对象。
- 与需要 object proposals 的方法相比,SSD 是简单的,因为它完全消除了 proposal 的生成和后续的像素或特征重采样阶段,并将所有计算封装在单个网络中。这使得SSD易于训练,并且可以直接集成到需要检测组件的系统中。
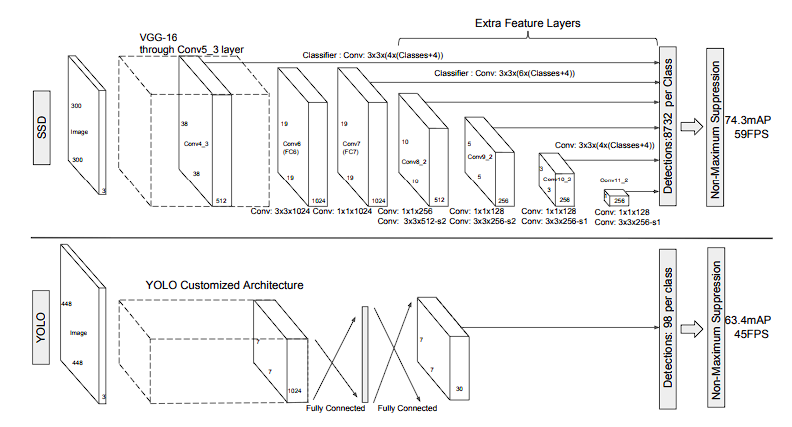
在 PASCAL VOC、COCO 和 ILSVRC 数据集上的实验结果表明,SSD 的准确性与利用额外的 object proposal 步骤的方法相比具有竞争力,并且速度快得多,同时为训练和推理提供了一个统一的框架。对于300 × 300输入,SSD 在 VOC2007 测试中以 59 FPS 的速度实现了 74.3% 的 mAP1,对于 512 × 512 输入,SSD实现了 76.9% 的 mAP,超过了最先进的 Faster R-CNN 模型。与其他单阶段方法相比,SSD 在输入图像较小的情况下仍具有较高的精度。
1 在后续的实验中,我们使用改进的数据增强方案取得了更好的结果:在VOC2007上,300×300输入的mAP为77.2%,512×512输入的mAP为79.8%。详情看 3.6 节。
Single Shot: 单阶段的意思。
MultiBox Detector:意思应该是 多目标检测的意思。
5 Conclusions
本文提出了 SSD,一种面向 多类别的快速 single-shot 目标检测器。我们模型的一个关键特征是 使用连接到网络顶部多个特征图的多尺度卷积 bounding box 输出。这种表示方式使我们能够有效地对可能的 box 形状空间进行建模。通过实验验证了,给定适当的训练策略,大量的精心选择的默认 bounding boxes 可以提高性能。我们构建的 SSD 模型比现有方法至少多一个数量级的 box 预测采样位置、scale, and aspect ratio[5,7]。实验表明,在相同的 VGG-16 基础架构下,SSD 在精度和速度方面都与最先进的目标检测器相媲美。所提出的 SSD512 模型在PASCAL VOC和 COCO上的精度方面明显优于最先进的 Faster R-CNN[2],同时速度快了3倍。所提出的实时 SSD300 模型以 59 FPS 的速度运行,比当前的实时 YOLO[5] 方法更快,同时产生了明显优越的检测精度。
除了其独立的实用功能,我们相信我们的 整体的和相对简单的 SSD 模型为 采用目标检测组件的 大型系统提供了一个有用的构建块。一个有希望的未来方向是探索将其作为使用 recurrent neural networks 同时检测和跟踪视频中的目标的系统的一部分。
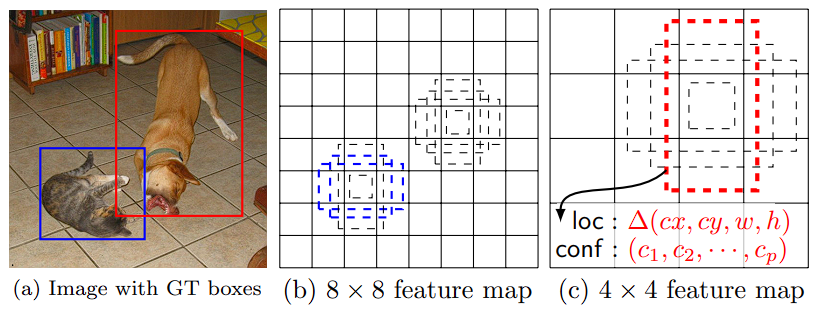
2.2 训练
Data augmentation
目的让模型对于不同的对象大小,形状更加稳健。每张训练图像被随机采样以下一种方式:
- 使用整张图像
- 采样一个 patch,与物体之间最小的 jaccard overlap 为:0.1,0.3,0.5,0.7 与 0.9
- 随机采样一个 patch
patch :就是图像中的一块的意思;jaccard overlap 就是 IOU 的意思,参考:IOU(Jaccard系数)概念及实现
每个 采样的 patch 的大小 是原始图像大小的 [0.1,1],aspect ratio 在 0.5 与 2 之间。
当 ground truth box 的 中心(center)在采样的 patch 中时,我们保留 ground truth box 的重叠部分。
在这些采样步骤之后,每一个采样的 patch 被 resize 到固定的大小,并且以 0.5 的概率随机的 水平翻转(horizontally flipped)。此外,应用一些类似于[14]中描述的 photo-metric distortions 。
3.6 Small Object Accuracy 的数据增强
follow-up: adj. 后续的
demonstrated: adj. 已证明的
dramatically: adv. 剧烈地,明显地
canvas: n. 帆布;画布
The random crops generated by the strategy can be thought of as a ”zoom in” operation and can generate many larger training examples.
To implement a ”zoom out” operation that creates more small training examples, we first randomly place an image on a canvas of 16× of the original image size filled with mean values before we do any random crop operation.
也就是先 随机放置一张图像到 原始图像大小 16 倍的背景中(padding 区域使用 mean 像素值),然后再随机 crop,这样就可以获得小目标的训练样本。
其余参考:
【1】SSD原理与实现
【2】Speed/accuracy trade-offs for modern convolutional object detectors 应该值得读下
【3】SSD 论文翻译

 浙公网安备 33010602011771号
浙公网安备 33010602011771号