pix2tex - LaTeX OCR 基于图像的公式识别 实践笔记
在线LaTex 公式编辑
强大的是:这个竟然支持图像识别公式,太棒了。 好吧,它收费了。我决定要抛弃它的图像识别功能了了。
由于该在线图像识别公式的应用已经收费。因此我尝试了如下开源库用来图像识别公式:
代码仓库: https://github.com/lukas-blecher/LaTeX-OCR
这个项目的目标是创建一个基于学习的系统,该系统获取数学公式的图像并返回相应的 LaTeX 代码。
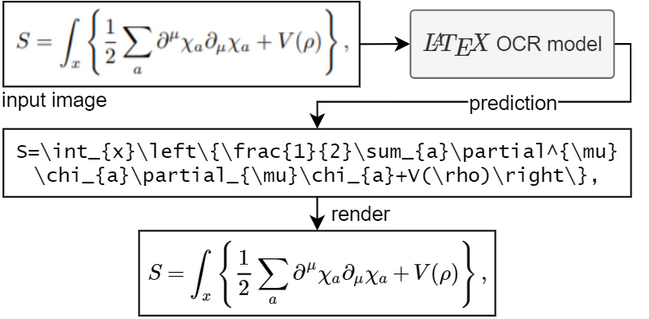
1. 安装
要求:Python 3.7+
pip install pix2tex[gui] -i https://pypi.tuna.tsinghua.edu.cn/simple
安装成功!
2. 运行
Thanks to @katie-lim, you can use a nice user interface as a quick way to get the model prediction. Just call the GUI with latexocr. From here you can take a screenshot and the predicted latex code is rendered using MathJax and copied to your clipboard.
我使用的 方式 2。 命令行 运行:
latexocr
报错: module 'numpy' has no attribute 'object'。
我的 numpy 版本:'1.24.1'。
解决方案:卸载重装支持的。参考:module 'numpy' has no attribute 'object'
pip install numpy==1.23.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
当然也可以选择,还是使用当前版本的numpy,自己把包里面的这些不支持操作都改了,只是比较麻烦。
然后执行: latexocr, 继续报错:
requests.exceptions.SSLError: HTTPSConnectionPool(host='github.com', port=443): Max retries exceeded with url: /lukas-blecher/LaTeX-OCR/releases/download/v0.0.1/weights.pth (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1131)')))
好吧,这是因为我开了github 加速代理。把代理关了就可以下载预训练权重了。
下载速度慢的问题,可以开 vpn 或者 迅雷 解决。
下载链接:https://github.com/lukas-blecher/LaTeX-OCR/releases/download/v0.0.1/weights.pth
放到 推荐的目录中:
C:\ProgramData\Miniconda3\envs\xx\lib\site-packages\pix2tex\model\checkpoints
然后运行: latexocr
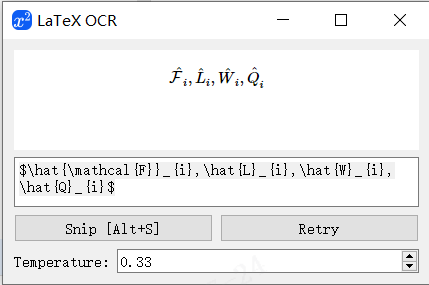
完美打开!








【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理