Hand 识别产品调研
百度产品:
1. 手势识别
24种常见手势。
1)上述24类以外的其他手势会划分到other类,其实就是啥都不显示。
2)除识别手势外,若图像中检测到人脸,会同时返回人脸框位置。
应用的技术分析:
手部检测(单手或双手)、人脸检测、检测到手部后对手进行 2D CNN 分类。
参考:https://cloud.baidu.com/doc/BODY/s/4k3cpywrv
2. 手部关键点识别
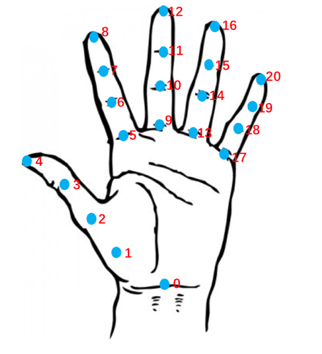
关键点和 mediapipe 的定义一样。输出有两个分数:
- 检测手的框的置信度分数,比如:"score": 17.495880126953, 当前取值范围0-21,应用时可除以21进行归一化处理,下一版服务会进行更新、修正
- 每个关键点都有一个置信度分数。置信度分数,取值范围0-1。可基于置信度分数进行过滤,排除掉分数低的误识别“无效关键点”,推荐的过滤方案:置信度分数≥0.2。实际应用中,可根据对误识别、漏识别的容忍程度,调整阈值过滤方案,灵活应用。
应用的技术分析:
手部检测(单手或双手)、检测到手部后对手进行 2D 关键点定位。
参考:https://cloud.baidu.com/doc/BODY/s/Kk3cpyxeu
3. 食指指尖检测
显然是,手部关键点检测的简化版。手部坐标定位存在错误,且置信度全为1。
阿里产品:
1. 手势关键点检测
试了下样例,如果手部弯曲,感觉都识别的不好。注意有两个置信度分数:
- 每只手有一个置信度分数
- 每只手的 bbox 也有一个置信度分数
应用技术分析:
2D 手部检测模型,检测到的手进行 2D 关键点回归且只输出一个置信度分数。
参考:https://help.aliyun.com/document_detail/159214.html#resultMapping
2. 静态手势识别
一共可识别 7 种手势,还可以识别其他手势为背景。
技术分析:
完全基于 2D 检测模型,可能还有个异常检测。
参考:https://help.aliyun.com/document_detail/206650.html
腾讯产品:
官方链接已挂。找到一个介绍文档。
http://www.ksyuwei.cn/product/289-cn.html
旷视产品:
显然只是一个 2D 检测的手势识别,且具有识别未定义手势的功能。
参考:https://www.faceplusplus.com.cn/document/guide_docs/gesture
商汤产品:
14中常用的手势,手指关键点信息,好像还有手部跟踪功能。
参考:http://openar.sensetime.com/docs
谷歌产品:
MediaPipe Hands
A palm detection model that operates on the full image and returns an oriented hand bounding box. A hand landmark model that operates on the cropped image region defined by the palm detector and returns high-fidelity 3D hand keypoints.
使用两个模型串起来:
- Palm Detection Model
First, we train a palm detector instead of a hand detector, since estimating bounding boxes of rigid objects like palms and fists is significantly simpler than detecting hands with articulated fingers. In addition, as palms are smaller objects, the non-maximum suppression algorithm works well even for two-hand self-occlusion cases, like handshakes. Moreover, palms can be modelled using square bounding boxes (anchors in ML terminology) ignoring other aspect ratios, and therefore reducing the number of anchors by a factor of 3-5. Second, an encoder-decoder feature extractor is used for bigger scene context awareness even for small objects (similar to the RetinaNet approach). Lastly, we minimize the focal loss during training to support a large amount of anchors resulting from the high scale variance.
- Hand Landmark Model
To obtain ground truth data, we have manually annotated ~30K real-world images with 21 3D coordinates, as shown below (we take Z-value from image depth map, if it exists per corresponding coordinate). To better cover the possible hand poses and provide additional supervision on the nature of hand geometry, we also render a high-quality synthetic hand model over various backgrounds and map it to the corresponding 3D coordinates.
参考:https://google.github.io/mediapipe/solutions/hands
我认为的手势识别解决方案
- 完全端到端,比如直接使用一个 YOLOv5 模型就可以完成定位和分类了。如果新加一个手势,可能就需要全部重新训练一遍。
- 检测手的模型,关键点定位的模型,基于关键点手势识别的模型(可以使用 基于关键点的 SVM 、MLP 等,加入手工编写的规则校验。)好处:解耦合,因为我们最终的目的可能只是识别手势,前两个模型是和手势的类别没有关系的,因此,可以单独训练。而最后的分类模型,因为只是使用那少量的关键点,因此分类模型可以训练的很快,加入规则校验也可以保证结果的可靠性。缺点可能多个模型串联对计算能力和存储能力要求高一些,但是 谷歌的 mediapipe 证明是可以做到实时的,可能还需要加入跟踪算法使得检测器不一定每帧都运行。如果新加入一个手势,我们只需要训练最后的关键点分类器和编写相应的规则即可。缺点是关键点的数据难以标注,尤其是手势的遮挡问题普遍存在,2D 的关键点分类可能存在性能瓶颈。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号