【神经网络架构】EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks 论文阅读
| 原始题目 | EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks |
|---|---|
| 中文名称 | EfficientNet: 反思用于 CNNs 的模型扩展 |
| 发表时间 | 2019年5月28日 |
| 平台 | ICML 2019 |
| 来源 | 谷歌大脑 |
| 文章链接 | https://arxiv.org/abs/1905.11946 本文是v5 version |
| 开源代码 | https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet https://github.com/lukemelas/EfficientNet-PyTorch |
摘要
CNNs 通常实在一个有限的硬件下开发的,如果硬件更强大,就可以增大模型来获得更好的 accuracy。在论文中,我们系统的研究了模型的扩展,并且发现 仔细的平衡网络深度,宽度以及输入分辨率能够得到更优的网络,进而得到更好的结果。根据这一观察,我们提出了一个新的 扩展 方法,使用一个简单且高效的复合系数(compund coefficient),统一地 扩展 Depth/Width/Resolution 的 所有的维度。我们通过 增大 MobileNets 和 ResNet 来证明这个方法的有效性。
注:scaling 我翻译为 扩展,意思就是从一个基本模型扩展到不同大小的模型。
为了进一步的证明,我们使用 NAS 去设计一个新的 baseline 网络并且对其进行 增大 进而获得一个模型家族,叫做 EfficientNets,达到了比之前的 ConvNets 更好的 accuracy 和效率。尤其是我们的 EfficientNet-B7 在 ImageNet 上达到了最好的水平即 top-1 accuracy 84.4%/top-5 accuracy 97.1%,然而却比已有的最好的 ConvNet 模型小了 8.4倍 并且推理时间快了 6.1 倍。我们的 EfficientNet 迁移学习的效果也好,在 CIFAR-100(91.7%),Flowers(98.8%),和其他 3个 迁移学习数据集上用更少数量级的参数,达到了最好的 accuracy。
通过 NAS 得到最小的 baseline 模型,然后使用提出来的模型扩展方法增大模型,得到不同大小的模型。
7. 结论
本文系统地研究了 ConvNet 的扩展,并发现仔细平衡网络 宽度、深度和分辨率 是一个重要但缺失的部分,阻碍了我们获得更好的 accuracy 和效率。
为解决这个问题,本文提出一种简单高效的复合缩放方法,能够以更有设计准则的方式轻松地将 baseline ConvNet 扩大 到任何目标资源约束,同时保持模型效率。在这种复合缩放方法的支持下,本文证明了 mobile-size EfficientNet 模型可以非常有效地 扩大,在 ImageNet 和 五个 常用的迁移学习数据集上,以较少的参数和 FLOPS 超过最先进的 accuracy。
1. 引言
放大 ConvNets 被广泛用于实现更好的 accuracy 。
例如,ResNet (He et al., 2016) 可以通过使用更多的层数从 ResNet-18 放大到 ResNet-200;
最近,GPipe (Huang等人,2018)通过将 baseline 模型扩大四倍,实现了84.3% 的 ImageNet top-1 accuracy 。然而,放大 ConvNets 的过程从来没有被很好地理解,目前有许多方法来做到这一点。
最常见的方法是根据 ConvNets 的 depth (He et al.,2016)或 width(Zagoruyko & Komodakis, 2016) 放大 ConvNets。
另一种不太常见但越来越流行的方法是通过 图像分辨率 来放大模型(Huang等人,2018)。
在之前的工作中,通常只缩放三个维度中的一个 –-depth, width, and image size。虽然可以任意缩放两个或三个维度,但任意缩放需要繁琐的手动调整,仍然经常产生次优的 accuracy 和效率。
Scaling up: 翻译为放大
本文想研究和重新思考 ConvNets 的 Scaling up 过程。我们特别研究一个中心问题:有没有一种有原则的方法来扩大 ConvNets 可以实现更好的 accuracy 和效率?实证研究表明,平衡网络宽度/深度/分辨率的所有维度是至关重要的,令人惊讶的是,这种平衡可以通过简单地以固定的比例缩放每个维度来实现。基于这一观察,本文提出了一种简单而有效的复合 scaling 方法。与任意缩放这些因子的传统做法不同,所提出方法用一组固定的缩放系数均匀地缩放网络宽度、深度和分辨率。
例如,如果我们想使用 \(2^N\) 倍的计算资源,那么我们可以简单地将网络深度增加\(α^N\),宽度增加 \(β^N\),图像大小增加\(γ^N\),其中 α,β,γ 是通过在原始小模型上进行小网格搜索确定的常系数。图2 说明了我们的缩放方法和传统方法之间的区别。
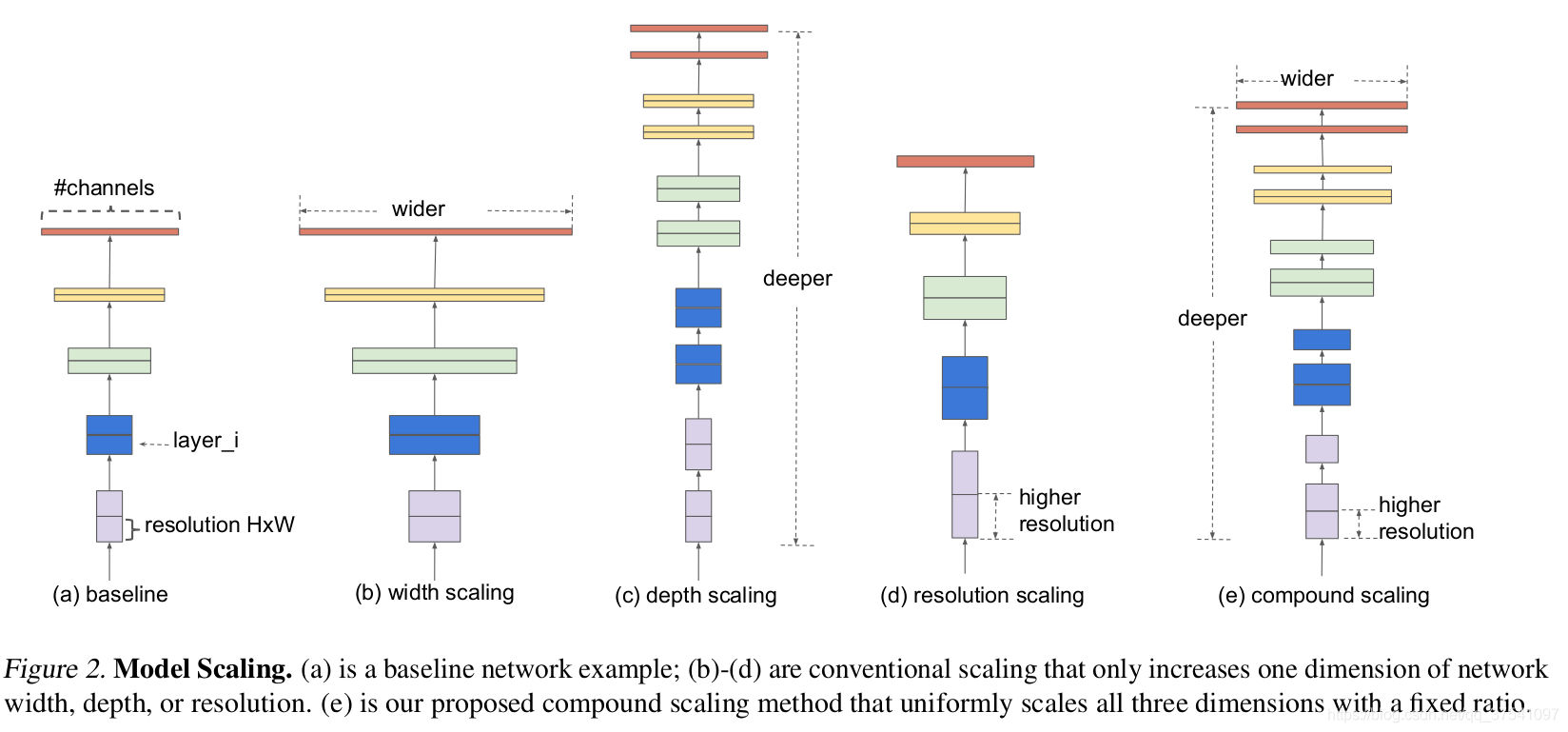
图2. 模型扩展。(a)是 一个 baseline 网络的例子; (b)-(d)是传统的缩放,只增加网络宽度、深度或分辨率的一个维度。(e)是我们提出的复合缩放方法,以固定的比例均匀缩放所有三个维度。
直观地说,复合缩放方法是有意义的,因为如果输入图像较大,那么网络需要更多的层来增加感受野,并需要更多的通道来捕捉更大图像上的更细粒度的模式。事实上,之前的理论(Raghu et al,2017; Lu et al.,2018)和实证结果(Zagoruyko & Komodakis, 2016)都表明网络宽度和深度之间存在一定的关系,但据我们所知,我们首次实证量化了网络宽度、深度和分辨率三个维度之间的关系。
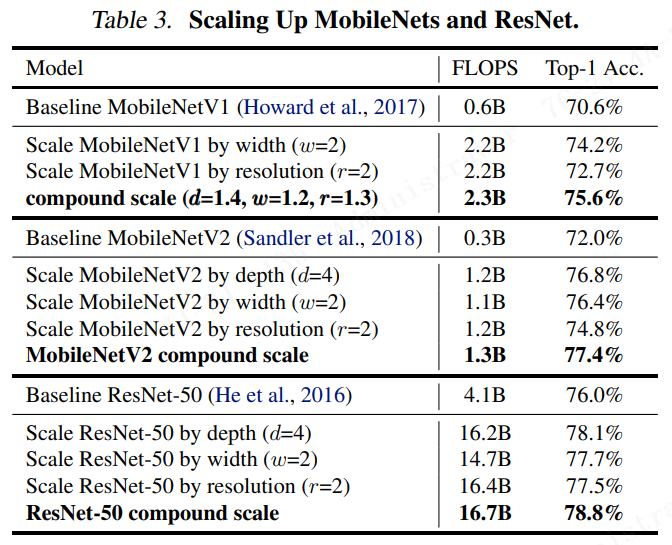
实验证明,所提出的扩展方法在现有的 MobileNets 上工作良好(Howard et al,2017; Sandler et al,2018) 和 ResNet (He et al,2016)。值得注意的是,模型扩展的有效性严重依赖于 baseline 网络;为了更进一步,我们使用神经架构搜索(Zoph & Le, 2017; Tan et al,2019)开发一个新的 baseline 网络,并将其扩展以获得一个称为 EfficientNets 的模型族。图1 总结了 ImageNet 的性能,其中 EfficientNets 的性能明显优于其他卷积网络。特别是,EfficientNet-B7 超过了现有最好的 GPipe 精度(Huang et al,2018),但使用的参数少了 8.4 倍,推理速度快了 6.1 倍。与广泛使用的 ResNet-50 相比(He et al.,2016), EfficientNet-B4 将 top-1 精度从 76.3% 提高到 83.0%(+6.7%),并且具有相似的 FLOPS。除了ImageNet, EfficientNets 也很好地迁移,在 8 个广泛使用的数据集中的 5个上实现了最先进的精度,同时比现有的 ConvNets 减少了多达 21 倍的参数。
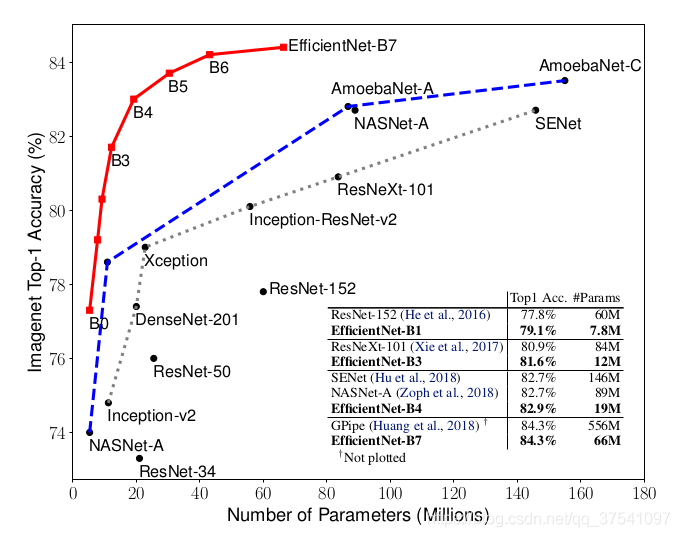
图1。Model Size vs. ImageNet Accuracy 。所有的数字都是single-crop, single-model。EfficientNets 的表现明显优于其他ConvNets。特别是,EfficientNet-B7 实现了最新的 84.3% top-1精度,但比 GPipe 小8.4倍、快 6.1 倍。EfficientNet-B1 比 ResNet-152 小 7.6倍,快 5.7 倍。详情见 表2 和 表4。
GPipe 是 2018年提出来的一个模型。
2. 相关工作
ConvNet Accuracy: 自 AlexNet (Krizhevsky et al., 2012)赢得2012年ImageNet竞赛以来,ConvNets 通过变得更大从而越来越准确:2014年ImageNet获胜者GoogleNet (Szegedy et al., 2015)以约 6.8M 参数实现了 74.8% 的最高精度,2017 年ImageNet获奖者SENet (Hu et al., 2018)以 145M 参数实现了 82.7% 的最高精度。最近,GPipe (Huang et al.,2018)使用 557M 参数将最先进的 ImageNet top-1 验证精度进一步提高到 84.3%: 它如此之大,以至于只能通过切分网络并将每个部分分摊到不同的加速器来用专门的 pipeline 并行库 进行训练。虽然这些模型主要是为ImageNet设计的,但最近的研究表明,更好的 ImageNet 模型也在各种迁移学习数据集(Kornblith et al., 2019)和其他计算机视觉任务(如目标检测)上表现更好(He et al., 2016;Tan et al., 2019)。虽然更高的精度对许多应用程序至关重要,但我们已经达到了硬件内存的限制,因此进一步提高精度需要更高的效率。
ConvNet Efficiency: 深度卷积网络通常是过度参数化的。模型压缩(Han et al.,2016; He et al., 2018; Yang et al.,2018)是一种通过 为了效率权衡精度 来降低模型大小的常见方法。随着手机变得无处不在,手工制作高效的 mobile-size 的卷积网络也很常见,如 SqueezeNets (Iandola et al.,2016; Gholami et al.,2018),MobileNets (Howard et al.,2017; Sandler et al.,2018)和 ShuffleNets (Zhang et al.,2018; Ma et al., 2018)。
最近,神经架构搜索在设计高效的 mobile-size 卷积网络中变得越来越流行(Tan et al., 2019;Cai et al., 2019),并通过广泛调整网络宽度、深度、卷积核类型和大小,实现了比手工制作的移动卷积网络更好的效率。然而,目前还不清楚如何将这些技术应用于具有更大的设计空间和更昂贵的调优成本的大型模型。本文旨在研究超大型卷积网络的模型效率,其精度超过了最先进的水平。为了实现这一目标,我们求助于模型缩放。
Model Scaling: 有许多方法可以针对不同的资源约束 来缩放 ConvNet: ResNet (He et al.,2016)可以通过调整网络深度(#layers) 来缩小(例如ResNet-18) 或 放大(例如ResNet-200),而 WideResNet (Zagoruyko & Komodakis, 2016) 和 MobileNets (Howard et al.,2017) 可以通过 网络宽度(#channels)缩小。众所周知,更大的输入图像大小将有助于准确性,但会带来更多的 FLOPS 开销。尽管之前的研究(Raghu et al.,2017; Lin & Jegelka, 2018;,2018; Sharir & Shashua, 2018; Lu et al., 2018)的研究表明,网络深度和宽度对卷积网络的表达能力都很重要,如何有效地缩放卷积网络以实现更好的效率和精度仍然是一个开放问题。 本文工作系统地和经验地研究了 网络宽度、深度和分辨率 所有三个维度的卷积网络缩放。
3.复合模型缩放
在本节中,我们将阐述缩放问题,研究不同的方法,并提出我们新的缩放方法。
3.1. 问题定义
一个 ConvNet Layer i 可以定义为 一个函数: \(Y_i=\mathcal{F_i}(X_i)\), 这里 \(\mathcal{F_i}\) 是一个操作(operator),\(Y_i\) 是输出的tensor,\(X_i\) 是输入tensor,tensor 形状为 \(\left\langle H_{i}, W_{i}, C_{i}\right\rangle^{1}\); \(H_{i}, W_{i}\) 是空间维度,\(C_{i}\) 是通道维度。一个 ConvNet N 可以表达为一系列复合层:\(\mathcal{N}=\mathcal{F}_{k} \odot \ldots \odot \mathcal{F}_{2} \odot \mathcal{F}_{1}\left(X_{1}\right)=\bigodot_{j=1 \ldots k} \mathcal{F}_{j}\left(X_{1}\right)\)。实际中,ConvNet 层 会被分为多个阶段,每个阶段的层都是相同的结构:例如,ResNet (He et al., 2016) 总共有5个阶段,除了第一层进行下采样,每个阶段的卷积层的类型相同。因此,我们可以将卷积网络定义如下:
这里,\(\mathcal{F}_{i}^{L_{i}}\) 表示层 \(\mathcal{F}_{i}\) 在阶段(stage)i 重复 \(L_{i}\) 次,\(\left\langle H_{i}, W_{i}, C_{i}\right\rangle\) 表示 第 i 层的输入 tensor 的形状。 图2(a) 表达了卷积网络,随着层的增加,空间的维度在逐渐减少,但是通道数逐渐增大。比如输入 tensor 从 <224, 224, 3> 到 最后的输出形状 <7, 7, 512>。
与常规的 ConvNet 设计主要集中于寻找 最佳层结构 \(\mathcal{F}_{i}\) 不同,模型缩放试图在不改变 baseline 网络中预定义的 \(\mathcal{F}_{i}\) 的情况下扩展 网络长度(\(L_i\))、宽度(\(C_i\))和/或分辨率(\(H_i, W_i\))。
通过固定 \(\mathcal{F}_{i}\) ,模型缩放 简化了新的资源约束的设计问题,但仍然有很大的设计空间来探索每一层的不同 \(L_i, C_i, H_i, W_i\)。为了进一步减少设计空间,我们限制所有层必须以 恒定的比例均匀缩放。我们的目标是 在任何给定资源约束的条件下 最大化模型精度 ,这可以表示为一个优化问题:
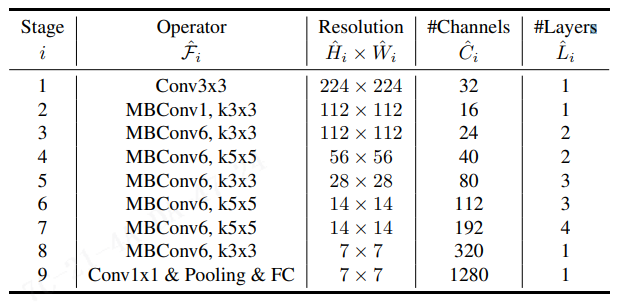
这里 \(w, d, r\) 网络宽度,深度和分辨率的缩放系数; \(\hat{\mathcal{F}}_{i},\hat{L}_{i},\hat{W}_{i},\hat{C}_{i}\) 是定义在 baseline 网络中的参数(见表1作为示例)。
表1. EfficientNet-B0 baseline network - 每行描述一个具有 \(\hat{L}_{i}\) 层的阶段 i,输入分辨率 \(\langle{\hat{H}}_{i},{\hat{W}}_{i}\rangle\) 和输出通道 \(\hat{C}_{i}\)。符号记法采用公式2。
3.2. 缩放维度
问题2的主要难点在于 最优 d、w、r 三者之间存在相互依赖关系,且在不同的资源约束下取值会发生变化。由于这一困难,传统方法主要是在其中一个维度上对卷积网络进行缩放:
Depth (d): ): 缩放网络深度是许多 ConvNets 最常用的方法 (He et al., 2016; Huang et al., 2017; Szegedy et al., 2015; 2016)。直觉是,更深的卷积网络可以捕获更丰富和更复杂的特征,并在新任务上有很好的泛化能力。然而,由于梯度消失问题,更深的网络也更难以训练 (Zagoruyko & Komodakis, 2016)。尽管一些技术,如 跳跃连接 (He et al., 2016)和 批量归一化(Ioffe & Szegedy, 2015),缓解了训练问题,但非常深的网络的精度增益却降低了: 例如,ResNet-1000 与 ResNet-101 的精度相似,尽管它的层数更多。图3(中间) 显示了我们对具有不同深度系数 d 的 baseline 模型进行缩放的实证研究,进一步表明非常深的卷积神经网络的精度回报递减。
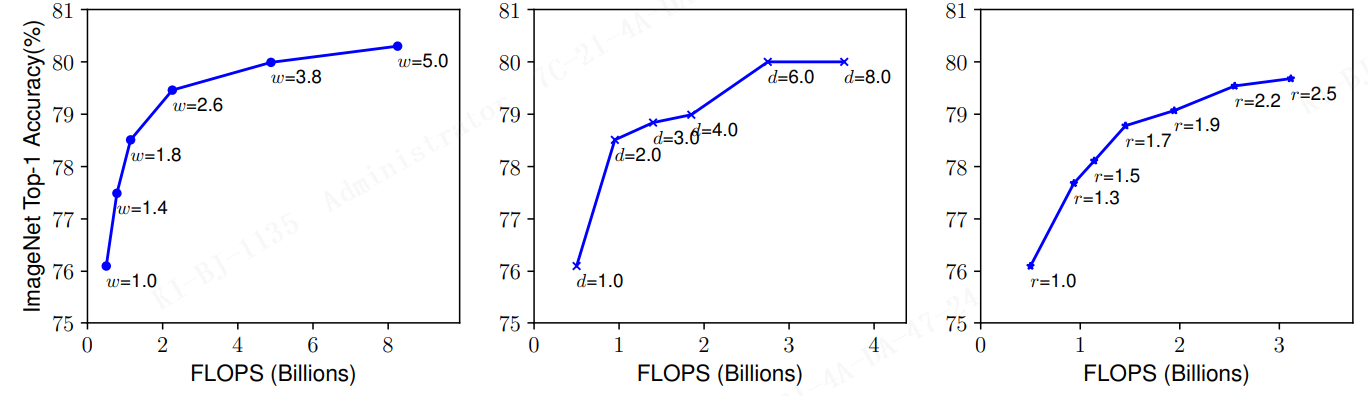
图3. 使用不同的网络宽度(w)、深度(d)和分辨率(r)系数缩放 baseline 模型。较大的网络具有较大的宽度、深度或分辨率,往往可以获得较高的精度,但精度增益在达到 80% 后迅速饱和,显示了单一维度缩放的局限性。baseline 网络如 表1 所示。
Width(w): 缩放网络 宽度 通常用于小型模型 (Howard et al., 2017; Sandler et al., 2018; Tan et al., 2019)^2 。 正如(Zagoruyko & Komodakis, 2016)中讨论的那样,更宽的网络往往能够捕获更多细粒度特征,也更容易训练。然而,极宽但极浅的网络往往难以捕获更高层次的特征。 我们在 图3(左) 中的经验结果表明,当网络随着 w 的增大而变得更宽时,精度迅速饱和。
Resolution (r): 通过更高分辨率的输入图像,ConvNets 可以捕获更细粒度的模式。 从早期 ConvNets 的 224x224 开始,现代 ConvNets 倾向于使用 299x299 (Szegedy et al.,2016) 或 331x331 (Zoph et al.,2018)以获得更好的准确性。最近,GPipe (Huang 等人,2018)以480 × 480 分辨率实现了最先进的 ImageNet 精度。更高的分辨率,如600x600,也广泛应用于 目标检测卷积网络(He et al., 2017; Lin et al., 2017)。图3(右) 显示了缩放网络分辨率的结果,更高的分辨率确实可以提高精度,但非常高的分辨率会降低精度增益(r = 1.0 表示分辨率224x224, r = 2.5 表示分辨率 560x560)。
上述分析使我们得到第一个观察结果:
观察1 —— 扩大网络宽度、深度或分辨率的任何维度都可以提高精度,但对于更大的模型,精度增益会降低。
3.3. 复合缩放
通过经验观察,不同的 缩放维度 不是独立的。直观地说,对于更高分辨率的图像,我们应该增加网络深度,这样更大的感受野可以帮助捕捉在更大的图像中包含更多像素的类似特征。相应地,当分辨率更高时,我们也应该增加网络宽度,以便在高分辨率图像中捕获更多像素的更细粒度的模式。这些直觉表明,我们需要协调和平衡不同的缩放维度,而不是传统的单一维度缩放。
为了验证我们的直觉,我们比较了不同网络深度和分辨率下的宽度缩放,如 图4 所示。如果我们只缩放网络宽度 w,而不改变 深度(d=1.0)和分辨率(r=1.0),精度会很快饱和。随着更深(d=2.0)和更高的分辨率(r=2.0),宽度缩放在相同的 FLOPS 成本下获得了更好的精度。这些结果引出了第二个观察结果:
观察2 ——为了追求更好的精度和效率,在卷积网络缩放过程中平衡网络宽度、深度和分辨率的所有维度是至关重要的。
事实上,之前的一些工作(Zoph et al., 2018; Real et al., 2019)已经尝试任意平衡网络宽度和深度,但它们都需要繁琐的手动调整。
本文提出了一种新的复合尺度方法,该方法使用复合系数 \(φ\) 以一种原则性的方式统一尺度网络宽度、深度和分辨率:
其中 \(α、β、γ\) 是常数,可以通过小网格搜索确定。直观地说,φ 是用户指定的系数,控制可供模型缩放的资源数量,而 \(α、β、γ\) 指定如何分别将这些额外资源分配给网络宽度、深度和分辨率。值得注意的是,常规卷积 的 FLOPS 的计算量与 \(d, w^2, r^2\) 成正比,即网络 深度加倍 将 计算量加倍,但网络 宽度或分辨率加倍 将计算量增加 四倍。由于 卷积 ops 通常主导ConvNets 的计算成本,用 公式3 缩放 ConvNet 将大约增加 总的 FLOPS \((α·β^2·γ^2)^φ\) 倍。在本文中,我们约束 \(α·β^2·γ^2≈2\),使得对于任何新的 \(φ\) ,总 FLOPS 将近似地增加\(2^φ\)。
4. EfficientNet Architecture
由于模型缩放不会改变 baseline 网络中的层算子 \(\mathcal{F}_{i}\),因此拥有一个良好的 baseline 网络也至关重要。我们将使用现有的 ConvNet 来评估我们的缩放方法,但为了更好地证明缩放方法的有效性,我们还开发了一个新的 mobile-siz 的 baseline ,称为 EfficientNet.
受 (Tan et al., 2019) 启发,通过利用 multi-objective 神经架构搜索来优化精度和 FLOP,开发了 baseline 网络。具体来说,我们使用与(Tan et al.,2019) 相同的搜索空间,并使用 \(ACC(m)\times[F L O P S(m)/T]^{w}\) 作为优化目标,其中 ACC(m) 和 FLOPS(m) 表示模型 m 的 精度 和 FLOPS, T 是目标 FLOPS, w=-0.07 是用于控制精度和FLOPS之间权衡的超参数。不像(Tan et al., 2019; Cai et al., 2019),这里我们优化 FLOPS 而不是延迟,因为我们没有针对任何特定的硬件设备。我们的搜索产生了一个有效的网络,我们将其命名为 EfficientNet-B0。由于我们使用与 (Tan et al., 2019) 相同的搜索空间,该架构类似于 MnasNet,除了我们的 EfficientNet-B0 略大,因为我们的 FLOPS 目标更大(我们的 FLOPS 目标是 400M)。表1 显示了 EfficientNet-B0 的架构。其主要构建模块是 mobile inverted bottleneck MBConv (Sandler et al., 2018; Tan et al., 2019),我们还添加了 squeeze-and-excitation optimization (Hu et al., 2018).
从 baseline EfficientNet-B0 开始,我们应用复合缩放方法,分两步进行缩放:
步骤1: 我们首先确定 φ = 1,假设有两倍以上的可用资源,并根据 公式2和3 对 \(α,β,γ\) 做一个小的网格搜索。特别地,在 \(α·β^2·γ^2≈2\) 的约束下,EfficientNet-B0 的最佳值为 α = 1.2, β = 1.1, γ = 1.15。
步骤2: 然后将 α,β,γ 固定为常数,并使用 公式3 放大 具有不同 φ 的 baseline 网络,以获得 EfficientNet-B1 到 B7 (详细信息见表2)。
表2. EfficientNet 在 ImageNet 上的性能结果(Russakovsky et al., 2015)。所有 EfficientNet 模型都是从我们的 baseline EfficientNet-b0 出发,使用 公式3 中不同的复合系数 φ 进行缩放。具有相似 top-1/top-5 精度的卷积网络被分组在一起,以进行效率比较。所提出的缩放后的 EfficientNet 模型始终比现有的 ConvNets 将参数和 FLOPS 减少一个数量级(高达8.4倍的参数减少和高达16倍的 FLOPS 减少)。
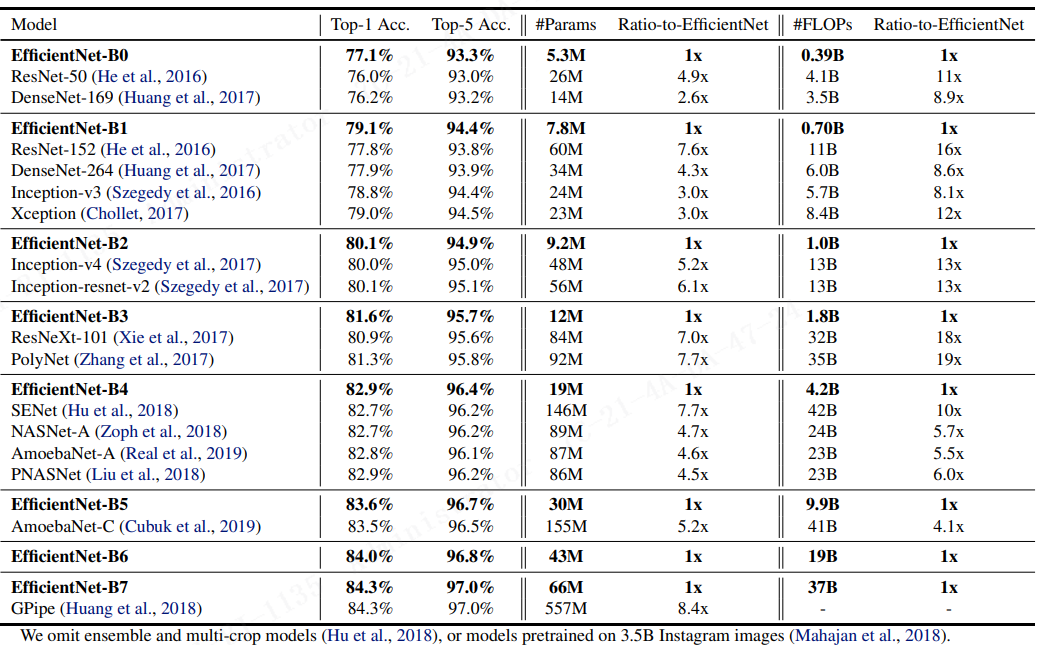
本文省略了集成模型和 multi-crop 模型(Hu et al., 2018), 或在 3.5B Instagram 图像上预训练的模型 (Mahajan et al., 2018)。
值得注意的是,通过直接在大型模型周围搜索 α, β, γ 可以获得更好的性能,但在更大的模型上搜索成本变得非常昂贵。我们的方法通过只在小的 baseline 网络上进行一次搜索(步骤1)来解决这个问题,然后对所有其他模型使用相同的缩放系数(步骤2)。
5. 实验
略
6. 讨论
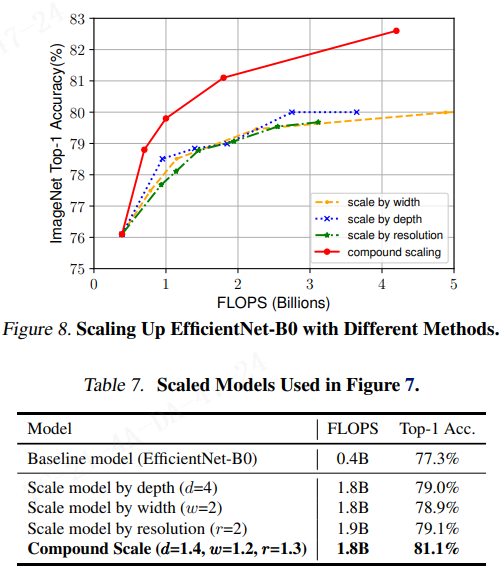
为了从 EfficientNet 架构中分离出我们所提出的缩放方法的贡献,图8 比较了相同 EfficientNet-b0 baseline 网络的不同缩放方法的 ImageNet 性能。总的来说,所有的缩放方法都以更多的 FLOPS 为代价来提高精度,但所提出的复合缩放方法可以进一步提高精度,比其他单维度缩放方法最高提高2.5%,表明所提出的复合缩放的重要性。
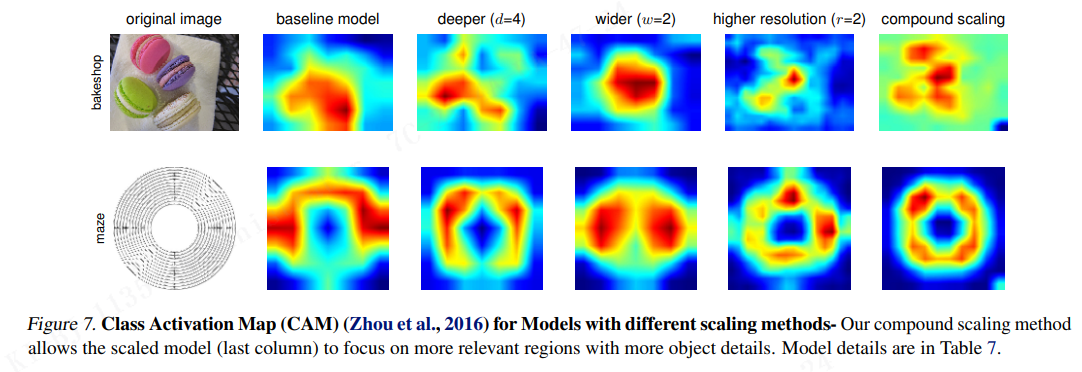
为了进一步理解为什么我们的复合缩放方法比其他方法更好,图7 比较了几个具有不同缩放方法的代表性模型的 class 激活图(Zhou et al.,2016)。所有这些模型都是从同一 baseline 缩放的,它们的统计数据如 表7 所示。图像是从 ImageNet 验证集随机选取的。如图所示,复合缩放的模型倾向于关注更相关、物体细节更多的区域,而其他模型要么缺乏物体细节,要么无法捕捉图像中的所有物体。
附录:
自 2017 年以来,大多数研究论文只报告和比较 ImageNet验证集 accuracy; 为了更好地进行比较,本文也遵循这个惯例。此外,我们还通过将我们对 100k 测试集图像的预测提交到 http://image-net.org 来验证测试accuracy;结果如 表8 所示。正如预期的那样,测试 accuracy 非常接近 验证 accuracy。
说明没有过拟合。
时间有限,就不全部翻译了。中文翻译参考:
https://blog.csdn.net/kxh123456/article/details/109471654
总结
本文解决了两个问题:
1. 如何从一个 baseline 模型得到性能更好的大一些的模型,以获得更好的 accuracy ?
解决:发明了一个复合放大方法,可以同时放大 深度、宽度和 图像分辨率输入。该方法还可以用到其他baseline模型如 MobileNets 和 ResNet 。 创新点在于:之前的模型放大都是只放大 深度、宽度或图像分辨率输入 中的一个,同时放大这三个,优势在于同时放大,比单独放大一个 accuracy 更高。
2. 如何得到一个更好的 baseline 模型?
通过神经网络架构搜索(NAS)得到的, EfficientNet-B0(参数:5.3M 计算量: 400M FLOPS)。
然后通过复合放大方法得到:B1 -> B7(参数: 66M,计算量: 37B FLOPS)。
特点是:参数更少(少一个数量级),accuracy 更高。
3. 关键问题1:复合放大咋弄的?
待研究,但是实际直接用它不同放大的模型即可。
4. 怎么 NAS 得到的 EfficientNet-B0 ?
待研究,但是也直接用就行。可能研究这个需要更多的 GPUs,条件不允许啊。
详解: 待研究

 浙公网安备 33010602011771号
浙公网安备 33010602011771号