Python 装饰器用法
@dec
def func():
pass
装饰器(Decorator)为装饰对象的器件,既可以装饰[函数](# 1. 对带参数的函数进行装饰),又可以装饰[类](# 6. 类装饰器)。可以在不修改代码条件下,为装饰对象添加新的功能或者帮助输出。装饰器的典型应用场景有类型检查、用户验证、输入合理性检查、输出格式化、异常捕获、日志管理。
为什么要用装饰器
在官方文档中,Python 2.4 引入的decorators , 具有重要优势:
- decorators help reducing boilerplate code; 减少样板代码
- decorators help separation of concerns; 分离关注点
- decorators enhance readability and maintenability; 增强可读性和可维护性
- decorators are explicit. 显示的装饰器
-
michele.simionato 开发的
decorator模块,简化了decorators的使用,并附上了许多经典案例。 -
Python 装饰器用法实例总结第二节有简单的例子,解释符合开放封闭原则,降低多函数重复代码量和频繁改动,将非核心的日志记录功能和函数分离开,有利于保证核心业务代码的简洁和易理解性。
-
Python 装饰器 中经过用户验证场景不同解决方案的更迭来说明装饰器的优势。
使用装饰器@outer,也是仅需对基础平台的代码进行拓展,就可以实现在其他部门调用函数 API 之前都进行认证操作,在操作结束后保存日志,并且其他业务部门无需对他们自己的代码做任何修改,调用方式也不用变。
装饰器机制分析
本节摘自Python 装饰器 ,在其基础上补充更为直观的图示和流程图说明,文字描述可以详细查看原文章。
def outer(func):
def inner():
print("认证成功!")
result = func()
print("日志添加成功")
return result
return inner
@outer
def f1():
print("业务部门1数据接口......")
r = f1()
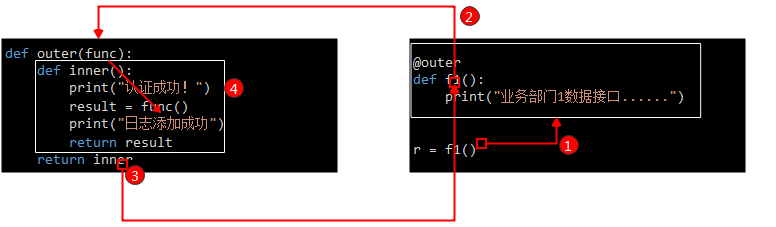

# 验证 inner 函数返回给 f1,即 f1 对象内存指向 inner内存
def outer(func):
print("传入实参内存地址:%d" %id(func))
def inner():
print("认证成功!")
result = func()
print("日志添加成功")
return result
print("Outer 内部函数 inner 内存地址:%d" %id(inner))
return inner
@outer
def f1():
print("业务部门1数据接口......")
print("装饰后 f1 函数内存地址:%d" %id(f1))
r = f1()
>>> 输出结果
传入实参内存地址:32354376
Outer 内部函数 inner 内存地址:32372632
装饰后 f1 函数内存地址:32372632
认证成功!
业务部门1数据接口......
日志添加成功
装饰器入门
本节摘自Python装饰器用法实例总结
1. 对带参数的函数进行装饰
内层函数进行改动传入我们的两个参数a和b,等价于use_logging(bar)(1,2)
def use_logging(func):
def _deco(a,b):
print("%s is running" % func.__name__)
func(a,b)
return _deco
@use_logging
def bar(a,b):
print('i am bar:%s'%(a+b))
bar(1,2)
2. 函数参数数量不确定
使用python的变长参数 *args和**kwargs 解决不定参数问题
def use_logging(func):
def _deco(*args,**kwargs):
print("%s is running" % func.__name__)
func(*args,**kwargs)
return _deco
@use_logging
def bar(a,b):
print('i am bar:%s'%(a+b))
@use_logging
def foo(a,b,c):
print('i am bar:%s'%(a+b+c))
bar(1,2)
foo(1,2,3)
3. 装饰器带参数
#! /usr/bin/env python
# -*- coding:utf-8 -*-
# __author__ = "TKQ"
def use_logging(level):
def _deco(func):
def __deco(*args, **kwargs):
if level == "warn":
print "%s is running" % func.__name__
return func(*args, **kwargs)
return __deco
return _deco
@use_logging(level="warn")
def bar(a,b):
print('i am bar:%s'%(a+b))
bar(1,3)
# 等价于use_logging(level="warn")(bar)(1,3)
4. functools.wraps - 还原函数原信息
使用装饰器极大地复用了代码,但是他有一个缺点就是原函数的元信息不见了,比如函数的docstring、name、参数列表
def use_logging(func):
def _deco(*args,**kwargs):
print("%s is running" % func.__name__)
func(*args,**kwargs)
return _deco
@use_logging
def bar():
print('i am bar')
print(bar.__name__)
bar()
#bar is running
#i am bar
#_deco
#函数名变为_deco而不是bar,这个情况在使用反射的特性的时候就会造成问题。因此引入了functools.wraps解决这个问题。
# 使用functools.wraps:
import functools
def use_logging(func):
@functools.wraps(func)
def _deco(*args,**kwargs):
print("%s is running" % func.__name__)
func(*args,**kwargs)
return _deco
@use_logging
def bar():
print('i am bar')
print(bar.__name__)
bar()
#result:
#bar is running
#i am bar
#bar ,这个结果是我们想要的。OK啦!
5. 实现带参数和不带参数的装饰器自适应
import functools
def use_logging(arg):
if callable(arg):#判断参入的参数是否是函数,不带参数的装饰器调用这个分支
@functools.wraps(arg)
def _deco(*args,**kwargs):
print("%s is running" % arg.__name__)
arg(*args,**kwargs)
return _deco
else:#带参数的装饰器调用这个分支
def _deco(func):
@functools.wraps(func)
def __deco(*args, **kwargs):
if arg == "warn":
print "warn%s is running" % func.__name__
return func(*args, **kwargs)
return __deco
return _deco
@use_logging("warn")
# @use_logging
def bar():
print('i am bar')
print(bar.__name__)
bar()
6. 类装饰器
使用类装饰器可以实现带参数装饰器的效果,但实现的更加优雅简洁,而且可以通过继承来灵活的扩展.
class loging(object):
def __init__(self,level="warn"):
self.level = level
def __call__(self,func):
@functools.wraps(func)
def _deco(*args, **kwargs):
if self.level == "warn":
self.notify(func)
return func(*args, **kwargs)
return _deco
def notify(self,func):
# logit只打日志,不做别的
print "%s is running" % func.__name__
@loging(level="warn") #执行__call__方法
def bar(a,b):
print('i am bar:%s'%(a+b))
bar(1,3)
继承扩展类装饰器
class email_loging(Loging):
'''
一个loging的实现版本,可以在函数调用时发送email给管理员
__init__ :不再接收被装饰函数,而是接收传入参数。
__call__ :接收被装饰函数,实现装饰逻辑。
'''
def __init__(self, email='admin@myproject.com', *args, **kwargs):
self.email = email
super(email_loging, self).__init__(*args, **kwargs)
def notify(self,func):
# 发送一封email到self.email
print "%s is running" % func.__name__
print "sending email to %s" %self.email
@email_loging(level="warn")
def bar(a,b):
print('i am bar:%s'%(a+b))
bar(1,3)
arvin_feng
装饰器应用场景
该节摘抄记录自文章Python装饰器的应用场景,文章Python装饰器的应用场景
类型检查
from functools import wraps
def require_ints(func):
@wraps(func) # 将func的信息复制给inner
def inner(*args, **kwargs):
for arg list(args) + list(kwargs.values()):
if not isinstance(arg, int:
raise TypeError("{} 只接受int类型参数".format(func.__name__)
return func(*args, **kwargs)
return inner
用户验证
定义了装饰器 authenticate,函数 post_comment() 则表示发表用户对某篇文章的评论,每次调用这个函数前,都会先检查用户是否处于登录状态,如果是登录状态,则允许这项操作;如果没有登录,则不允许。
import functools
def authenticate(func):
@functools.wraps(func)
# @functools.wraps(func) 也是一个装饰器,
# 不使用它,则 post_comment.__name__ 的值为 wrapper。
# 使用它之后,则 post_comment.__name__ 的值依然为 post_comment。
def wrapper(*args, **kwargs):
request = args[0]
# 如果用户处于登录状态
if check_user_logged_in(request):
# 执行函数 post_comment()
return func(*args, **kwargs)
else:
raise Exception('Authentication failed')
return wrapper
@authenticate
def post_comment(request, ...)
...
输入合理性检查
在大型公司的机器学习框架中,调用机器集群进行模型训练前,往往会用装饰器对其输入(往往是很长的 json 文件)进行合理性检查。这样就可以
- 大大避免输入不正确对机器造成的巨大开销。其实在工作中,很多情况下都会出现输入不合理的现象。因为我们调用的训练模型往往很复杂,输入的文件有成千上万行,很多时候确实也很难发现。
- 如果没有输入的合理性检查,很容易出现“模型训练了好几个小时后,系统却报错说输入的一个参数不对,成果付之一炬”的现象。这样的“惨案”,大大减缓了开发效率,也对机器资源造成了巨大浪费。
import functools
def validation_check(input):
@functools.wraps(func)
def wrapper(*args, **kwargs):
... # 检查输入是否合法
@validation_check
def neural_network_training(param1, param2, ...):
...
输出格式化
import json
from functools import wraps
def json_output(func): # 将原本func返回的字典格式转为返回json字符串格式
@wrap(func)
def inner(*args, **kwargs):
return json.dumps(func(*args, **kwargs))
return inner
异常捕获
import json
from functools import wraps
class Error1(Exception):
def __init__(self, msg):
self.msg = msg
def __str__(self):
return self.msg
def json_output(func):
@wrap(func)
def inner(*args, **kwargs):
try:
result = func(*args, **kwargs)
except Error1 as ex:
result = {"status": "error", "msg": str(ex)}
return json.dumps(result)
return inner
# 使用方法
@json_ouput
def error():
raise Error1("该条异常会被捕获并按JSON格式输出")
日志管理
测试函数耗时,装饰器方式秉持开放封闭原则,无需调增函数体内部,而是通过外部封装方式,减少耦合。
import time
import logging
from functools import wraps
def logged(func):
@wraps(func)
def inner(*args, **kwargs): # *args可以装饰函数也可以装饰类
start = time.time()
result = func(*args, **kwargs)
exec_time = time.time() - start
logger = logging.getLoger("func.logged")
logger.warning("{} 调用时间:{:.2} 执行时间:{:.2}s 结果:{}".format(func.__name__, start, exec_time, result)
def calculate_similarity(items):
...
缓存装饰器
关于缓存装饰器的用法,其实十分常见,这里以 Python 内置的 LRU cache 为例来说明。LRU cache,在 Python 中的表示形式是 @lru_cache。@lru_cache 会缓存进程中的函数参数和结果,当缓存满了以后,会删除最近最久未使用的数据。
正确使用缓存装饰器,往往能极大地提高程序运行效率。举个例子,大型公司服务器端的代码中往往存在很多关于设备的检查,比如使用的设备是安卓还是 iPhone,版本号是多少。这其中的一个原因,就是一些新的功能,往往只在某些特定的手机系统或版本上才有。这样一来,我们通常使用缓存装饰器来包裹这些检查函数,避免其被反复调用,进而提高程序运行效率,比如写成下面这样:
@lru_cache
def check(param1, param2, ...) # 检查用户设备类型,版本号等等
...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号