BP神经网络个人理解(理论+实例)
对于BP神经网络,本文将从简介(神经网络以及前馈神经网络概念)、激活函数、正向传播、反向传播这几个方面做出简要描述。 首先来看一下神经网络的简介。
神经网络概念
神经网络是一种运算模型,由大量的节点(或称为神经元)之间相互联接构成。在感知机的基础上发展出来。每个节点代表一种特定的输出函数,称为激励函数(activation function)。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。 神经网络的提出也是得益于生物神经网络的思考,模拟生物大脑的网络处理方式。在生物神经网络中,每个神经元之间互联,当神经元接收了外部的输入,其神经元电位处于较高时,神经元会处于“兴奋”状态时会向其他神经元传递化学物质。而人工神经网络正是出于这种思考,我们假设每个神经元电位高于某个“阈值”时会处于兴奋,则对于每个神经元,如图所示,我们可以通过将神经元的输入的线性组合量减去该阈值化作为函数变量的函数来量化是否处于兴奋状态,这个函数我们常常称之为激活函数。而这个模型在业界称为“M-P神经元模型”。
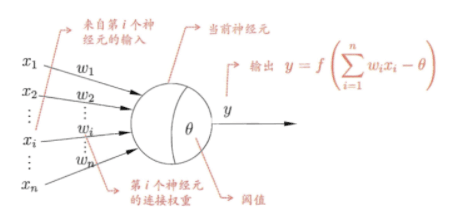
常见的激活函数
1.sigmod函数 $$f(z)=\frac{1}{1+exp(-z)}$$ 一般用于BP神经网络,求导较为简单,其导数是f(z)*(1-f(z)),计算梯度较为方便,但其也有梯度消失等缺点。$$$$ 2.Tanh函数 $$f(z)=tanh(z)=\frac{exp(z)-exp(-z)}{exp(z)+exp(-z)}$$ 一般用于RNN循环神经网络。$$$$ 3.Relu函数 f(z)=max(0,x)$$$$ 一般用于CNN卷积神经网络。因其大于0时导数为其本身,梯度消失问题可以缓解。
前馈神经网络
前馈神经网络采用一种单向多层结构。其中每一层包含若干个神经元,同一层的神经元之间没有互相连接,层间信息的传送只沿一个方向进行。其中第一层称为输入层。最后一层为输出层。中间为隐含层,简称隐层。隐层可以是一层,也可以是多层。将单个神经元以一定的层次结构连接起来就得到神经网络。 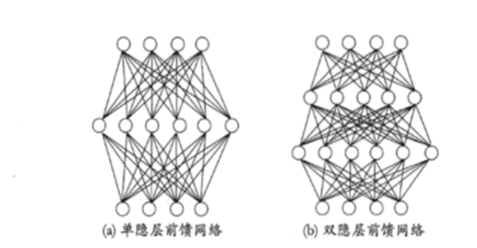
BP神经网络
对于多层神经网络的学习,我们通常通过误差逆传播(error BackPropagation,简称BP)算法进行学习。误差逆传播算法适用于多种神经网络,例如常见的多层前馈神经网络,递归神经网络等。
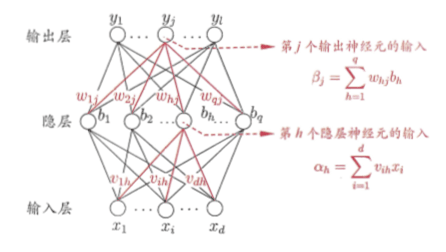
为了全面了解BP神经网络的过程,我们先从理论推导一下,进而从实例来走一遍BP神经网络的过程。 我们判定一个网络的好坏,一般需要一定的误差函数来判断网络预测结果与实际结果的差距。 一般常用的误差函数是均方误差:Ek=½∑(Ý-Y)2
BP算法基于梯度下降策略,以目标负梯度方向对参数进行训练,对于误差Ek,对于给定学习率η,以目标的负梯度方向对参数进行调整,有
$$Δw=-η\frac{∂EK}{∂w}$$ 根据链式求偏导(一层一层求偏导),有 $$\frac{∂EK}{∂wj}=\frac{∂EK}{∂Ýj}*\frac{∂Ýj}{∂βj}*\frac{∂βj}{∂wj}$$ $$\frac{∂EK}{∂bj}=\frac{∂EK}{∂Ýj}*\frac{∂Ýj}{∂βj}*\frac{∂βj}{∂bj}$$ 可能看公式优点复杂,直接举例子。
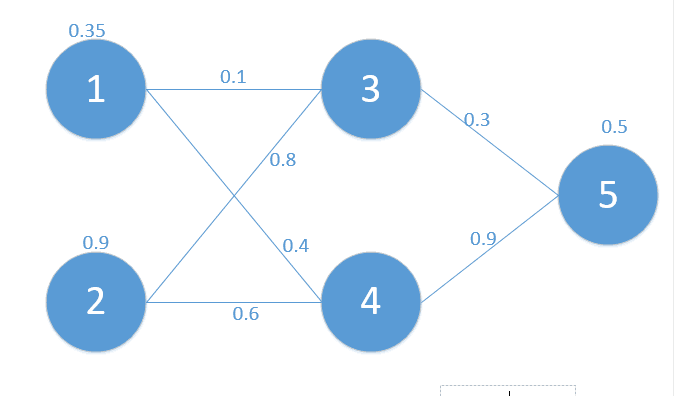
三层网络,输入值[0.35,0.9],实际输出值[0.5],边上的数值都是权值w。 我们都知道,一个神经元,都有输入和输出,输入是未通过激活函数的数值,输出是激活函数后的数值。令z为该结点神经元的输入,y为输出,δ为误差,激活函数为sigmod函数,w代表边上的权值。 初始矩阵 $$x=z0=\bigl(\begin{smallmatrix} \\ 0.35&0.9\end{smallmatrix}\bigr)$$ yout=0.5 $$w0=\begin{bmatrix} & \\w31&w32 & \\w41&w42 \end{bmatrix}=\begin{bmatrix} & \\0.1&0.8 & \\0.4&0.6 \end{bmatrix}$$ $$w1=\bigl(\begin{smallmatrix} \\ w53&w54\end{smallmatrix}\bigr)=\bigl(\begin{smallmatrix} \\ 0.3&0.9\end{smallmatrix}\bigr)$$
我们先走一遍前向传播 $$z1=w0*x=\begin{bmatrix} \\0.1*0.35+0.8*0.9&0.4*0.35+0.6*0.9\end{bmatrix}=\begin{bmatrix} \\z3&z4 \end{bmatrix}=\begin{bmatrix} \\0.755&0.68 \end{bmatrix}$$ $$y1=f(z1)=\begin{bmatrix} \\y3&y4 \end{bmatrix}=\begin{bmatrix} \\0.680&0.663 \end{bmatrix}$$ 同理可得, $$z5=w1*y1=\bigl(\begin{smallmatrix} 0.801\end{smallmatrix}\bigr)$$最终损失E=1/2*(0.69-0.5)2=0.01805
我们当然希望损失越小越好,于是进行反向传播来调节w,实际上反向传播就是梯度下降法中链式法则的使用。
根据公式:
E=1/2*(y5-yout)2
y5=f(z5)
z5=(w53*y3)
这时我们需求出E对w的偏导,根据链式法则:
同理,依次求出
再按照这个权重参数进行一遍正向传播得出来的Error为0.165,而这个值比原来的0.19要小,迭代更新100次,最后权值为
除此之外,我们还会有一个问题,为什么要沿着梯度的反方向更新参数?
答:因为我们的目标是使损失函数值最小,而梯度的方向是函数值增加最快的方向,因此要沿着梯度的反方向更新参数。
这其中涉及到方向函数Duf(x,y)=fx(x,y)cosθ+fy(x,y)sinθ{到时候再详细写一下我对方向函数的理解}
设A=(fx(x,y),fy(x,y)),I=(cosθ,sinθ)
那么我们可以得到:
Duf(x,y)=AI=|A||I|cosα(α为向量A与向量I之间的夹角)
得出结论:
当α=0时,即A和I的方向相同时,Duf(x,y)取最大值,函数在这个方向的增加最快。
当α= π时,即A和I的方向相同时,Duf(x,y)取最小值,函数在这个方向的减小最快。
参考:[1]刘建平Pinard:深度神经网络(DNN)反向传播算法(BP)http://www.cnblogs.com/pinard/p/6422831.html#
[2]全连接神经网络中反向传播算法数学推导https://zhuanlan.zhihu.com/p/61863634

 浙公网安备 33010602011771号
浙公网安备 33010602011771号