cifar10数据集解压缩,按标签分文件夹
描述
数据集来自http://www.cs.toronto.edu/~kriz/cifar.html python版,下载后解压缩:
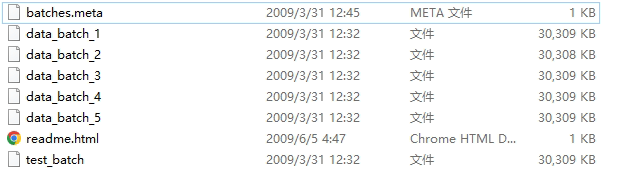
然后在该目录下执行python,运行后效果:
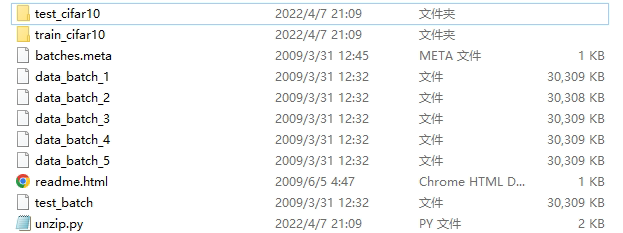
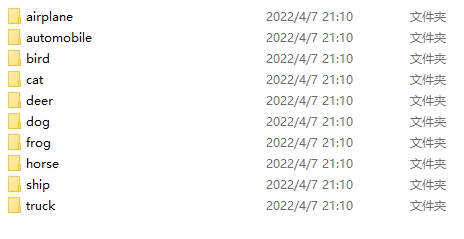
代码
import pickle
import numpy as np
import os
import cv2
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
loc_1 = './train_cifar10'
loc_2 = './test_cifar10'
if not os.path.exists(loc_1):
os.mkdir(loc_1)
if not os.path.exists(loc_2):
os.mkdir(loc_2)
def unzip():
meta = unpickle('batches.meta')
label_names = meta[b'label_names']
for i in label_names:
dir1 = loc_1 + '/' + i.decode()
dir2 = loc_2 + '/' + i.decode()
if not os.path.exists(dir1):
os.mkdir(dir1)
if not os.path.exists(dir2):
os.mkdir(dir2)
for i in range(1,6):
data_name = 'data_batch_' + str(i)
data = unpickle(data_name)
for j in range (10000):
img = np.reshape(data[b'data'][j], (3, 32, 32))
img = np.transpose(img, (1, 2, 0))
label = label_names[data[b'labels'][j]].decode()
img_name = label + '_' + str(i*10000 + j) + '.jpg'
img_save_path = loc_1 + '/' + label + '/' + img_name
cv2.imwrite(img_save_path, img)
print(data_name + ' finished')
test_data = unpickle('test_batch')
for i in range (10000):
img = np.reshape(test_data[b'data'][i], (3, 32, 32))
img = np.transpose(img, (1, 2, 0))
label = label_names[test_data[b'labels'][i]].decode()
img_name = label + '_' + str(i) + '.jpg'
img_save_path = loc_2 + '/' + label + '/' + img_name
cv2.imwrite(img_save_path, img)
print('test_batch finished')
if __name__ == '__main__':
unzip()
PS: imwrite保存失败居然不提示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号