【原创】关于skip-gram的个人理解
★skip-gram的关键术语与详细解释:
【语料】——
所有句子文档(当然会出现大量重复的单词)
【词典(可用V维的onehot编码来表示)】——
语料中出现的所有单词的集合(去除了重复词)
【窗口大小(上下文词语数量m)】——
即指定中心词后我们关注的上下文数量定为该中心词前m个词和后m个词(一共2m个上下文词)。
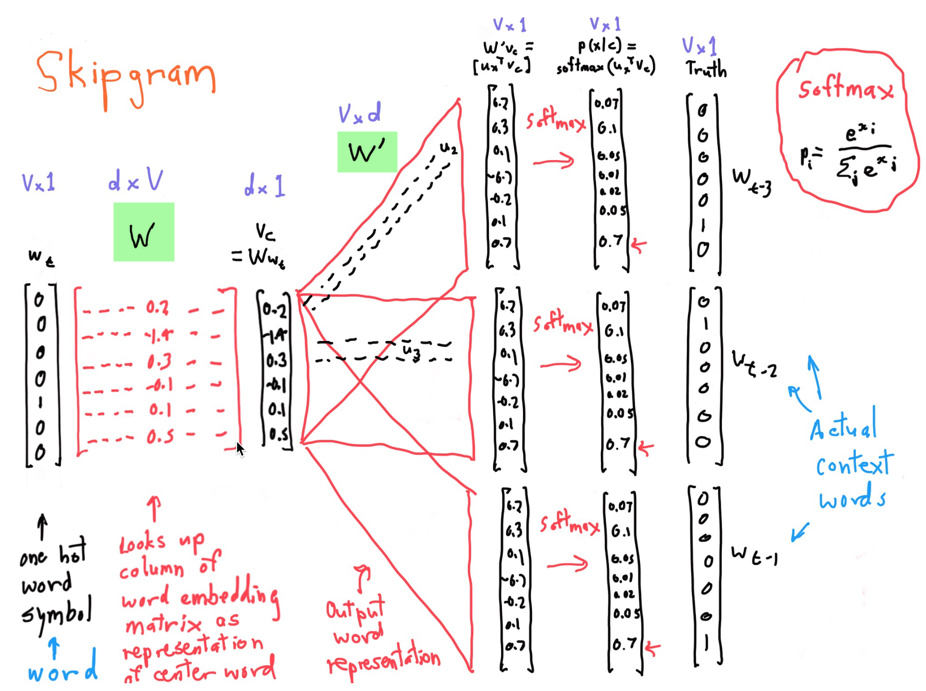
【词典中心词向量矩阵(下图d×V维的W矩阵)】——
通俗来说词典中心词向量矩阵是由词典中的一个单词的词向量组合而成的(每一列就是词典中的一个单词的词向量),而每一个词的词向量就是假设我们的词典包含了d个维度的抽象信息。
这d个维度储存的抽象信息:从模型的角度来说就是作为中心词而言,它与上下文会出现词之间的对应关系信息,从语言学的角度来说这样的对应关系也很大程度上反映了词性、语义、句法特征方面的信息。
【词典上下文词向量矩阵(下图的V×d维的W'矩阵)】——
类似词典中心词向量矩阵,但这里的词向量中d个维度储存的抽象信息,是作为上下文的词而言,它与中心词之间的对应关系信息。
【最后Softmax归一化后输出的概率向量(下图p(x|c)】——
就是词典中每个词成为当前指定中心词的上下文的概率。我们要让这个概率向量,逼近真实语料中基于指定中心词基础上这些上下文词语出现的条件概率分布。
Skip-gram每一轮指定一个中心词的2m个上下文词语来训练该中心词词向量和词典上下文词向量,下一轮则指定语料中下一个中心词,查看其2m个上下文词语来训练。
如果下一轮出现了之前出现过的中心词,之前那一轮可能着重训练的是中心词词向量和词典上下文词向量的几个维度值(关系信息),但由于这一轮是另外一个语境(上下文的2m个词有差异),所以这一轮着重训练的可能就是词向量中的另外几个维度值(关系信息),与之前的不一样。
★skip-gram的核心:
通过查看所有语料的词作为中心词时,其(中心词)与上下文的2m个词语的所有共现情况,这样就得到我们要逼近的中心词与上下文对应关系的条件概率分布(这个概率分布是忽视掉了上下文词语间的顺序的),我们通过模型去训练出词典中心词向量矩阵和词典上下文词向量矩阵(这两个矩阵就是存储了语料中中心词与其上下文的对应关系信息)。
I'm coming back!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号