
使用python的pdfminer库提取pdf中的图像之填坑记
本地环境:win10 x64,python3.8 x64
安装:pip install pdfminer
使用:
按照官方给的方法使用一波,发现windows下没给适配,运行pdf2txt.py直接弹出来编辑器编辑源代码了,需要用python+绝对路径+参数的方法调用
python (gcm pdf2txt.py).source -o outputfilename -O output_dir input.pdf
- -o:输出文件名,可以通过文件拓展命指定转换目标类型
- -O:输出资源目录,比如转换成HTML文件,图片文件存放目录就在这里指定
跑一波
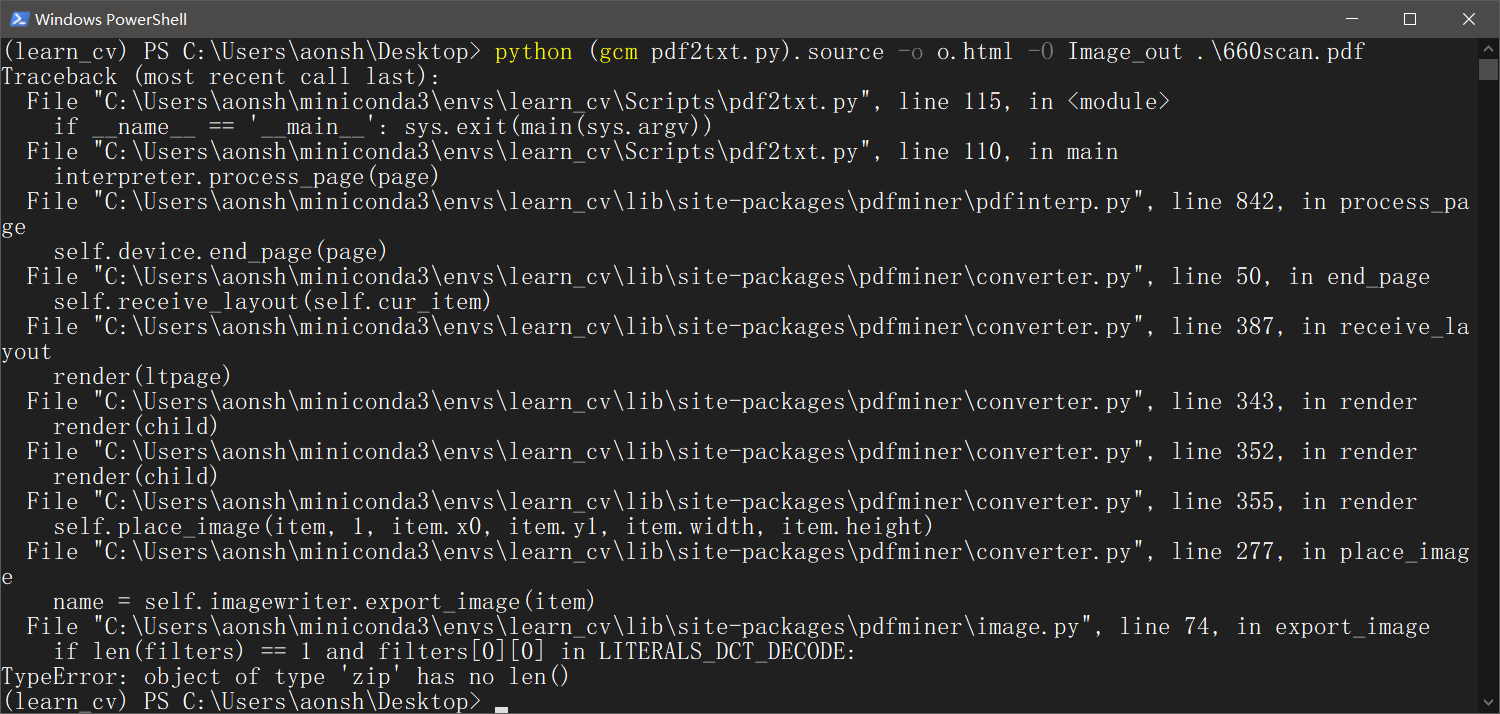
直接跑不通可还行,找来源代码瞅瞅

看对filter调用的方法,filter应该是个list,直接 filters = stream.get_filters() 修改为 filters = list(stream.get_filters())
再试一波,这波没报错。
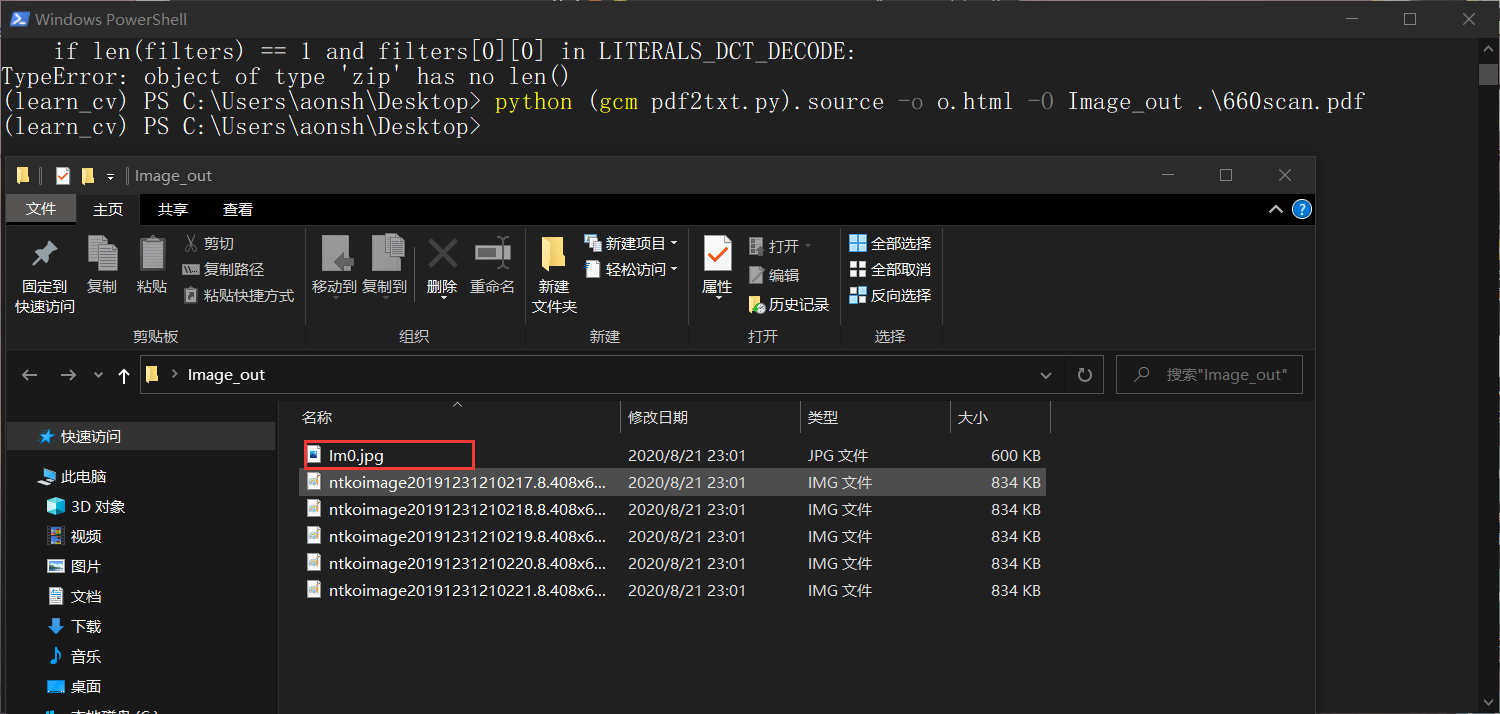
但是输出的文件夹里只有一张图,我pdf里上百张图都去哪里了???
打开唯一的图片发现是最后一张图,盲猜一波pdf文件中的图片都是这个名字,pdf2txt在解析抽取图像的时候,只是简单的用图像在pdf里的名字保存,导致每次保存一张重名图像都会把老图替换掉。
刚刚出错的文件名叫image.py应该是和图像处理相关的,应该能找到图像保存的逻辑。

果然!
在这里给文件名加个递增前缀应该能解决问题。
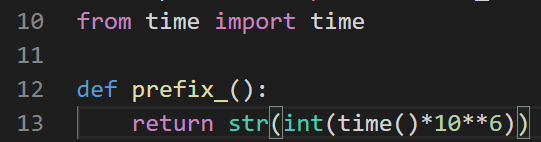
定义一个生成递增前缀滴函数,并在产生文件名时加上这个前缀
from time import time def prefix_(): return str(int(time()*10**6))
name = f'{prefix_()}_{image.name}.{ext}'

再跑一次

可以看到该有的都有了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号