
卷积神经网络物体检测之感受野大小计算
学习RCNN系列论文时, 出现了感受野(receptive field)的名词, 感受野的尺寸大小是如何计算的,在网上没有搜到特别详细的介绍, 为了加深印象,记录下自己对这一感念的理解,希望对理解基于CNN的物体检测过程有所帮助。
1 感受野的概念
在卷积神经网络中,感受野的定义是 卷积神经网络每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小。

RCNN论文中有一段描述,Alexnet网络pool5输出的特征图上的像素在输入图像上有很大的感受野(have very large receptive fields (195 × 195 pixels))和步长(strides (32×32 pixels) ), 这两个变量的数值是如何得出的呢?
2 感受野大小的计算
感受野计算时有下面的几个情况需要说明:
(1)第一层卷积层的输出特征图像素的感受野的大小等于滤波器的大小
(2)深层卷积层的感受野大小和它之前所有层的滤波器大小和步长有关系
(3)计算感受野大小时,忽略了图像边缘的影响,即不考虑padding的大小,关于这个疑惑大家可以阅读一下参考文章2的解答进行理解
这里的每一个卷积层还有一个strides的概念,这个strides是之前所有层stride的乘积。
即strides(i) = stride(1) * stride(2) * ...* stride(i-1)
关于感受野大小的计算采用top to down的方式, 即先计算最深层在前一层上的感受野,然后逐渐传递到第一层,使用的公式可以表示如下:
RF = 1 #待计算的feature map上的感受野大小
for layer in (top layer To down layer):
RF = ((RF -1)* stride) + fsize
stride 表示卷积的步长; fsize表示卷积层滤波器的大小
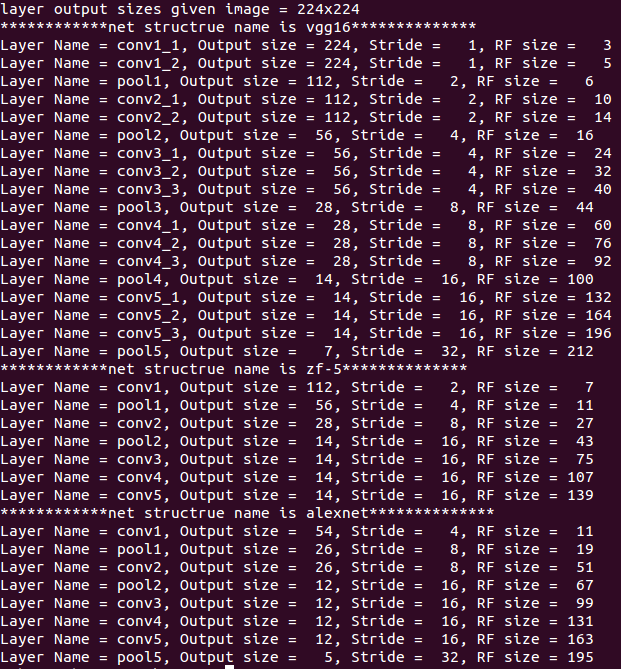
用python实现了计算Alexnet zf-5和VGG16网络每层输出feature map的感受野大小,实现代码:


#!/usr/bin/env python net_struct = {'alexnet': {'net':[[11,4,0],[3,2,0],[5,1,2],[3,2,0],[3,1,1],[3,1,1],[3,1,1],[3,2,0]], 'name':['conv1','pool1','conv2','pool2','conv3','conv4','conv5','pool5']}, 'vgg16': {'net':[[3,1,1],[3,1,1],[2,2,0],[3,1,1],[3,1,1],[2,2,0],[3,1,1],[3,1,1],[3,1,1], [2,2,0],[3,1,1],[3,1,1],[3,1,1],[2,2,0],[3,1,1],[3,1,1],[3,1,1],[2,2,0]], 'name':['conv1_1','conv1_2','pool1','conv2_1','conv2_2','pool2','conv3_1','conv3_2', 'conv3_3', 'pool3','conv4_1','conv4_2','conv4_3','pool4','conv5_1','conv5_2','conv5_3','pool5']}, 'zf-5':{'net': [[7,2,3],[3,2,1],[5,2,2],[3,2,1],[3,1,1],[3,1,1],[3,1,1]], 'name': ['conv1','pool1','conv2','pool2','conv3','conv4','conv5']}} imsize = 224 def outFromIn(isz, net, layernum): totstride = 1 insize = isz for layer in range(layernum): fsize, stride, pad = net[layer] outsize = (insize - fsize + 2*pad) / stride + 1 insize = outsize totstride = totstride * stride return outsize, totstride def inFromOut(net, layernum): RF = 1 for layer in reversed(range(layernum)): fsize, stride, pad = net[layer] RF = ((RF -1)* stride) + fsize return RF if __name__ == '__main__': print "layer output sizes given image = %dx%d" % (imsize, imsize) for net in net_struct.keys(): print '************net structrue name is %s**************'% net for i in range(len(net_struct[net]['net'])): p = outFromIn(imsize,net_struct[net]['net'], i+1) rf = inFromOut(net_struct[net]['net'], i+1) print "Layer Name = %s, Output size = %3d, Stride = % 3d, RF size = %3d" % (net_struct[net]['name'][i], p[0], p[1], rf)
执行后的结果如下:
参考:
1 http://stackoverflow.com/questions/35582521/how-to-calculate-receptive-field-size
4 Convolutional Feature Maps: Elements of Efficient (and Accurate) CNN-based Object Detection
5 Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
6 http://blog.cvmarcher.com/posts/2015/05/17/cnn-trick/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号