记一次 Kafka 集群线上扩容
前段时间收到某个 Kafka 集群的生产客户端反馈发送消息耗时很高,于是花了一段时间去排查这个问题,最后该集群进行扩容,由于某些主题的当前数据量实在太大,在对这些主题迁移过程中话费了很长一段时间,不过这个过程还算顺利,因为在迁移过程中也做足了各方面的调研,包括分区重平衡过程中对客户端的影响,以及对整个集群的性能影响等,特此将这个过程总结一下,也为双十一打了一剂强心剂。
排查问题与分析
接到用户的反馈后,我用脚本测试了一遍,并对比了另外一个正常的 Kafka 集群,发现耗时确实很高,接下来
经过排查,发现有客户端在频繁断开与集群节点的连接,发现日志频繁打印如下内容:
Attempting to send response via channel for which there is no open connection, connection id xxx(kafka.network.Processor)
定位到源码位置:
kafka.network.Processor#sendResponse:

看源码注释,是远程连接关闭了或者空闲时间太长了的意思,找到具体客户端负责人,经询问后,这是大数据 Spark 集群的节点。

从以上日志看出,Spark 集群的某个消费组 OrderDeliveryTypeCnt,竟然发生了近 4 万次重平衡操作,这显然就是一个不正常的事件,Kafka 消费组发生重平衡的条件有以下几个:
- 消费组成员发生变更,有新消费者加入或者离开,或者有消费者崩溃;
- 消费组订阅的主题数量发生变更;
- 消费组订阅的分区数发生变更。
很显然第 2、3 点都没有发生,那么可以断定,这是 Spark集群节点频繁断开与kafka的连接导致消费组成员发生变更,导致消费组发生重平滑。
那为什么 Spark 集群会产生频繁断开重连呢?
查看 Spark 集群用的 Kafka 版本还是 0.10.1.1 版本,而 Kafka 集群的版本为 2.2.1,一开始以为是版本兼容问题,接着数据智能部的小伙伴将 Spark 集群连接到某个版本为 0.11.1.1 的 Kafka 集群,使用 8 个 Spark 任务消费进行消费,同样发现了连接断开的问题。说明此问题是由于 Spark 内部消费 Kafka 机制导致的,和 kafka 版本关系不大。
经过几番跟大数据的人员讨论,这个频繁重平衡貌似是 Spark 2.3 版本内部机制导致的,Spark 2.4 版本没有这个问题存在。
由于这个频繁断开重连,并不是开发人员开发过程中导致的,考虑到双十一临近,不能贸然升级改动项目,那么现在最好的方案就是对集群进行水平扩展,增加集群的负载能力,并对专门的主题进行分区重分配。
分区重分配方案的分析
目前集群一共有 6 个节点,扩容以 50% 为基准,那么需要在准备 3 个节点,在运维准备好机器并且将其加入到集群中后,接下来就要准备对主题进行分区重分配的策略文件了。
在执行分区重分配的过程中,对集群的影响主要有两点:
- 分区重分配主要是对主题数据进行 Broker 间的迁移,因此会占用集群的带宽资源;
- 分区重分配会改变分区 Leader 所在的 Broker,因此会影响客户端。
针对以上两点,第 1 点可以在晚间进行(太苦逼了,记得有个主题数据迁移进行了将近5小时),针对第二点,我想到了两个方案:
- 整个分配方案分成两个步骤:1)手动生成分配方案,对原有的分区 Leader 位置不改变,只对副本进行分区重分配;2)等待数据迁移完成后,再手动更改分区分配方案,目的是均衡 Leader。
- 直接用 Kafka 提供的 API 生成 分区重分配方案,直接执行分区重分配。
第一个方案理论上是对客户端影响最小的,把整个分配方案分成了两个步骤,也就是将对集群的带宽资源与客户端的影响分开了,对过程可控性更高了,但问题来了,集群中的某些主题,有 64 个分区,副本因子为 3,副本一共有 192 个,你需要保持原有分区 Leader 位置不变的情况下,去手动均衡其余副本,这个考验难度真的太大了,稍微有一点偏差,就会造成副本不均衡。
因此我特意去看了分区重分配的源码,并对其过程进行了进一步分析,发现分配重分配的步骤是将分区原有的副本与新分配的副本的集合,组成一个分区副本集合,新分配的副本努力追上 Leader 的位移,最终加入 ISR,待全部副本都加入 ISR 之后,就会进行分区 Leader 选举,选举完后就会将原有的副本删除,具体细节我会单独写一篇文章。
根据以上重分配的步骤,意味着在数据进行过程中不会发生客户端阻塞,因为期间 Leader 并没有发生变更,在数据迁移完成进行 Leader 选举时才会,但影响不大,针对这点影响我特意用脚本测试了一下:

可以发现,在发送过程中,如果 Leader 发生了变更,生产者会及时拉取最新的元数据,并重新进行消息发送。
针对以上的分析与测试,我们决定采取第二种方案,具体步骤如下:
- 对每个主题生成分配分区分配策略:执行时间段(10:00-17:00),并对分配策略进行检查,并保存执行的 topic1_partition_reassignment.json 文件,并把原来的方案保存到topic1_partition_reassignment_rollback.json 文件中,以备后续的 rollback 操作;
- 执行分配策略:执行时间段(00:30-02:30),准备好的 topic1_partition_reassignment.json 文件,执行完再验证并查看副本分配情况,每执行一个分配策略都要查看 ISR 收缩扩张状况、消息流转状况,确定没问题后再执行下一个分配策略;
- 由于集群 broker 端的参数
auto.leader.rebalance.enable=true,因此会自动执行 Preferred Leader 选举,默认时间间隔为 300 秒,期间需要观察 Preferred Leader 选举状况。
分区重分配
对于新增的 Broker,Kafka 是不会自动地分配已有主题的负载,即不会将主题的分区分配到新增的 Broker,但我们可以通过 Kafka 提供的 API 对主题分区进行重分配操作,具体操作如下:
- 生成需要执行分区重分配的主题列表 json 文件:
echo '{"version":1,"topics":[{"topic":"sjzn_spark_binlog_order_topic"}]}' > sjzn_spark_binlog_order_topic.json
- 生成主题的分配方案:
bin/kafka-reassign-partitions.sh --zookeeper --zookeeper xxx.xxx.xx.xxx:2181,xxx.xxx.xx.xxx:2181,xxx.xxx.xx.xxx:2181 --topics-to-move-json-file sjzn_spark_binlog_order_topic.json --broker-list "0,1,2,3,4,5,6,7,8" --generate
由于主题的有64个分区,每个分区3个副本,生成的分配数据还是挺大的,这里就不一一贴出来了
- 将分配方案保存到一个 json 文件中:
echo '{"version":1,"partitions":[{"topic":"sjzn_spark_binlog_order_topic","partition":59,"replicas":[4,8,0],"log_dirs":["any","any","any"]} ......' > sjzn_spark_binlog_order_topic_reassignment.json
- 执行分区重分配:
bin/kafka-reassign-partitions.sh --zookeeper xxx.xxx.xx.xxx:2181,xxx.xxx.xx.xxx:2181,xxx.xxx.xx.xxx:2181 --reassignment-json-file sjzn_spark_binlog_order_topic_reassignment.json --execute
- 验证分区重分配是否执行成功:
bin/kafka-reassign-partitions.sh --zookeeper xxx.xxx.xx.xxx:2181,xxx.xxx.xx.xxx:2181,xxx.xxx.xx.xxx:2181 --reassignment-json-file sjzn_spark_order_unique_topic_resign.json --verify
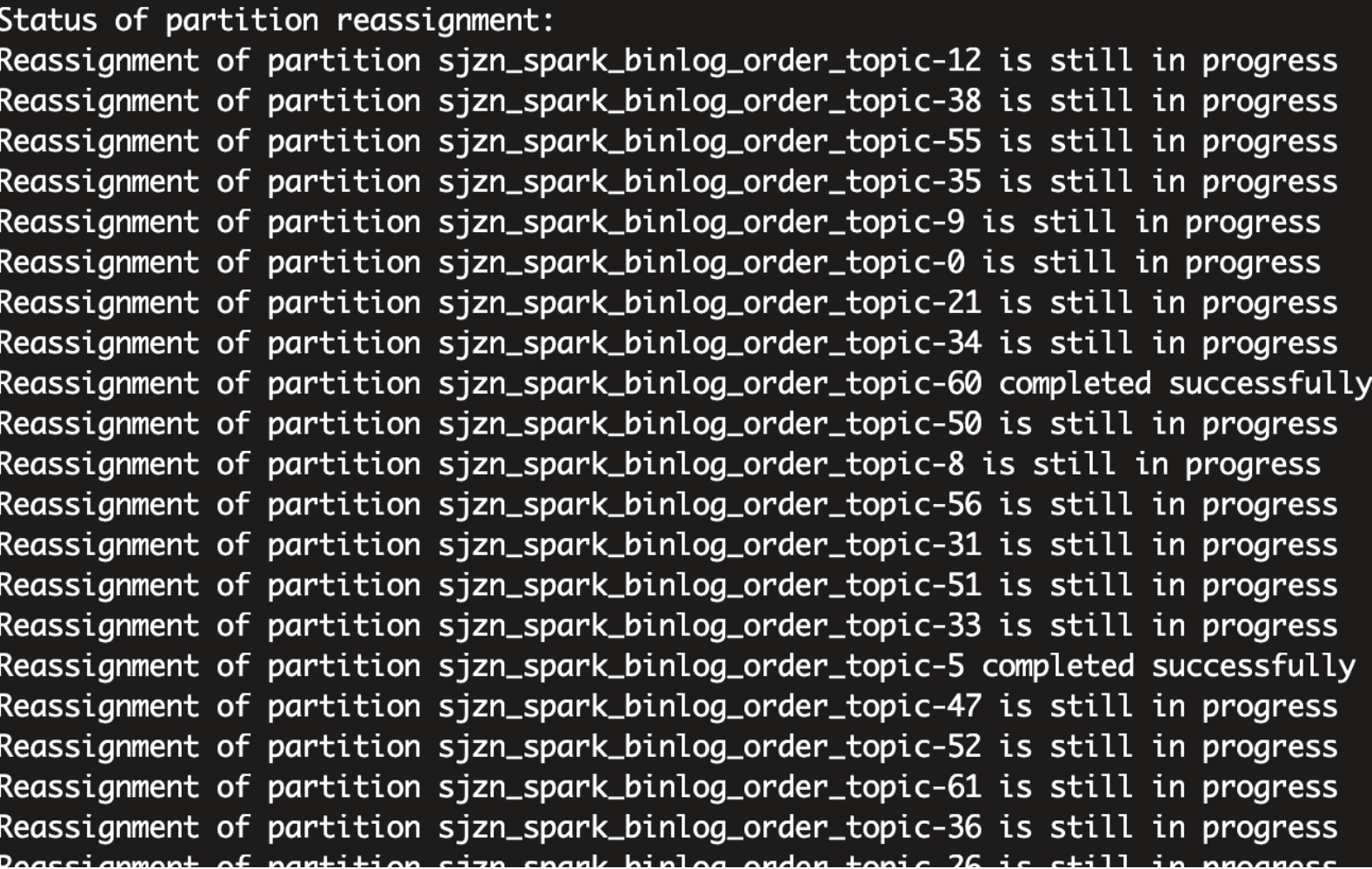
由于该主题存在的数据量特别大,整个重分配过程需要维持了好几个小时:
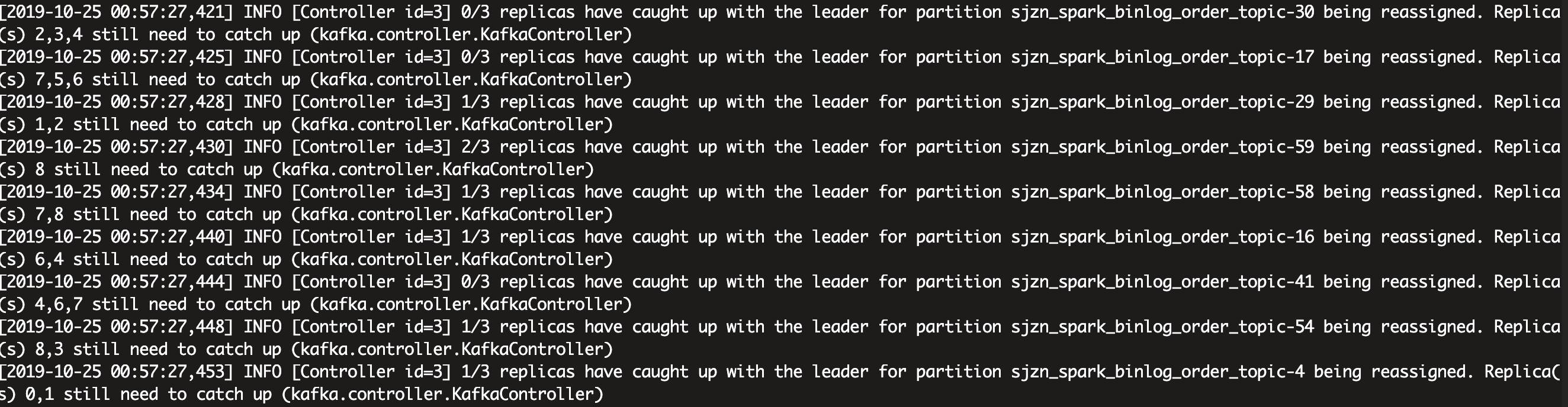
在它进行数据迁移过程中,我特意去 kafka-manage 控制台观察了各分区数据的变动情况:
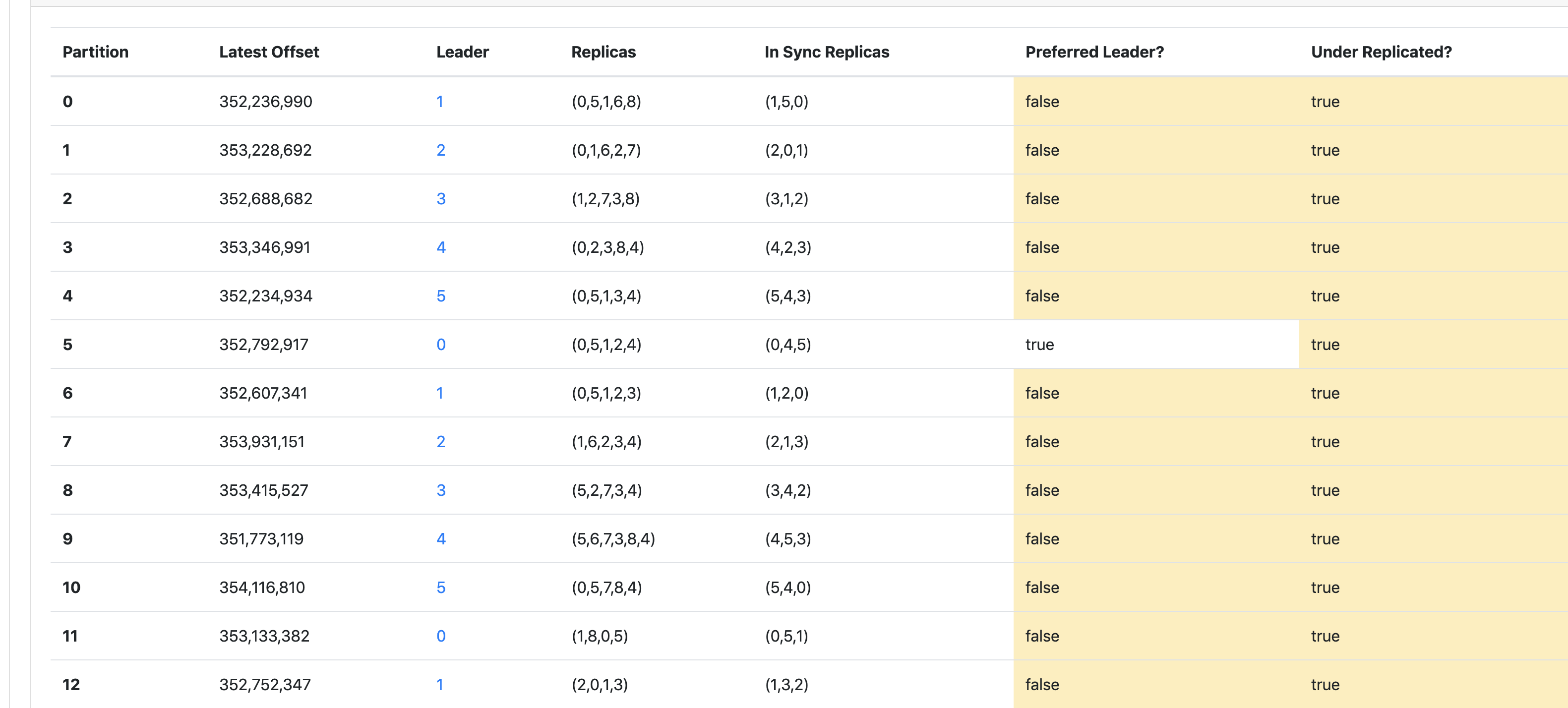
从控制台可看出,各分区的副本数目基本都增加了,这也印证了分区当前的副本数等于原有的副本加上新分配的副本的集合,新分配的副本集合目前还没追上 Leader 的位移,因此没有加入 ISR 列表。
有没有注意到一点,此时各分区的 Leader 都不在 Preferred Leader 中,因此后续等待新分配的副本追上 ISR 后,会进行新一轮的 Preferred Leader 选举,选举的细节实现我会单独写一篇文章去分析,敬请期待。
过一段时间后,发现位移已经改变了:

从这点也印证了在分区重分配过程中,只要 Leader 没有发生变更,客户端是可以持续发送消息给分区 Leader 的。
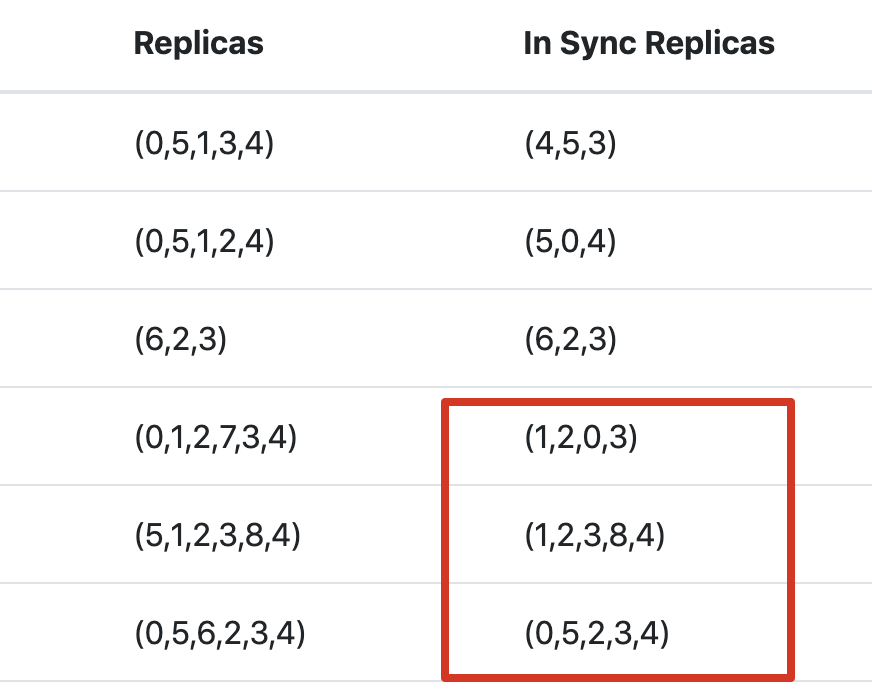
从上图可看出,新分配的副本追上 Leader 的位移后,就会加入 ISR 列表中。
现在去看看集群带宽负载情况:


从上图中可看出,在迁移过程中,新分配的副本不断地从 Leader 拉取数据,占用了集群带宽。
主题各分区重分配完成后的副本情况:
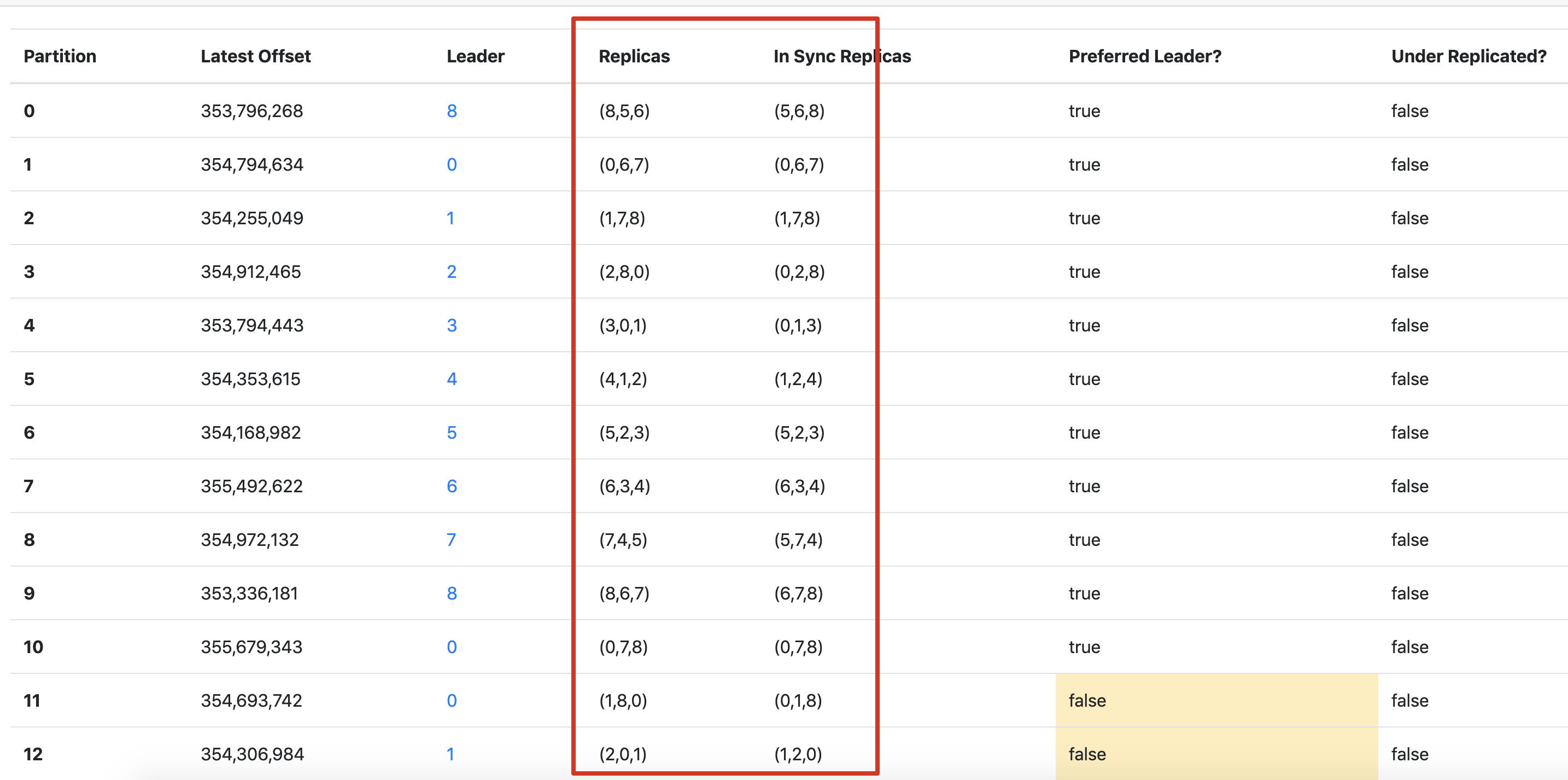
从以上图中可看出,各分区的新分配的副本都已经全部在 ISR 列表中了,并且将旧分配的副本删除,经过 Preferred Leader 选举之后,各分区新分配副本的 Preferred Leader 大多数成为了该分区 leader。
更多精彩文章请关注作者维护的公众号「后端进阶」,这是一个专注后端相关技术的公众号。
关注公众号并回复「后端」免费领取后端相关电子书籍。
欢迎分享,转载请保留出处。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号