数据结构 ------- 简介
数据结构研究非数值计算的程序设计中计算机的操作对象以及他们之间的关系和操作的学科。
在计算机发展初期,人们使用计算机的主要目的的是处理数值计算问题,所以程序设计者的主精力集中于程序设计的技巧上而无需重视数据结构,但随着计算机应用领域的扩大和软硬件的发展,非数值计算问显得越来越重要,使得数据元素之间的相互关系一般无法用数学方程式加以描述。因此解决这类问题的关键不再是数学分析和计算方法,而要设计出合适的数据结构才能有效的解决问题。(初期使用计算机解决一个具体问题是一般需要经过,从具体问题中抽象出一个适当的数学模型,然后设计或选择一个求解此的数学模型算法,最后编出程序进行调试测试,直至解决问题)
著名的瑞士计算机科学家沃思(N.Wirth)教授提出:数据结构+算法=程序(数据结构指的是数据的逻辑结构和存储结构,算法则是对数据运算的描述)
常见名词:数据 >数据元素 > 数据项
- 数据(Data):描述客观事物的数、字符以及能输入计算机中并被计算机处理的符号集合。(如计算机可处理的数字,子符串,图形、图像、声音等)
- 数据元素(data element): 数据的基本单位。(如表中一行,树中一个节点图中一个顶点),有时一个数据元素可以由若干个数组项(也称为字段、域、属性)组成,数据项是具有独立含义的最小标识单位。如(行中的某一单元格)
- 数据对象(data object): 具有相同性质的数据元素的集合,是数据的一个子集。(如字母数据对象是集合{'a','b','c','d','z'})
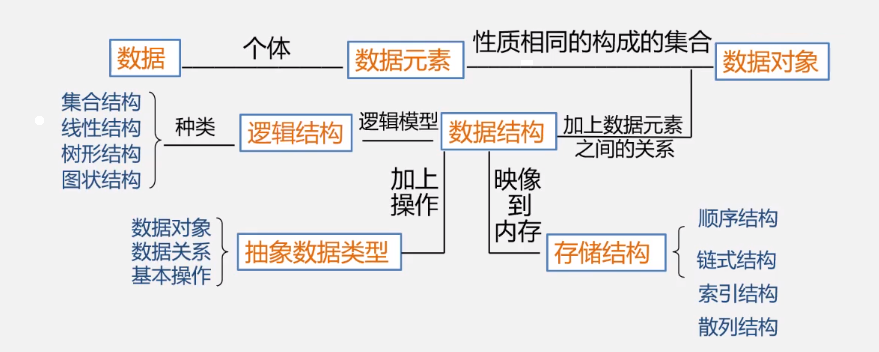
一、数据结构(data structure)是带有结构的数据元素的集合。
(结构指的是数据元素之间的相互关系,即数据的组织形式,结构中的数据元素称为节点),无论怎样定义数据结构,都应该将数据的逻辑结构、存储结构及运算三方面看成一个整体。
- 存储结构是逻辑关系的映像与元素本身的映像
- 逻辑结构是数据结构的抽象,存储结构是数据结构的实现

1、逻辑结构的种类: 线性结构与非线性结构
线性结构:有且仅有一个开始和一个终端节点,并且所有结点都最多只有一个直接前趋和一个直接后继
如:线性表,栈、队列、串
非线性结构: 一个结点可能有多个直接前趋和直接后继
如:树、图、网
其他划分如四种划分:集合结构(数据元素同属一个集合),线性结构(一对一),树形结构(一对多),图或网状结构(多对多关系)
2、存储结构
- 顺序存储结构:一组连续的存储单元依次存储数据元素,数据元素之间的逻辑关系由元素的存储位置决定
- 链式存储结构:一组任意的存储单元存储数据元素,数据元素之间的逻辑关系用指针来表示,存储时记住头指针并存储下一个元素的地址
- 索引存储结构:在存储结点信息的同时,还建立附加索引表,就像一本书的目录,目录就像索引表,通过目录中的标题找到具体的信息,方便多数据的查找。(**在索引表中,每一项称为索引项,索引项一般由关键词和地址组成,关键词时唯一标识一个结点的数据项**,其中若每个结点在索引表中都有一个索引项,则该索引表称为稠密索引。若一组结点在索引表中只对应一个索引项,则该索引表称为稀疏索引)
- 散列存储结构:根据结点的关键字直接计算出该结点的存储地址,
3、数据的运算,即对元素施加的操作(行为)
数据的运算时定义在数据的逻辑结构上的,每种逻辑结构都有一个运算的集合,最常用的运算有:检索、插入、删除、更新、排序等
- 检索:检索就是在数据结构里查找满足一定条件的节点。一般是给定一个某字段的值,找具有该字段值的节点。
- 插入:往数据结构中增加新的节点。
- 删除:把指定的结点从数据结构中去掉。
- 更新:改变指定节点的一个或多个字段的值。
- 排序:把节点按某种指定的顺序重新排列。例如递增或递减。
二、数据类型和抽象数据类型
1、数据类型: 数据类型= 值的集合 + 值集合上的一组操作
定义:一组性质相同的值的集合以及定义于这个值集合上的一组操作的总称。
作用:约束变量的取值范围 和 约束变量或常量的操作
2、抽象数据类型(abstract data type)
定义:指一个数学模型以及定义在此数学模型上的一组操作,
特点:由用户定义,从问题抽象出逻辑结构(数据模型),并定义在数据模型上的相关操作,不考虑计算机内的具体存储结构与运算的具体实现算法。
如定义一个某某类,这个类可以进行一些操作
形式定义(简洁严谨的定义):可用 D(数据**对象**),S(D上的**关系**集),P(D的基本**操作**集) 三元组表示
//抽象数据类型的定义格式 ADT 抽象数据类型名{ 数据对象:<数据对象的定义> 数据关系:<数据关系的定义> 基本操作:<基本操作的定义> }ADT 抽象数据类型名
其中:数据对象,数据关系的定义用伪代码描述,
基本操作的定义格式为:基本操作名(参数表)、初始条件(初始条件描述)、操作结果(操作结果描述)
参数表:
赋值参数只为操作提供输入值
引用参数以&打头,除可提供输入值外,还将返回操作结果
初始条件:描述操作执行之前数据结构和参数应满足的条件,若不满足,则操作失败,并返回相应的出错信息。为空则省略
操作结果:说明正常操作完成后,数据结构的变化状况和应返回的结果

三、算法
算法的描述:自然语言(英文,中文,,),流程图(传统流程图,NS流程图),伪代码(类语言),程序代码(c,java)
执行算法所耗费的时间为时间复杂性。
执行算法所耗费的存储空间,主要是辅助空间,为空间复杂性
算法应易于理解,易于编程,易于调试等,即可读性和可操作性
1、算法的五个特性:
- 有穷性:一个算法必须总是在执行有穷之后结束,且每一步都在有穷时间内完成
- 确定性:算法中的每一个指令必须有确切的含义,没有二义性,在任何条件下,只有唯一的一条执行路径,即对于相同的输入只能得到相同的输出
- 可行性:算法是可执行的,算法描述的操作可以通过已经实现的基本操作执行有限次来实现
- 输入:一个算法有零个或多个输入
- 输出:一个算法有一个或多个输出
2、设计算法:注意四个方面:正确性(对于精心选择的、典型的、苛刻的且带有刁难性的输入可得到满意的结果)、可读性(易于人理解)、健壮性(对出现错误时,有处理方法)、高效性(执行时间短)
3、算法效率:时间效率(执行算法耗费的时间)、控件效率(算法执行过程中耗费的空间)
算法时间效率的度量:算法编制的程序在计算机上执行所消耗的时间
两种方式:事前分析法和事后统计(一般不用)
算法运行时间 = 一个简单操作所消耗的时间 * 简单操作次数
算法运行时间 = ∑ 每条语句频度 * 该语句执行一次所需的时间
由于每条语句执行一次所需的时间,一般由机器决定,因此可假设每条语句所需的时间均为单位时间,此时算法的运行时间就可转变为对算法中语句执行次数,即频率之和
算法中基本语句重复执行的次数时问题规模 n 的某个函数 f(n) ,算法时间度量记作:T(n) = O(f(n))
T(n) = O(f(n)) 表示随着n的增大,算法执行的时间的增长率和f(n) 的增长率相同,称渐近时间复杂度
算法中基本语句重复执行的次数中问题规模n 的某个函数f(n) ,算法时间量度记作 T(n) = O(f(n))
(n越大算法执行时间越长:排序中n为记录数,矩阵中n为矩阵的阶数,多项式中n 为多项式的项数,集合中n为元素个数,树中n为树的结点个数,图中n为图的顶点数或边数)
4、分析算法时间复杂度的基本方法:
- 找出语句频度最大的那条语句作为基本语句
- 计算基本语句的频度得到问题规模n 的某个函数 f(n)
- 取其数量级用符号 "O" 表示
注意要求找出基本语句的
定理:极限求值,忽略所有低次幂项和最高次幂系数,体现出增长lu
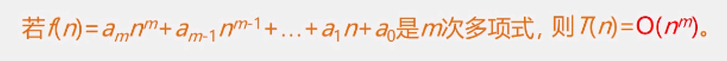
有的情况算法中的基本操作重复执行的次数还随问题的输入数据集不同而不同,因此要考虑最坏,最好和平均时间复杂度,一般总是考虑最坏时间复杂度
对于复杂算法,可以将它分成几个容易估算的部分,然后利用加法法则和乘法法则,计算算法时间复杂度
常见的时间复杂度按数量级递增排列,依次为:常数阶O(1)、对数阶O(log2n)、线性阶O(n)、线性对数阶O(nlog2n)、平方价O(n2)、立方阶O(n3)、k次方阶O(nk)、指数阶O(2n)、阶乘阶O(n!)

5、空间复杂度:算法所需存储空间的度量,记作 S(n)= O(f(n)) (其中n 为问题的规模或大小)
算法要占用的空间,输入/ 输出,指令,常数,变量,辅助空间(存放临时数据)等
如:将一个数组逆序存放的两种方式,一个是借助第三临时变量,另一个借助另一数组变量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号