java ------- I/O (三) 了解编码
一、使用字节流读写文本文件
1、使用InputStream 抽象类的一个子类FileInputStream 将文件中的数据输入到内部存储器(简称内存)中

注意:
1、read() 方法返回整数,如果读取的是字符串,需要强制类型转换
2、流对象使用后要关闭
输出的是字符对应的ASCII
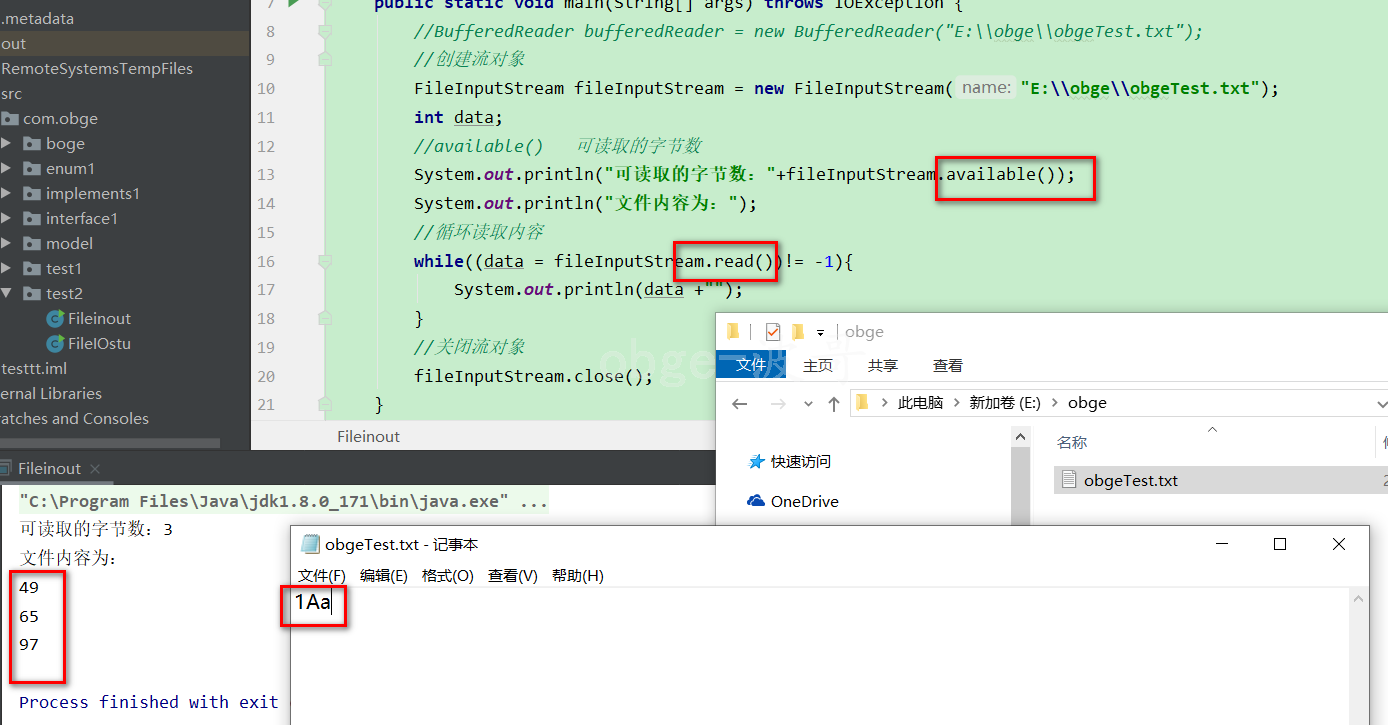
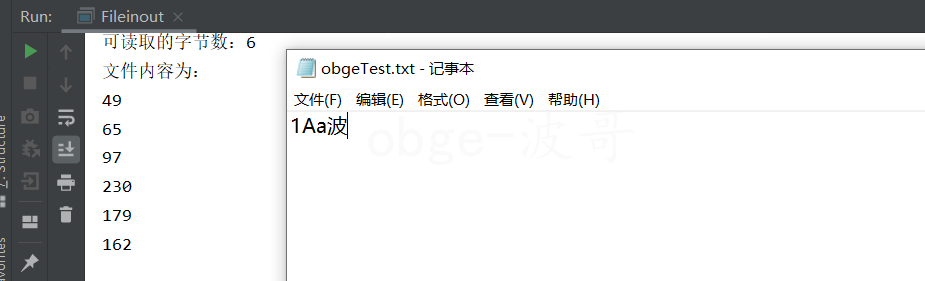
当你输入的是汉字的时候,发现一个汉字占有3 个字节,打印的数字大于 127 (ASCII 是从0 到 127 的),不是一直说汉字占用两个字节吗,那么这是咋个回事来?
因为,在UTF-8中,为了节约空间,也为了兼容ASCII编码系统,将Unicode中原本用2个字节表示的字符表示成1~4个字节,其中大多数汉字部分(比如“波”)在UTF-8中为3字节,但是在中国大陆地区,GBK编码依然很常用,在GBK中,除ASCII字符外,都是一个字符占两个字节。所以,一个汉字占多少字节还是具体取决于编码。
了解ASCII
ASCII(发音: /ˈæski/ ASS-kee[1],American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语,而其扩展版本延伸美国标准信息交换码则可以部分支持其他西欧语言,并等同于国际标准ISO/IEC 646。
共有128 个字符,其中33个字符且无法显示多数都已是陈废的控制字符。控制字符的用途主要是用来操控已经处理过的文字。在33个字符之外的是95个可显示的字符。
注意:用键盘敲下空白键所产生的空白字符也算1个可显示字符(显示为空白)。
95个可显示的字符

了解Unicode
Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。伴随着通用字符集的标准而发展,同时也以书本的形式对外发表。Unicode 至今仍在不断增修,每个新版本都加入更多新的字符。当前最新的版本为2020年3月公布的13.0.0,已经收录超过13万个字符(第十万个字符在2005年获采纳)。Unicode涵盖的数据除了视觉上的字形、编码方法、标准的字符编码外,还包含了字符特性,如大小写字母。
特点:
Unicode发展由非营利机构统一码联盟负责,该机构致力于让 Unicode 方案取代既有的字符编码方案。因为既有的方案往往空间非常有限,亦不适用于多语环境。
Unicode备受认可,并广泛地应用于电脑软件的国际化与本地化过程。有很多新科技,如可扩展置标语言(Extensible Markup Language,简称:XML)、Java编程语言以及现代的操作系统,都采用Unicode编码。
起源:
为了解决传统的字符编码方案的局限而产生的,例如ISO 8859-1所定义的字符虽然在不同的国家中广泛地使用,可是在不同国家间却经常出现不兼容的情况。很多传统的编码方式都有一个共同的问题,即容许电脑处理双语环境(通常使用拉丁字母以及其本地语言),但却无法同时支持多语言环境(指可同时处理多种语言混合的情况)。在文字处理方面,统一码为每一个字符而非字形定义唯一的代码(即一个整数)。换句话说,统一码以一种抽象的方式(即数字)来处理字符,并将视觉上的演绎工作(例如字体大小、外观形状、字体形态、文体等)留给其他软件来处理,例如网页浏览器或是文字处理器。
当前,几乎所有电脑系统都支持基本拉丁字母,并各自支持不同的其他编码方式。Unicode为了和它们相互兼容,其首 256 个字符保留给 ISO 8859-1 所定义的字符,使既有的西欧语系文字的转换不需特别考量;并且把大量相同的字符重复编到不同的字符码中去,使得旧有纷杂的编码方式得以和Unicode编码间互相直接转换,而不会丢失任何信息。举例来说,全角格式区段包含了主要的拉丁字母的全角格式,在中文、日文、以及韩文字形当中,这些字符以全角的方式来呈现,而不以常见的半角形式显示,这对竖排文字和等宽排列文字有重要作用。
在表示一个 Unicode 的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符。在基本多文种平面(英语:Basic Multilingual Plane,简写 BMP。又称为“零号平面”、plane 0)里的所有字符,要用四个数字(即两个byte,共16 bits,例如 U+4AE0,共支持六万多个字符);在零号平面以外的字符则需要使用五个或六个数字。旧版的 Unicode 标准使用相近的标记方法,但却有些微小差异:在 Unicode 3.0 里使用“U-”然后紧接着八个数字,而“U+”则必须随后紧接着四个数字。
Unicode标准
Unicode 自版本 2.0 开始保持了向后兼容,即新的版本仅仅增加字符,原有字符不会被删除或更名。统一码联盟在 1991 年首次发布了 The Unicode Standard。Unicode 的开发结合了国际标准化组织所制定的 ISO/IEC 10646,即通用字符集。Unicode 与 ISO/IEC 10646 在编码的运作原理相同,但 The Unicode Standard 包含了更详尽的实现信息、涵盖了更细节的主题,诸如比特编码(bitwise encoding)、校对以及呈现等。The Unicode Standard 也枚举了诸多的字符特性,包含了那些必须支持两种阅读方向的文字(由左至右或由右至左的文字阅读方向,例如阿拉伯文是由右至左)。Unicode 与 ISO/IEC 10646 这两个标准在术语上的使用有些微的不同。在 2005 年,Unicode 的第十万个字符被引入成为标准之一,该字符被用于马拉雅拉姆语。
了解编码方式
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。它可以用一至四个字节对Unicode字符集中的所有有效编码点进行编码,属于Unicode标准的一部分,最初由肯·汤普逊和罗布·派克提出。由于较小值的编码点一般使用频率较高,直接使用Unicode编码效率低下,大量浪费内存空间。UTF-8就是为了解决向后兼容ASCII码而设计,Unicode中前128个字符(与ASCII码一一对应),使用与ASCII码相同的二进制值的单个字节进行编码,这使得原来处理ASCII字符的软件无须或只须做少部分修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或发送文字优先采用的编码方式。
结构
UTF-8使用一至六个字节为每个字符编码(尽管如此,2003年11月UTF-8被RFC 3629重新规范,只能使用原来Unicode定义的区域,U+0000到U+10FFFF,也就是说最多四个字节):
1、128个US-ASCII字符只需一个字节编码(Unicode范围由U+0000至U+007F)。
2、带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要两个字节编码(Unicode范围由U+0080至U+07FF)。
3、其他基本多文种平面(BMP)中的字符(这包含了大部分常用字,如大部分的汉字)使用三个字节编码(Unicode范围由U+0800至U+FFFF)。
4、其他极少使用的Unicode 辅助平面的字符使用四至六字节编码(Unicode范围由U+10000至U+1FFFFF使用四字节,Unicode范围由U+200000至U+3FFFFFF使用五字节,Unicode范围由U+4000000至U+7FFFFFFF使用六字节)。
对上述提及的第四种字符而言,UTF-8使用四至六个字节来编码似乎太耗费资源了。但UTF-8对所有常用的字符都可以用三个字节表示,而且它的另一种选择,UTF-16编码,对前述的第四种字符同样需要四个字节来编码,所以要决定UTF-8或UTF-16哪种编码比较有效率,还要视所使用的字符的分布范围而定。不过,如果使用一些传统的压缩系统,比如DEFLATE,则这些不同编码系统间的的差异就变得微不足道了。若顾及传统压缩算法在压缩较短文字上的效果不大,可以考虑使用Unicode标准压缩格式(SCSU)。

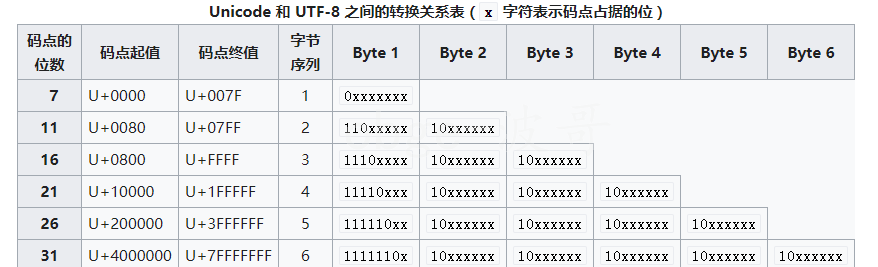
UTF-8编码字节含义
对于UTF-8编码中的任意字节B,如果B的第一位为0,则B独立的表示一个字符(ASCII码);
如果B的第一位为1,第二位为0,则B为一个多字节字符中的一个字节(非ASCII字符);
如果B的前两位为1,第三位为0,则B为两个字节表示的字符中的第一个字节;
如果B的前三位为1,第四位为0,则B为三个字节表示的字符中的第一个字节;
如果B的前四位为1,第五位为0,则B为四个字节表示的字符中的第一个字节;
因此,对UTF-8编码中的任意字节,根据第一位,可判断是否为ASCII字符;根据前二位,可判断该字节是否为一个字符编码的第一个字节;根据前四位(如果前两位均为1),可确定该字节为字符编码的第一个字节,并且可判断对应的字符由几个字节表示;根据前五位(如果前四位为1),可判断编码是否有错误或数据传输过程中是否有错误。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号