数据架构:从主备,主主到集群的高可用方案
本文选自公众号:不止思考
精彩预告:第八届数据技术嘉年华大会将于2018年11月16日~17日在北京市朝阳区东三环中路61号富力万丽酒店盛大开启。本次大会邀请互联网领先企业的数据库专家,国产数据库的领军人物,云技术等领域的知名人士,围绕数据、智能、链接组织前沿议题,倡导以智能智慧算法应用,发掘数据价值,以技术将企业链接到未来的战略制高点!
社区专属福利(99.9%的人不知道):一分钱全场通票等你抢
在互联网项目中,当业务规模越来越大,数据越来越多,随之而来的就是数据库压力会越来越大。慢慢就会发现,数据库层可能已经成为了整个系统的关键点和性能瓶颈了,因此实现数据层的高可用就成为了我们项目中经常要解决的问题。
本文我们就来聊一聊如何实现数据存储层的高可用方案。在保障数据层的高性能与高稳定方面,最容易想到的方式就是对数据进行分片、多份、冗余等,很多架构的本质其实也是基于这几点来实现的。
这里先不看细节,即先不管底层数据源是什么数据库,我们先只聊架构方案,因为无论底层是关系型数据库,还是NoSQL数据库,无论是 Mysql 还是 Redis、MongoDB,我们在架构设计上都是相通的。
大体上,单中心双机的常见方案有以下这些:
- 一主一备的架构(主备式)
- 一主一从的架构(主从式)
- 互为主从的架构(主主式)
以上方案从上至下,依次是从简单到复杂,从基础到丰富。下面我们来具体看看:
一、一主一备的架构(主备式)
主备式架构是双机部署中最简单的一种架构了,几乎市面上所有的数据库系统都会自带这个主备功能。
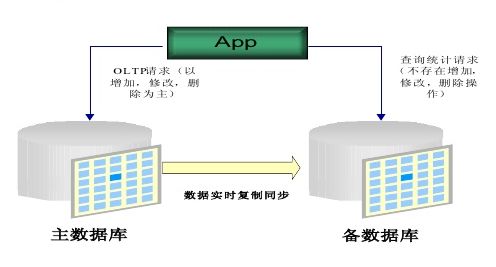
其思路也特别的简单:将数据库部署到两台机器,其中一台机器(代号A)作为日常提供数据读写服务的机器,称为「主机」。另外一台机器(代号B)并不提供线上服务,但会实时的将「主机」的数据同步过来,称为「备机」。一旦「主机」出了故障,通过人工的方式,手动的将「主机」踢下线,将「备机」改为「主机」来继续提供服务。
这个架构的优缺点都很明显,优点就是几乎不需要做什么开发改造,各类数据库就支持这种模式,部署维护起来也简单,并没有引入额外的系统复杂度和瓶颈。
但是缺点呢,就是当「主机」出现故障的时候,需要人工去干预啊,运维同学很辛苦的,而且处理还不一定及时。再还有一个缺点就是,主备架构会造成严重浪费资源,毕竟需要一台与「主机」同等配置的「备机」长期备着,但又不作为线上服务来使用,你说浪费不浪费。
为了解决这个资源浪费问题,我们就得想一个把「备机」也用起来的方案:主从式架构。
二、一主一从的架构(主从式)
主从式架构大体上与上述的主备式架构差不多。区别就是主备式的「备机」平时是不干活的的,主要起到备份的作用。而主从式的「备机」改为了「从机」,平时也要提供服务,跟「主机」一样随时随刻的在干活的。
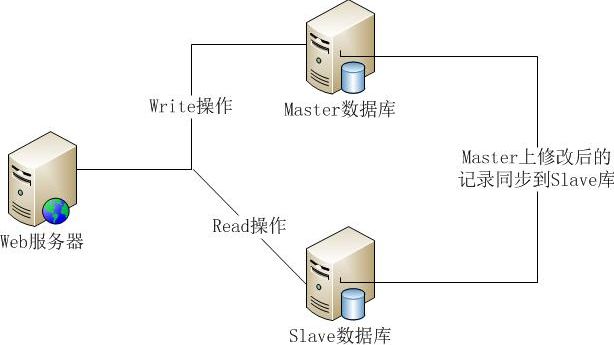
主从式架构中的「从机」虽然也在随时随刻提供服务,但是它只提供「读」服务,并不提供「写」服务。「主机」会实时的将线上数据同步到「从机」,以保证「从机」能够正常的提供读操作。
这种架构相比较主备式,对资源是一种节约,毕竟「从机」也在提供服务,没有白白的浪费。并且在「主机」出现故障时,在人工介入之前,好歹「从机」也是能够提供数据的「读」操作的,毕竟大多数业务都是「读」多「写」少,因此对稳定性又提高了一个层次。
缺点就是架构稍微复杂了一点,毕竟「主机」和「从机」都有「读」服务,那么前端业务系统就需要用一定策略去判断该路由到哪一台去读取数据。还有就是,延迟问题,「主机」的数据同步到「从机」难免会有一定程度的延迟,这个延迟可能会对数据实时性要求较高的业务有一定影响。
通过上面内容可以看到,虽然这个架构一定程度解决了资源浪费,但是并没有解决人工干预的问题,当出现了故障后还是需要人工去处理。
如果想让架构更智能一点,那么我们就需要引入「主从双机自动切换」的功能。
主从双机自动切换:是指当主机出现故障后,从机能够自动检测发现。同时从机将自己迅速切换为主机,将原来的主机立即下线服务,或转换为从机状态。
要实现「主从双机自动切换」,有几个关键点需要考虑:
- 主机与从机之间的状态如何判断? 必须有一个机制能监测两台机器的运行状态,以此来决定是否应该切换。 我们比较常用的状态传递方式有两种:
- 「双机互连模式」
- 「第三方中介模式」
「双机互连模式」:是指在主机和从机之间建立一条用于状态通讯的通道。通过这个通道,主机和从机之间可以共享服务状态,一旦发现对方宕机或者停止服务了,就可以立即将自己切换为主服务。不过这种方式需要关注通道的健壮性,一旦通道自身不稳定了,可能会导致假消息出现,比如主机并没有宕机,但是通道坏了,导致从机以为出现了异常,就将自己切换为了主机,那就出现了2个主机了,因此通道本身也是一个可能的故障点。
「第三方中介模式」:是指在主机和从机之外,再建立一个中介机器,这个中介机器专门用来维护各节点(主机/从机)状态的,主机/从机实时的将自身状态上报给中介机器,中介机器来决定是否应该切换、何时切换。MongoDB的Replica Set就是采用的这种模式。
- 除了状态判断,还需要考虑切换的策略是什么? 也就是说发生异常几次/多久后开始切换,是否有一个缓冲机制等。另外切换完成后,当原主机又恢复正常之后是否需要自动再切换回来等策略。
- 另外就是需要注意在切换过程中双机数据如果发生冲突时,以哪个为准?处理机制是什么。
这些细节都是在设计主从自动切换架构时候,要提前规划的。
三、互为主从的架构(主主式)
互为主从的架构是指两台机器自己都是主机,并且也都是作为对方的从机。两台机器都提供完整的读写服务,因此无需切换,客户机在调用的时候随机挑选一台即可,当其中一台宕机了,另外一台还可以继续服务。
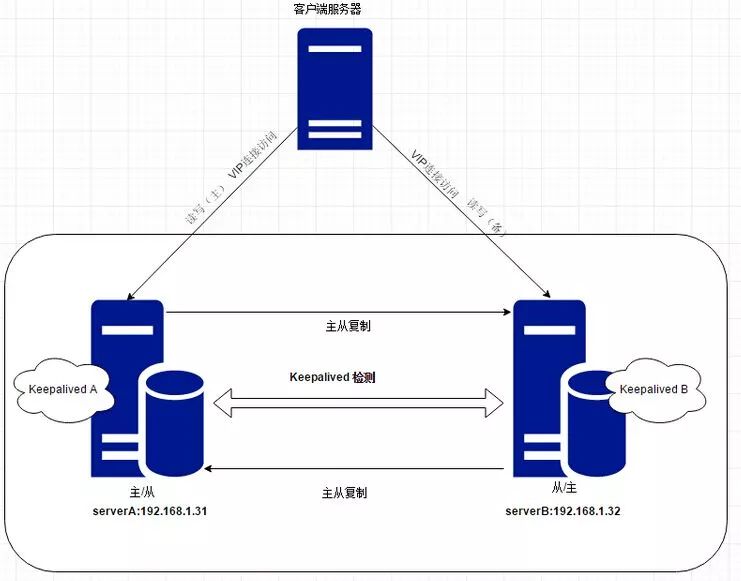
采用互为主从架构有个复杂点就是,因为两台主机都接受写数据,那就需要将写的最新数据实时的同步给对方,需要将数据进行两台主机的双向复制。而双向复制不可避免的会在一定程度上带来数据延迟、极端情况下甚至有数据丢失等问题。在实际业务中,有些业务数据对一致性要求是非常高的,并不能接受数据的延迟、丢失,因此这类业务也不适合互为主从的模式,比如金融业务。但是我们互联网业务中大多数场景还是没有这么高要求的,所以这种模式对于一般场景还是用的蛮多。
以上,就是对数据库从主备架构、到主从架构、再到主主架构的高可用方案基本讲解了,接下来会继续分享数据库在多机集群模式下的技术架构,欢迎大家关注交流。
在以上的分享中,我们知道数据库服务可能已经成为了很多系统的性能关键点,甚至是瓶颈了。也给大家介绍了数据库服务器从主备架构、到主从架构、再到主主架构的基础方案。但如果单台机器已经不能满足完整业务数据存储的时候,我们就需要考虑采用多机甚至多中心的部署方案了。
接下来我们就再来聊一聊,在多机环境下,数据库集群的架构方案。
同样,这里先不看细节,不管底层数据源是什么数据库,我们先谈架构方案。因为无论底层是 Mysql 还是 Redis、MongoDB,我们在架构设计上都是相通的。
针对多机的架构,常见有如下做法:
- 单中心数据集群
- 多中心数据分区
下面我们来具体看看:
一、单中心的数据集群架构(单中心多机)
单数据中心多机器的集群又可以分为:
- 数据集中模式
- 数据分散模式
这两种的主要区别在于集群中的完整业务数据是全部集中在一台机器上,但是分散在多台机器上。
- 数据集中模式
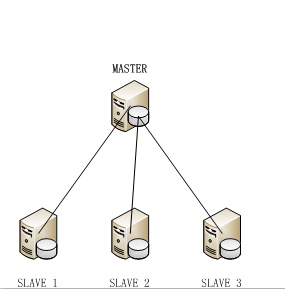
这种模式与「一主一从式」(主从式)比较类似,完整的业务数据还是存储在一台主机的上,主机承担读服务和写服务,从机只承担读服务。但是从机有多台机器,从机实时的从主机同步数据。所以这种模式,也可以理解为「一主多从」式。
因为有多个从机,那么也给这种架构带来了一些额外需要处理问题,比如:
1.1,主机需要实时的将数据同步到多台从机上,涉及到主机的处理压力问题。
1.2,需要保障多台从机之间的数据一致性的问题,如果出现数据不一致,如何处理。
1.3,多台从机是如何检测主机状态的,因为从机在关键时刻是要替换主机的,那么如果多台从机监测到的主机状态不一致,那又可能会带来其它问题。
1.4,从机切换为主机的时候,选择哪一台从机来切换呢,这涉及到多台从机之间如何进行选举的问题。
这些问题,在我们进行架构设计的时候,必须提前考虑。不过市面上也有一些工具可以辅助实现,例如 ZooKeeper等。
另外,由于数据集中模式的所有写操作都只到一台主机上,而读操作可以到N台从机上。因此这种模式比较适用于业务数据量不大、读操作远远大于写操作、集群规模较小的业务场景。
- 数据分散模式
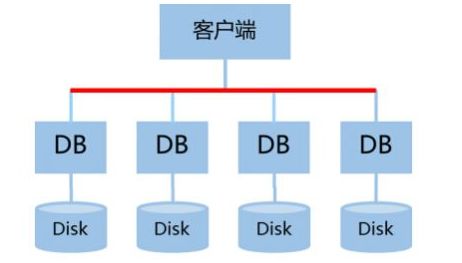
数据分散模式是指,完整的业务数据并非是全部存储在一台主机上的,而是由多台主机共同分担,分散存储。因此这种模式适用于大数据量、集群规模较大的场景。
使用这种模式,也有几点需要特别注意的:
1.1,尽量将数据均衡的分散的各个机上,这样才能保证资源的均衡使用和性能的最佳。
1.2,多台机器上的数据虽然不同,但是也需要互相进行数据的备份。
1.3,要能动态的增加和删除节点,这样可以便于随时扩展,通常采用一致性HASH的方法。
聊完了单数据中心的集群架构,我们再来看看多数据中心的数据分区架构。
二、多中心的数据分区架构(多中心多机)
出于容灾的考虑,通常会在多个不同地区部署多套的数据集群。毕竟在国内运营商网络故障、光纤被山东蓝翔技工铲断等事件还是不少的。轻则一个机房出问题,重则一个城市一个省份都可能故障。
如果我们数据存储服务只部署在一个机房,那如果这个机房出现了故障,很有可能导致不能服务甚至是无法恢复业务了。因此我们就需要考虑多中心的数据分区架构,将数据按照一定的规则进行分区,部署在不同机房/城市里,且每一个分区都存储一部分数据,通过这种方式来保障数据和服务的可用性。
在多中心的数据分区模式下,我们需要提前规划 “分区规则” 。毕竟将数据在地理位置上分区,在网络通讯方面是有时延的,所以必须要考虑好我们是要以区域、还是以城市、还是省份来分节点部署。
除了 “分区规则” ,我们还需要考虑 “备份规则” 。
因为分区之后,各区都只存储一部分数据,并不是完整数据。如果其中一个区出故障了,虽然不会影响全局,但是也会带来一定损失。因此我们需要考虑将每个区里的数据备份起来,备份有几种方式:
- 集中备份式
- 独立备份式
- 相互备份式
下面将这三种备份方式解释一下:
- 集中备份式
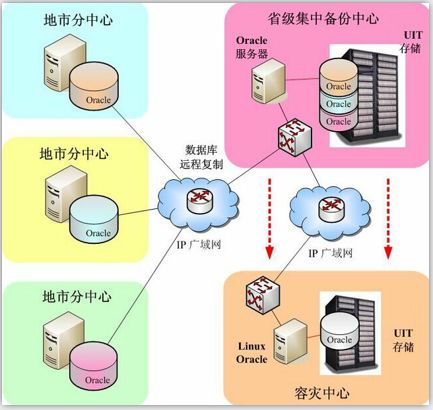
集中备份式是指建立一个独立的数据备份中心,将各分区(节点)的数据都定期同步到这个备份中心,以保障数据的安全性。这种备份方式可以随意的扩展分区(节点),不受分区的个数限制,并且结构很简单。但是
这种备份方式的缺点就是,投入成本有点高,因为需要额外建立这么一个备份数据中心,平时也是闲置的,有点浪费资源。另外,备份中心自身也可能会有单点的故障,且备份中心中需存储多个分区的数据,还可能会互相受到影响。
- 独立备份式
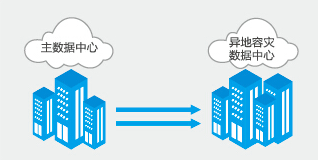
独立备份式就是给每一个数据分区(节点)都建立一个额外的备份节点,这个备份节点部署在不同的地域/城市,这样才能起到容灾的作用。
这种备份方式相比较于 集中备份式 ,建设成本就更大一些了,毕竟每一个分区都需要额外建立一个备份节点。但是结构更清晰简单了,而且各个分区的数据之间还可以做到互不影响,完全是独立的。后续扩展分区(节点)的时候,对前面的备份节点也没有影响,扩展性好。
- 相互备份式
相互备份式其实是结合了上面两种特性在一起的模式。上面的方式不是成本大么,那么这种方式就不额外建立备份中心了,让各个分区(节点)互相备份数据。比如 分区A 将自身数据同步一份给 分区B备份着,分区B 将自己的数据同步一份给 分区A 备份着,如果是三个以上分区,还可以做到循环备份。
这种备份方式,设计稍微复杂一些,扩展性也弱一些,但是可以节约资源。
无论采用哪种方式,都需要结合实际的业务场景来决定。
以上,就是对数据库在多机集群模式下的技术架构的分享,欢迎大家一起交流。
转载自:不止思考。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号