Go基础-下
一、面向对象:
抽象:把一类事物的共有属性(字段)和行为(方法)抽取出来,形成一个物理模型(模板),这种研究问题的方法称为抽象
1、面向对象的三大特性:
继承、封装和多态
封装:
就是把抽象出的字段和对字段的操作封装在一起,程序被保护在内部,程序的其他包只能通过被授权的操作(方法),才能对字段进行操作
封装的好处:
- 隐藏实现细节
- 可以对数据就进行验证,保证安全合理
如何体现封装:
- 对结构体中的属性进行封装
- 通过方法,包实现封装
封装的实现步骤:
-
将结构体、字段(属性)的首字母小写(不能导出了,其它包不能使用,类似private)
-
给结构体所在包提供一个工厂模式的函数,首字母大写,类似一个构造函数
-
提供一个首字母大写的Set方法(类似其他语言的public),用于对属性判断并赋值
func (var 结构体类名) SetXxx(参数列表)(返回值列表){ //加入数据验证的业务逻辑 var.字段 = 参数 } -
提供一个首字母大写的Get方法(类似其他语言的public),用于获取属性的值
func (var 结构体类型名) GetXxx(){ return var.age }
案例:
新建encapsulate/main/main.go和encapsulate/model/person.go两个文件
main.go里面:
package main
import (
"Go-Learning/encapsulate/model"
"fmt"
)
func main() {
p := model.NewPerson("smith")
p.SetAge(18)
p.SetSal(5000)
fmt.Println(p)
fmt.Println(p.Name, "age=", p.GetAge(), "sal=", p.GetSal())
}
person.go里面:
package model
import "fmt"
type person struct {
Name string
age int // 其他包不能直接访问
sal float64
}
//写一个工厂模式的函数,相当于构造函数
func NewPerson(name string) *person {
return &person{
Name: name,
}
}
//为了访问age和sal我们编写一对SetXxx的方法和GetXxx的方法
func (p *person) SetAge(age int) {
if age > 0 && age < 150 {
p.age = age
} else {
fmt.Println("年龄范围不正确...")
}
}
func (p *person) GetAge() int {
return p.age
}
func (p *person) SetSal(sal float64) {
if sal >= 3000 && sal <= 30000 {
p.sal = sal
} else {
fmt.Println("薪水范围不正确...")
}
}
func (p *person) GetSal() float64 {
return p.sal
}
继承:
继承可以解决代码复用,当多个结构体存在相同的属性(字段)和方法时,可以抽象出结构体,在结构体中定义这些相同的属性和方法
在Go中,如果一个struct嵌套了另一个匿名结构体,哪么这个结构体可以直接访问匿名结构体的字段和方法,从而实现了继承特性
type Goods struct{
Name string
Price int
}
type Book struct {
Goods // 这里就是嵌套匿名结构体Goods
Writer string
}
便利:
- 代码的复用性提高了
- 代码的扩展性和维护性提高了
继承的深入讨论:
-
结构体可以使用嵌套匿名结构体的所有字段和方法,即首字母大写或者小写的字段、方法都可以使用
package main import "fmt" type A struct { Name string age int } func (a *A) SayOk() { fmt.Println("A SayOk", a.Name) } func (a *A) hello() { fmt.Println("A hello", a.Name) } type B struct { A } func main() { var b B b.A.Name = "tom" b.A.age = 19 b.A.SayOk() b.A.hello() } -
匿名结构体字段访问可以简化
b.A.name = "tom" => b.name = "tom"
-
当结构体和匿名结构体有相同的字段或方法时,编译器采用就近访问原则,如希望访问匿名结构体的字段和方法,可以通过匿名结构体来区分
-
结构体嵌入两个(或多个)匿名结构体,如果两个匿名结构体有相同的字段和方法(同时结构体半身没有同名的字段和方法),在访问时,就必须明确指明匿名结构体名字否则编译报错
type A struct { Name string Age int } type B struct { Name string score int } type C struct { A B // Name string } -
如果一个struct嵌套了一个有名结构体,这种模式就是组合,如果是组合关系,哪么在访问组合的结构体的字段或方法时,必须带上结构体的名字
type A struct { Name string Age int } type C struct { a A } -
嵌套匿名结构体后,也可以在创建结构体变量(实例)时,直接指定各个匿名结构体字段的值
type Goods struct { Name string Price float64 } type Brand struct { Name string Address string } type TV struct { Goods Brand } type TV2 struct { *Goods *Brand } func main() { // 嵌套匿名结构体后,也可以在创建结构体变量(实例)时,直接指定各个匿名结构体字段的值 tv := TV{Goods{"电视机", 5000.99}, Brand{"海尔", "山东"}} tv2 := TV{ Goods{ Name: "电视机", Price: 5000.99, }, Brand{ Name: "海尔", Address: "山东", }, } fmt.Println("tv", tv) fmt.Println("tv2", tv2) tv3 := TV2{&Goods{"电视机", 7000.5}, &Brand{"创维", "河南"}} tv4 := TV2{ &Goods{ Name: "电视机", Price: 7000.5, }, &Brand{"创维", "河南"}} fmt.Println("tv3", *tv3.Goods, *tv3.Brand) fmt.Println("tv4", *tv4.Goods, *tv4.Brand) }type Monster struct { Name string Age int } type E struct { Monster int } func main() { var e E e.Name = "狐狸" e.Age = 300 e.int = 20 e.n = 40 fmt.Println("e=",e) }说明:
- 如果一个结构体有int类型的匿名字段,就不能第二个
- 如果需要有多个int字段,则必须给int字段
多重继承说明:
如一个struct嵌套了多个匿名结构体,那么该结构体可以直接访问嵌套的匿名结构体的字段和方法,从而实现了多重继承
接口:
按照顺序应该讲解多态,但是讲解多态前,需要讲解接口,因为Go中多态特性主要是通过接口体现的
package main
import "fmt"
// 声明/定义一个接口
type Usb interface {
// 声明了两个没有实现的方法
Start()
Stop()
}
type Phone struct {
}
// 让Phone实现Usb接口的方法
func (p Phone) Start() {
fmt.Println("手机开始工作")
}
func (p Phone) Stop() {
fmt.Println("手机停止工作")
}
type Camera struct {
}
// 让Camera实现 Usb接口的方法
func (c Camera) Start() {
fmt.Println("相机开始工作")
}
func (c Camera) Stop() {
fmt.Println("相机停止工作")
}
// 计算机
type Computer struct {
}
// 编写一个方法Working方法,接收一个Usb接口类型变量
// 只要实现了Usb接口(所谓实现Usb接口,就是指实现了Usb接口声明的所有方法)
func (c Computer) Working(usb Usb) {
// 通过usb接口变量来调用Start和Stop方法
usb.Start()
usb.Stop()
}
func main() {
//测试
//先创建结构体变量
computer := Computer{}
phone := Phone{}
camera := Camera{}
//关键点
computer.Working(phone)
computer.Working(camera)
}
interface类型可以定义一组方法,但是这些不需要实现,并且interface不能包含任何变量,到某个自定义类型要使用的时候,在根据具体情况把这些方法写出来(实现)
基本语法:
type 接口名 interface {
method1(参数列表) 返回值列表
method2(参数列表) 返回值列表
...
}
实现接口所有方法
func (t 自定义类型) method1(参数列表) 返回值列表 {
// 方法实现
}
func (t 自定义类型) method2(参数列表) 返回值列表 {
// 方法实现
}
// ...
小结说明:
- 接口里的所有方法都没有方法体,即接口的方法都是没有实现的方法,接口体现了程序设计的多态和高内聚低耦合的思想
- Go中的接口,不需要显示的实现,只要一个变量,含义接口类型中的所有方法,那么这个变量就实现这个接口,因此Go中没有implement这样的关键字
注意细节:
-
接口本身不能创建实例,但是可以指向一个实现了该接口的自定义类型的变量(实例)
-
接口中所有的方法都没有方法体,即都是没有实现的方法
-
在Go中,一个自定义类型需要将某个接口的所有方法都实现,我们说这个自定义类型实现了该接口
-
一个自定义类型只有实现了某个接口,才能将该自定义类型的实例赋给接口类型
-
只要是自定义数据类型,就可以实现接口,不仅仅是结构体类型
-
一个自定义类型可以实现多个接口
type AInterface interface { Say() } type BInterface interface { Hello() } type Monster struct { } func (m Monster) Hello() { fmt.Println("Monster Hello()") } func (m Monster) Say() { fmt.Println("Monster Say()") } // Monster实现了AInterface和BInterface var monster Monster var a2 AInterface = monster var b2 BInterface = monster a2.Say() b2.Hello() -
Go接口中不能有任何变量
-
一个接口(比如A接口)可以继承多个别的接口(比如B,C接口),这是如果要实现A接口,也必须将B,C接口的方法也全部实现
-
interface类型默认是一个指针(引用类型),如果没有对interface初始化就使用,那么会输出nil
-
空节课interface{}没有任何方法,所以所有类型都实现了空接口,即我们可以把任何变量赋给空接口
type Usb interface { Say() } type Stu struct { } func (this *Stu) Say() { fmt.Println("Say()") } func main() { var stu Usb = &Stu{} //var stu Stu = Stu{} // 错误!会报Stu类型没有实现Usb接口 // 如果希望通过编译 var u Usb = &stu var u Usb = stu u.Say() fmt.Println("here", u) }package main import ( "fmt" "math/rand" "sort" ) // 1.声明Hero结构体 type Hero struct { Name string Age int } // 2.声明一个Hero结构体切片类型 type HeroSlice []Hero // 3.实现Interface接口 func (hs HeroSlice) Len() int { return len(hs) } //Less方法就是决定你使用什么标准进行排序 //1.按照Hero的年龄从小到大排序 func (hs HeroSlice) Less(i, j int) bool { return hs[i].Age > hs[j].Age } func (hs HeroSlice) Swap(i, j int) { //temp := hs[i] //hs[i] = hs[j] //hs[j] = temp hs[i], hs[j] = hs[j], hs[i] } func main() { // 先定义一个数组/切片 var intSlice = []int{0, -1, 10, 7, 90} // 要求对intSlice切片进行排序 // 1.冒泡排序 // 2.也可以使用系统提供的方法 sort.Ints(intSlice) fmt.Println(intSlice) // 测试看看我们是否可以对结构体切片进行排序 var heroes HeroSlice for i := 0; i < 10; i++ { hero := Hero{ Name: fmt.Sprintf("英雄~%d", rand.Intn(100)), Age: rand.Intn(100), } //将hero append到heroes切片 heroes = append(heroes, hero) } // 看看排序前的顺序 for _, v := range heroes { fmt.Println(v) } //调用sort.Sort sort.Sort(heroes) // 看看排序后的顺序 for _, v := range heroes { fmt.Println(v) } }接口就是对继承的补充,可以在不破坏原来继承关系的情况下进行扩展
小结:
- 当A结构体继承了B结构体,那么A结构就自动的继承了B结构体的字段和方法,并且可以直接使用
- 当A结构体需要扩展功能,同事不希望去破坏继承关系,可以去实现某个接口即可,因此我们可以认为:实现接口是对继承机制的补充
接口和继承的区别:
-
接口和继承解决的问题不同
- 继承的价值在于:解决代码的复用性和可维护性
- 接口的价值在于:设计,设计好各种规范(方法),让其它自定义类型去实现这些方法
-
接口比继承更灵活
-
接口在一定程度上实现代码解耦
-
接口可以看做是对继承的一种补充
-
接口和继承解决的问题不同
继承的价值在于:解决代码的复用性和可维护性
接口的价值主要在于:设计,设计好各种规范(方法),让其它自定义类型去实现这些方法
-
接口比继承更加灵活
接口比继承更加灵活,继承是满足is-a的关系,而接口只需要满足like-a的关系
-
接口在一定程度上实现代码解耦
2、多态:
在Go中,多态特征是通过接口实现的,可以按照统一的接口来调用不同的实现,这是接口变量就呈现不同的形态
接口体现多态特征:
-
多态参数
在前面的usb接口案例,Usb usb即可接收手机变量,又可以接收相机变量就体现了Usb接口的多态
-
多态数组
给Usb数组中,存放Phone结构体和Camera结构体变量,Phone还有一个特有的方法call(),请遍历Usb数组,如果Phone变量,除了调用Usb接口声明的方法外,还需要调用Phone特有方法call 需要用到类型断言
var usbArr = [3]Usb usbArr[0] = Phone{} usbArr[1] = Phone{} usbArr[2] = Camera{} fmt.Println(usbArr)
3、类型断言
类型断言,由于接口是一般类型,不知道具体类型,如果要转成具体类型,就需要使用类型断言,具体的如下:
在进行类型断言时,如果类型不匹配,就会报panic,因此进行类型断言时,要确保原来的空接口指向的就是断言的类型
如何在进行断言时,带上检测机制,如果成功就ok,否则也不要报panic
y, ok := x.(float64)
if ok {}
//可也以写成
if y,ok := x.(float32); ok{}
案例:
// 编写一个函数,判断输入的参数是什么类型
func TypeJudge(items ...interface{}) {
for index, x := range items {
switch x.(type) {
case bool:
fmt.Printf("第%v个参数是bool类型,值是%v\n", index, x)
case float32:
fmt.Printf("第%v个参数是float32类型,值是%v\n", index, x)
case float64:
fmt.Printf("第%v个参数是float64类型,值是%v\n", index, x)
case int, int32, int64:
fmt.Printf("第%v个参数是整数类型,值是%v\n", index, x)
case string:
fmt.Printf("第%v个参数是string类型,值是%v\n", index, x)
default:
fmt.Printf("第%v个参数是类型不确定,值是%v\n", index, x)
}
}
}
func main(){
var n1 float32 = 1.1
var n2 float64 = 2.3
var n3 int32 = 30
var name string = "tom"
address := "北京"
n4 := 300
TypeJudge(n1,n2,n3,name,address,n4)
}
二、文件操作
文件在程序中是以流的形式来操作的
流:数据在数据源(文件)和程序(内存)之间经历的路径
输入流:数据从数据源(文件)到程序(内存)的路径
输出流:数据从程序(内存)到数据源(文件)的路径
os.File封装所有文件相关操作,File是一个结构体
常用的文件操作函数和方法:
-
打开一个文件进行读操作:
os.Open(name string)(*File, error)
-
关闭一个文件
File.Close()
-
其他的函数和方法在案例详解
案例:
func main() {
// 打开文件
// 概念说明:file的叫法
// 1.file叫file对象
// 2.file叫file指针
// 3.file叫file文件句柄
file, err := os.Open("d:/test/txt")
if err != nil {
fmt.Println("open file err=",err)
}
// 输出一下文件,看看文件是什么,看出file就是一个指针*File
fmt.Println("file=%v",file)
// 关闭文件
err = file.Close()
if err != nil {
fmt.Println("close file err=",err)
}
}
带缓冲的reader读文件:
有缓冲区时读文件不是一次性全部读,而是读一部分处理一部分
reader := bufio.NewReader(file)
// 循环的读取文件的内容
for {
str, err := reader.ReadString('\n') // 读到一个换行就结束
if err == io.EOF { // io.EOF表示文件的末尾
break
}
// 输出内容
fmt.Printf(str)
}
fmt.Println("文件读取结束")
一次性读取文件:
读取文件的内容并显示在终端(使用ioutil一次将整个文件读入到内存中),这种方式适用于文件不大的情况,相关方法和函数(ioutil.ReadFile)
适用于文件比较小的时候
// 使用ioutil.ReadFile一次性将文件读取到位
file := "d:/test.txt"
content, err := ioutil.ReadFile(file)
if err != nil {
fmt.Printf("read file err=%v", err)
}
// 把读取到的内容显示到终端
//fmt.Printf("%v", content) //[]byte 输出的都是切片
fmt.Printf("%v", string(content)) //[]byte 输出的都是数组
// 因为,我们没有显示Open文件,因此也不需要显示的Close文件
// 因为,文件的Open和Close被封装到ReadFile 函数内部
写文件操作实例:
func OpenFilename string(flag int perm FileMode)(file *File, err error)
说明:os.OpenFile是一个更一般性的文件打开函数,它会使用指定的选项(如 O_RDONLY等)、指定的模式(如0666等)打开指定名称的文件,如果操作成果,返回的文件对象可用I/O。如果出错,错误底层类型是*PathError
第二个参数:文件打开模式(可以组合)
第三个参数:权限控制(linux)r -> 4 w->2 x->1
FileMode选项在windows下无效,需要在Linux或Unix下才有效
案例:
-
创建一个新文件,写入5句"Hello,Garden"
// 创建一个新文件,写入内容 5句 "hello,Gardon" // 1.打开文件 d:/abc.txt filePath := "d:/abc.txt" file, err := os.OpenFile(filePath, os.O_WRONLY|os.O_CREATE, 0666) if err != nil { fmt.Printf("open file err=%v\n", err) return } // 及时关闭file句柄 defer file.Close() // 准备写入5句"hello Gardon" str := "hello,Gardon\r\n" // 因为有些有可能识别不了\n,比如记事本 // 写入时,使用带缓存的*Writer writer := bufio.NewWriter(file) for i := 0; i < 5; i++ { writer.WriteString(str) } // 因为Writer是带缓存,因此在调用WriterString方法时,其实 // 内容是先写入到缓存的,所以需要调用Flush方法,将缓冲的数据 // 真正的写入到文件中,否则文件中会没有数据 writer.Flush() -
打开一个存在的文件中,将原来的内容覆盖成新的内容10句"今天是情人节"
// 1.打开文件 d:/abc.txt filePath := "d:/abc.txt" //file, err := os.OpenFile(filePath, os.O_WRONLY|os.O_CREATE, 0666) file, err := os.OpenFile(filePath, os.O_WRONLY|os.O_TRUNC, 0666) // 第二个表示清空文件内容 if err != nil { fmt.Printf("open file err=%v\n", err) return } // 及时关闭file句柄 defer file.Close() // 准备写入5句"hello Gardon" str := "今天是情人节\r\n" // 写入时,使用带缓存的*Writer writer := bufio.NewWriter(file) for i := 0; i < 10; i++ { writer.WriteString(str) } // 因为Writer是带缓存,因此在调用WriterString方法时,其实 // 内容是先写入到缓存的,所以需要调用Flush方法,将缓冲的数据 // 真正的写入到文件中,否则文件中会没有数据 writer.Flush() -
打开一个存在的文件,在原来的内容追加内容"TODAY"
// 1.打开文件 d:/abc.txt filePath := "d:/abc.txt" //file, err := os.OpenFile(filePath, os.O_WRONLY|os.O_CREATE, 0666) //file, err := os.OpenFile(filePath, os.O_WRONLY|os.O_TRUNC, 0666) // 第二个表示清空文件内容 file, err := os.OpenFile(filePath, os.O_WRONLY|os.O_APPEND, 0666) // 第二个表示清空文件内容 if err != nil { fmt.Printf("open file err=%v\n", err) return } // 及时关闭file句柄 defer file.Close() // 准备写入5句"hello Gardon" str := "TODAY\r\n" // 写入时,使用带缓存的*Writer writer := bufio.NewWriter(file) for i := 0; i < 10; i++ { writer.WriteString(str) } // 因为Writer是带缓存,因此在调用WriterString方法时,其实 // 内容是先写入到缓存的,所以需要调用Flush方法,将缓冲的数据 // 真正的写入到文件中,否则文件中会没有数据 writer.Flush() -
打开一个存在的文件,将原来的内容读出显示在终端,并且追加5句"加油"
// 1.打开文件 d:/abc.txt filePath := "d:/abc.txt" //file, err := os.OpenFile(filePath, os.O_WRONLY|os.O_CREATE, 0666) //file, err := os.OpenFile(filePath, os.O_WRONLY|os.O_TRUNC, 0666) // 第二个表示清空文件内容 //file, err := os.OpenFile(filePath, os.O_WRONLY|os.O_APPEND, 0666) // 第二个表示清空文件内容 file, err := os.OpenFile(filePath, os.O_RDWR|os.O_APPEND, 0666) // 第二个表示清空文件内容 if err != nil { fmt.Printf("open file err=%v\n", err) return } // 及时关闭file句柄 defer file.Close() // 先读取原来文件的内容,并显示在终端 reader := bufio.NewReader(file) for { str, err := reader.ReadString('\n') if err == io.EOF { // 如果读取到文件的末尾 break } // 显示到终端 fmt.Print(str) } // 准备写入5句"hello Gardon" str := "TODAY\r\n" // 写入时,使用带缓存的*Writer writer := bufio.NewWriter(file) for i := 0; i < 10; i++ { writer.WriteString(str) } // 因为Writer是带缓存,因此在调用WriterString方法时,其实 // 内容是先写入到缓存的,所以需要调用Flush方法,将缓冲的数据 // 真正的写入到文件中,否则文件中会没有数据 writer.Flush() -
编写一个程序,将一个文件的内容,写入到另外一个文件。注:这两个文件以及存在了
说明:
-
使用ioutil.ReadFile / outil.WriteFile 完成写文件的任务
// 将d:/abc.txt 文件内容导入到 d:/test.txt中 // 1.首先将 d:/abc.txt内容读取到内存 // 2.将读取到的内容写入 d:/test/txt file1Path := "d:/abc.txt" file2Path := "d:/kkk.txt" data, err := ioutil.ReadFile(file1Path) if err != nil { // 说明读取文件有错误 fmt.Printf("read file err=%v", err) return } err = ioutil.WriteFile(file2Path, data, 0666) if err != nil { fmt.Printf("write file error=%v\n", err) }
-
判断文件是否存在:
golang判断文件或文件夹是否存在的方法为使用os.Stat()函数返回错误值进行判断:
- 如果返回的错误为nil,说明文件或文件夹存在
- 如果返回的错误类型使用os.IsNotExist()判断为true,说明文件或文件夹不存在
- 如果返回值的错误为其它类型,则不确定是否存在
拷贝文件:
将一张图片/电影/mp3/文件拷贝到另一个文件 e:/abc.jpg
func Copy(dst Writer, src Reader)(writen int64, err error)
注意:Copy函数是io包提供的
package main
import (
"bufio"
"fmt"
"io"
"os"
)
// 自己编写一个函数,接收两个文件路径 srcFileName dstFileName
func CopyFile(dstFileName string, srcFileName string) (written int64, err error) {
srcFile, err := os.Open(srcFileName)
if err != nil {
fmt.Printf("open file err=%v\n", err)
}
defer srcFile.Close()
// 通过srcfile,获取到reader
reader := bufio.NewReader(srcFile)
// 打开dstFileName
dstFile, err := os.OpenFile(dstFileName, os.O_WRONLY|os.O_CREATE, 0666)
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
// 通过dstFile,获取到Writer
writer := bufio.NewWriter(dstFile)
defer dstFile.Close()
return io.Copy(writer, reader)
}
func main() {
srcFile := "d:/abc.txt"
dstFile := "d:/ccc.txt"
_, err := CopyFile(dstFile, srcFile)
if err == nil {
fmt.Println("拷贝完成")
} else {
fmt.Println("拷贝错误 err=%v", err)
}
}
案例:
统计一个文件中含有的英文、数字、空格和其他字符数量
// 定义一个结构体,用于保存统计结果
type CharCount struct {
ChCount int // 记录英文个数
NumCount int // 记录数字的个数
SpaceCount int // 记录空格的个数
OtherCount int // 记录其他字符的个数
}
func main() {
// 思路:打开一个文件,创一个Reader
// 每读取一行,就去统计该行有多少个 英文、数字、空格和其他字符
// 然后将结果保存到一个结构体
fileName := "d:/abc.txt"
file, err := os.Open(fileName)
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
defer file.Close() // 打开之后就要及时关闭
// 定义个charCount实例
var count CharCount
// 创建一个Reader
reader := bufio.NewReader(file)
// 开始循环读取fileName的内容
for {
str, err := reader.ReadString('\n')
if err == io.EOF { // 读到文件末尾就退出
break
}
// 遍历str,进行统计
for _, v := range str {
switch {
case v >= 'a' && v <= 'z':
fallthrough // 穿透
case v >= 'A' && v <= 'Z':
count.ChCount++
case v == ' ' || v == '\t':
count.SpaceCount++
case v >= '0' && v < '9':
count.NumCount++
default:
count.OtherCount++
}
}
}
// 输出统计的结果看看
fmt.Printf("字符的个数为=%v 数字的个数为=%v 空格的个数为=%v 其它字符个数=%v",
count.ChCount, count.NumCount, count.SpaceCount, count.OtherCount)
}
命令行参数:
看一个需求
我们希望能够获取到命令行输入的各种参数,该如何处理?
基本介绍:
os.Args是一个string的切片,用来存储所有的命令行参数
package main
import (
"fmt"
"os"
)
func main() {
fmt.Println("命令行的参数有", len(os.Args))
// 遍历os.Args切片,就可以得到所有的命令行输入参数值
for i, v := range os.Args {
fmt.Printf("args[%v]=%v\n", i, v)
}
}
flag包解析命令行参数:
说明:前面的方式是比较原生的方式,对解析参数不是特别方便,特别是带有指定参数形式的命令行
比如:cmd>main.exe -f c:/aaa.txt -p 200 -u root这样的形式命令行 ,go设计者给我们提供了flag包,可以方便的解析命令行参数,而且参数的顺序可以随意
package main
import (
"flag"
"fmt"
)
func main() {
/*
fmt.Println("命令行的参数有", len(os.Args))
// 遍历os.Args切片,就可以得到所有的命令行输入参数值
for i, v := range os.Args {
fmt.Printf("args[%v]=%v\n", i, v)
}
*/
// 定义几个变量,用于接收命令行的参数值
var user string
var pwd string
var host string
var port int
// &user就是接收用户命令行输入的-u后面的参数值
// "u" 就是-u指定参数
// "" 默认值
// "用户名,默认为空" 说明
flag.StringVar(&user, "u", "", "用户名,默认为空")
flag.StringVar(&pwd, "pwd", "", "密码,默认为空")
flag.StringVar(&host, "h", "localhost", "主机名,默认为localhost")
flag.IntVar(&port, "port", 3306, "端口号,默认为3306")
// 这里有一个非常重要的操作,转换,必须调用该方法
flag.Parse()
// 输出结果
fmt.Printf("user=%v pwd=%v host=%v port=%v", user, pwd, host, port)
}
JSON:
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同事也易于机器解析和生成
2001年开始推广的数据格式,现在是主流的数据格式
JSON易于机器解析和生成,并有效提升网络传输效率,通常程序在网络传输时会先将数据(结构体、map等)序列化成json字符串,到接收方得到json字符串时,再反序列化恢复成原来的数据类型(结构体、map等)这种方式已然称为各个语言的标准
在JS中一切都是对象,JSON键值对是用来保存数据的一种方式
json序列化:
是指将key-value结构的数据类型(比如结构体、map、切片)序列化成json字符串的操作
package main
import (
"encoding/json"
"fmt"
)
// 定义一个结构体
type Monster struct {
Name string `json:"name"` // 反射机制,这里可以更改json序列化之后的名字,因为前端用小写更方便
Age int
Birthday string
sal float64
skill string
}
func testStruct() {
// 演示
monster := Monster{
Name: "牛魔王",
Age: 500,
Birthday: "2011-11-11",
sal: 8000.0,
skill: "牛魔拳",
}
// 将monster 序列化
data, err := json.Marshal(&monster)
if err != nil {
fmt.Printf("序列化错误 err=%v\n", err)
}
// 输出序列化后的结果
fmt.Printf("monster序列化后=%v\n", string(data))
}
// 将map序列化
func testMap() {
// 定义一个map
var a map[string]interface{}
// 使用map,需要make
a = make(map[string]interface{})
a["name"] = "孙悟空"
a["age"] = 25
a["address"] = "水帘洞"
// 将a这个map进行序列化
// 将monster序列化
data, err := json.Marshal(a)
if err != nil {
fmt.Printf("序列化错误 err=%v\n", err)
}
// 输出序列化后的结果
fmt.Printf("a map序列化后=%v\n", string(data))
}
// 演示对切片进行序列化,我们这个切片 []map[string]interface{}
func testSlice() {
var slice []map[string]interface{}
var m1 map[string]interface{}
// 使用map前,需要先make
m1 = make(map[string]interface{})
m1["name"] = "jack"
m1["age"] = "7"
m1["address"] = "北京"
slice = append(slice, m1)
var m2 map[string]interface{}
// 使用map前,需要先make
m2 = make(map[string]interface{})
m1["name"] = "tom"
m1["age"] = "20"
m1["address"] = [2]string{"墨西哥", "阿根廷"}
slice = append(slice, m2)
// 将切片序列化操作
data, err := json.Marshal(slice)
if err != nil {
fmt.Printf("序列化错误 err=%v", err)
}
// 输出序列化后的结果
fmt.Printf("slice 序列化后=%v\n", string(data))
}
// 对基本数据类型序列化,没有什么实际意义
func testFloat64() {
var num1 float64 = 2345.67
// 对num1进行序列化
data, err := json.Marshal(num1)
if err != nil {
fmt.Printf("序列化错误 err=%v\n", err)
}
// 输出序列化后的结果
fmt.Printf("基本数据类型 序列化后=%v\n", string(data))
}
func main() {
// 演示将结构体,map,切片进行序列化
testStruct()
testMap()
testSlice()
testFloat64()
}
注意事项:
对于结构体序列化,如果我们希望序列化后的key的名字,我们重新制定,那么可以给struct制定一个tag标签,声明type时名字还不能小写,因为这些参数需要跨包使用,所以不能小写,否则报错
json反序列化:
就是指将json字符串反序列化成对应的数据类型(比如结构体、map、切片)的操作
package main
import (
"encoding/json"
"fmt"
)
// 定义一个结构体
type Monster struct {
Name string
//Age int
//Birthday string
//sal float64
//skill string
}
// 演示将json字符串,反序列化成struct
func unmarshalStruct() {
// 说明str 在项目开发中,是通过网络传输获取到
str := "{\"name\":\"jack\"}"
// 定义一个Monster实例
var monster Monster
err := json.Unmarshal([]byte(str), &monster)
if err != nil {
fmt.Printf("unmarshal err=%v\n", err)
}
fmt.Printf("反序列化后 monster=%v\n", monster)
}
// 将json字符串反序列化成map
func unmarshalMap() {
str := "{\"name\":\"jack\"}" // 如果是程序读取的,则不用加\号
// 定义一个map
var a map[string]interface{}
// 反序列化
// 反序列化map,不需要make,因为make操作被封装到Unmarshal函数
err := json.Unmarshal([]byte(str), &a)
if err != nil {
fmt.Printf("unmarshal err=%v\n", err)
}
fmt.Printf("反序列化后 a=%v\n", a)
}
// 演示将json字符串,反序列化成切片
func unmarshalSlice() {
str := "[{\"name\":\"jack\"}]"
// 定义一个slice
var slice []map[string]interface{}
err := json.Unmarshal([]byte(str), &slice)
if err != nil {
fmt.Printf("unmarshal err=%v\n", err)
}
fmt.Printf("反序列化后 slice=%v\n", slice)
}
func main() {
unmarshalStruct()
unmarshalMap()
unmarshalSlice()
}
小结:
- 在反序列化一个json字符串时,要确保反序列化后的数据类型和原来序列化前的数据类型一致
- 如果json字符串是通过程序获取到的,则不需要再对 " 进行转义处理
三、单元测试
Go语言自带一个轻量级的测试框架testing和自带的go test命令来实现单元测试和性能测试,testing框架和其他语言中的测试框架类型,可以基于这个框架写针对相应函数的测试用例,也可以基于该框架写相应的压力测试用例,通过单元测试可以解决:
- 确保每个函数是可运行的,并且运行结果是正确的
- 确保写出来的代码性能是好的
- 单元测试能及时发现程序设计或实现的逻辑错误,使问题及早暴露,便于问题的定位解决,而性能测试的终点在于发现程序设计上的一些问题,让程序能够在高并发的情况下还能保持稳定
/*
go test -v
testing框架
1.将xxx_test.go的文件引入
import...
main(){
2.调用TestXxx()函数
}
*/
总结:
- 测试用例文件名必须以 _test.go结尾。比如cal_test.go,cal不是固定的
- 测试用例函数必须以Test开头,一般来说就是Test+被测试的函数名,比如TestAddUpper
- TestAddUpper(t *testing T)的形参类型必须是*testing T (可以看一下文档)
- 一个测试用例文件中,可以有多个测试用例函数,比如TestAddUpper、TestSub
- 运行测试用例指令
- cmd>go test [如果运行正确,无日志,错误时,会输出日志]
- cmd>go test -v [运行正确或是错误,都输出日志]
- 当出现错误时,可以使用t.Fatalf来格式化输出错误信息,并退出程序
- t.Logf方法可以输出相应的日志
- 测试用例函数,并没有放在main函数中,也执行了,这就是测试用例的方便之处
- PASS表示测试用例运行成,FAIL表示测试用例运行失败
- 测试单个文件,一定要带上被测试的原文件go test -v cal_test.go cal.go
- 测试单个方法 go test -v -test.run TestAddUpper
案例:
- 编写一个Monster结构体,字段Name、Age、Skill
- 给Monster绑定方法Store,可以将一个Monster变量(对象),序列化后保存到文件中
- 给Monster绑定方法ReStore,可以将一个序列化的Monster,从文件中读取,并反序列化为Monster对象,检查反序列化,名字正确
- 编程测试用例文件store_test.go,编写测试用例函数TestStore和TestRestore进行测试
// monster.go
package monster
import (
"encoding/json"
"fmt"
"io/ioutil"
)
type Monster struct {
Name string
Age int
Skill string
}
// 给Monster绑定方法Store,可以将一个Monster变量(对象),序列化后保存到文件中
func (this *Monster) Store() bool {
// 先序列化
data, err := json.Marshal(this)
if err != nil {
fmt.Println("marshal err=", err)
return false
}
// 保存到文件
filePath := "d:/monster.ser"
err = ioutil.WriteFile(filePath, data, 0666)
if err != nil {
fmt.Println("write file err=", err)
return false
}
return true
}
// 给Monster绑定方法ReStore,可以将一个序列化的Monster,从文件中读取
// 并反序列化为Monster对象,检查反序列化,名字正确
func (this *Monster) ReStore() bool {
// 1.先从文件中,读取序列化的字符串
filePath := "d:/monster.ser"
data, err := ioutil.ReadFile(filePath)
if err != nil {
fmt.Println("write file err=", err)
return false
}
// 2.使用读取到的data []byte,对反序列化
err = json.Unmarshal(data, this)
if err != nil {
fmt.Println("UnMarshal err=", err)
return false
}
return true
}
// monster_test.go
package monster
import "testing"
// 测试用例,测试Store方法
func TestStore(t *testing.T) {
// 先创建一个Monster实例
monster := Monster{
Name: "孙悟空",
Age: 500,
Skill: "变身",
}
res := monster.Store()
if !res {
t.Fatalf("monster.Store() 错误,希望为%v 实际为=%v", true, res)
}
t.Logf("monster.Store() 测试成功!")
}
四、goroutine(协程)和channel(管道)
需求:统计1-90000000的数字中,哪些是素数?
分析思路:
- 传统的方法,就是使用一个循环,循环的判断各个数是不是素数
- 使用并发或者并行的方法,将统计素数的任务分配给多个goroutine去完成,这时就会使用到goroutine
进程和线程的说明:
- 进程就是程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位
- 线程是进程的一个执行实例,是程序执行的最小单元,它是比进程更小的能独立运行的基本单位
- 一个进程可以创建核销毁多个线程,同一个进程中的多个线程可以并发执行
- 一个程序至少有一个进程,一个进程至少有一个线程
并发和并行:
- 多线程程序在单核上运行,就是并发
- 多线程程序在多核上运行,就是并行
Go协程和Go主线程:
- Go主线程(有程序员直接称为线程/也可以理解成进程),一个Go线程上,可以起多个协程,你可以这样理解,协程是轻量级的线程
- Go协程的特点
- 有独立的栈空间
- 共享程序堆空间
- 调度由用户控制
- 协程是轻量级的线程
案例:
编写一个程序,完成如下功能:
- 在主线程(可以理解成进程)中,开启一个goroutine,该协程每隔1s输入"hello world"
- 在主线程中也每隔一秒输出"hello,golang",输出10次后,退出程序
- 要求主线程和goroutine同时执行
- 画出主线程和协程执行流程图
// 在主线程(可以理解成进程)中,开启一个goroutine,该协程每隔1秒输出"hello world"
// 在主线程中也每隔一秒输出"hello,golang",输出10次后退出程序
// 要求主线程和goroutine同时执行
func test() {
for i := 1; i <= 10; i++ {
fmt.Println("hello world" + strconv.Itoa(i)) // strconv.Itoa() 将数字转成字符串
time.Sleep(time.Second)
}
}
func main() {
go test() // 开启一个协程
for i := 1; i <= 10; i++ {
fmt.Println("main() hello,golang" + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
小结:
- 主线程是一个物理线程,直接作用在cpu上的,是重量级的,非常耗费cpu资源
- 协程从主线程开启的,是轻量级的线程,是逻辑态。对资源消耗想对小
- Go的协程机制是最重要的特点,可以轻松开启上万协程。其他语言的并发机制一般基于线程,开启过多的线程,资源消耗大,这里就凸显Go在并发上的优势
MPG模式:
- M:操作系统的主线程(是物理线程)
- P:协程执行需要的上下文
- G:协程
MPG模式运行的状态:
- M0主线程正在执行Go协程,另外有三个协程在队列等待
- 如果Go协程阻塞,比如读取文件或者数据库等
- 这时就会创建M1主线程(也可能是从已有的线程池中取出M1),并且将等待的3个协程挂到M1下开始执行,M0的主线程下的Go仍然执行文件io的读写
- 这样MPG调度模式,可以既让G0执行,同时也不会让队列的其它协程一直阻塞,仍然可以并发/并行执行
- 等到G0不阻塞了,M0会被放到空闲的主线程继续执行(从已有的线程池中取),同时G0又会被唤醒
设置Go运行CPU数:
在Go1.8后,默认让程序运行在多个核上,可以不用设置了,Go1.8前,还是要设置一下,可以更高效的利用CPU
// 获取当前系统CPU的数量
num := runtime.NumCPU()
// 这里设置num-1的cpu运行go程序
runtime.GOMAXPROCS(num)
fmt.Println("num=",num)
需求:现在要计算1-200的各个数的阶乘,并且把各个数的阶乘放入到map中。最后显示出来,要求使用goroutine完成
分析思路:
- 使用goroutine来完成,效率高,但是会出现并发/并行安全问题
- 这里就提出了不同goroutine如何通信的问题
代码实现:
- 使用goroutine来完成(看看使用goroutine并发完成会出现什么问题?然后会去解决)
- 在运行某个程序时,如何知道是否存在资源竞争问题,方法简单,在编译该程序时,增加一个参数-race即可
不同的goroutine之间如何通信:
- 全局变量加锁同步
- channel
使用全局变量加锁同步改进程序
- 因为没有对全局变量m加锁,因此会出现资源争夺问题,代码会出现错误,提示concurrent map writes
- 解决方案:加入互斥锁
- 我们的数的阶乘很大,结果会越界,可以将求阶乘改成sum += unit64(i)
package main
import (
"fmt"
"sync"
"time"
)
// 思路
// 1.编写一个函数,来计算各个数的阶乘,并放入到map中
// 2.我们启动的协程多个,统计的将结果放入到map中
// 3.map应该做出一个全局的
var (
myMap = make(map[int]int, 10)
// 声明一个全局的互斥锁
// lock 是一个全局的互斥锁
// sync 是包: synchornized 同步
// Mutex: 是互斥
lock sync.Mutex
)
func test(n int) {
res := 1
for i := 1; i <= n; i++ {
res *= i
}
// 这里我们将res放入到myMap
// 加锁
lock.Lock()
myMap[n] = res
// 解锁
lock.Unlock()
}
func main() {
// 我们这里开启多个协程完成这个任务[20个]
for i := 1; i <= 20; i++ {
go test(i)
}
// 休眠10秒钟[第二个问题]
time.Sleep(time.Second * 5)
// 这里我们输出结果,变量这个结果
lock.Lock()
for i, v := range myMap {
fmt.Printf("map[%d]=%d\n", i, v)
}
lock.Unlock()
}
channel(管道)基本介绍:
为什么需要channel:
前面使用全局变量加锁同步来解决goroutine的通讯,但是不完美
- 主线程在等待所有的goroutine全部完成的时间很难确定,我们这里设置10秒,仅仅是估算
- 如果主线程休眠时间长了,会加长等待时间,如果等待时间短了,可能还有goroutine处于工作状态,这是也会随主线程的退出而销毁
- 通过全局变量加锁同步来实现通讯,也并不利用多个协程对全局变量的读写操作
- 上面种种分析都在呼唤一个新的通讯机制channel
channel介绍:
- channel本质就是一个数据结构-队列
- 数据是先进先出的[FIFO]
- 线程安全,多goroutine访问时,不需要加锁,就是说channel本身就是线程安全的,多个协程操作同一个管道时不会发生资源竞争
- channel时有类型的,一个string的channel只能存放string类型数据
定义/声明channel:
var 变量名 chan 数据类型
var inChan chan int // inChan用于存放int数据
var mapChan chan map[int]string // mapChan用于存放map[int]string类型
var perChan chan Person
var perChan2 chan *Person
说明:
- channel是引用类型
- channel必须初始化才能写入数据,即make后才能使用
- 管道是有类型的,intChan只能写入整数int
注意事项:
- channel中只能存放指定的数据类型
- channel数据放满之后就不能再放入了
- 如果从channel取出数据后,可以继续放入
- 在没有使用协程的情况下,如果channel数据取完了,再取,就会报dead lock
channel的遍历和关闭:
channe的关闭:
使用内置函数close可以关闭channel,当channel关闭后,就不能再向channel写数据了,但是仍然可以从该channel读取数据
channel的遍历:
channel支持for-range的方式进行遍历,注意两个细节
- 在遍历时,如果channel没有关闭,则会出现deadlock的错误
- 在遍历时,如果channel已经关闭,则会正常遍历数据,遍历完后,就会退出遍历
intChan := make(chan int, 3)
intChan <- 100
intChan <- 200
close(intChan) // 关闭管道
// 不能够再写入了 intChan <- 300
fmt.Println("okok")
// 当管道关闭后,读取数据是可以的
n1 := <-intChan
fmt.Println("n1=", n1)
// 遍历管道
intChan2 := make(chan int, 100)
for i := 0; i < 100; i++ {
intChan2 <- i * 2 // 放入100个数据到管道
}
// 在遍历时,如果channel没有关闭,则会出现deadlock的错误
close(intChan2)
// 遍历管道不能使用for循环
for v := range intChan2 {
fmt.Println("v=", v)
}
案例:
请完成goroutine和channel协同工作的案例,具体要求:
- 开启一个writeData协程,向管道intChan中写入50个整数
- 开启一个readData协程,向管道intChan中读取writeData写入数据
- 注意:writeData和readData操作的是同一个管道
- 主线程需要等待writeData和readData协程都完成工作才退出
package main
import (
"fmt"
)
//write data
func writeData(intChan chan int) {
for i := 1; i <= 50; i++ {
// 放入数据
intChan <- i
fmt.Println("writeData", i)
//time.Sleep(time.Second)
}
close(intChan)
}
// read data
func readData(intChan chan int, exitChan chan bool) {
for {
v, ok := <-intChan
if !ok {
break
}
//time.Sleep(time.Second)
fmt.Printf("readData 读到数据=%v\n", v)
}
// readData 读取完数据后,即任务完成
exitChan <- true
close(exitChan) // 关闭
}
func main() {
// 创建两个管道
intChan := make(chan int, 50)
exitChan := make(chan bool, 1)
go writeData(intChan)
go readData(intChan, exitChan)
// readData 读取完数据后,即任务完成
for {
_, ok := <-exitChan
if !ok {
break
}
}
}
管道的阻塞机制:
如果只是向管道写入数据,没有读取,就会出现阻塞而dead lock。写管道和读管道的频率不一致,无所谓
goroutine和channel结合:
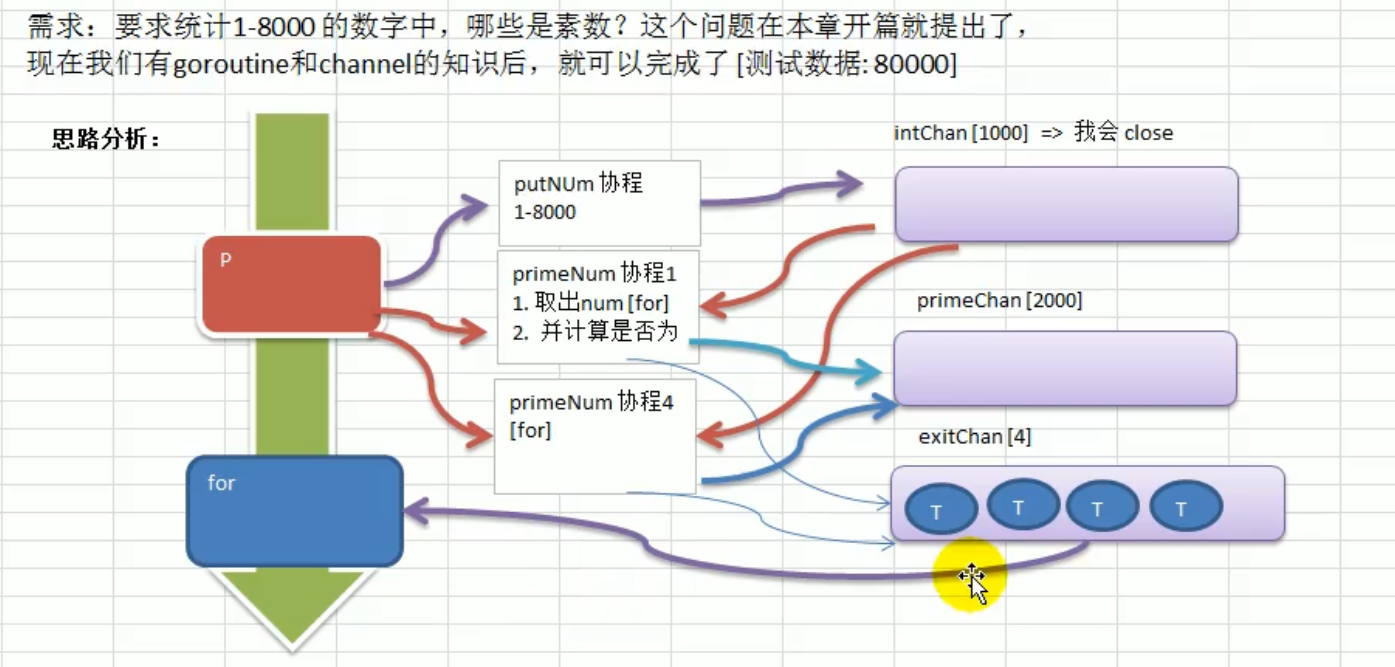
package main
import "fmt"
func putNum(intChan chan int) {
for i := 1; i <= 8000; i++ {
intChan <- i
}
// 关闭intChan
close(intChan)
}
// 从intChan取出数据,并判断是否为素数,如果是就放入到primeChan
func primeNum(intChan chan int, primeChan chan int, exitChan chan bool) {
// 使用for循环
var flag bool
for {
num, ok := <-intChan
if !ok { // intChan取不到
break
}
flag = true // 假设是素数
// 判断num是不是素数
for i := 2; i < num; i++ {
if num%i == 0 { // 说明该num不是素数
flag = false
break
}
}
if flag {
// 将这个数放入到primeChan
primeChan <- num
}
}
fmt.Println("有一个primeNum 协程因为取不到数据,退出")
// 这里还不能关闭primeChan
// 向exitChan写入true
exitChan <- true
}
func main() {
intChan := make(chan int, 1000)
primeChan := make(chan int, 2000) // 放入结果
// 标识退出的管道
exitChan := make(chan bool, 4) // 4个
// 开启一个协程,向intChan放入 1-8000 个数
go putNum(intChan)
// 开启4个协程,从intChan取出数据,并判断是否为素数,如果是就放入到primeChan
for i := 0; i < 4; i++ {
go primeNum(intChan, primeChan, exitChan)
}
// 这里主线程,进行处理
go func() {
for i := 0; i < 4; i++ {
<-exitChan
}
// 当我们从exitChan 取出4个结果,就可以放心的关闭primeNum
close(primeChan)
}()
// 比那里我们的primeNum,把结果取出
for {
res, ok := <-primeChan
if !ok {
break
}
// 将结果输出
fmt.Printf("素数=%d\n", res)
}
fmt.Println("main线程退出")
}
channel使用细节和注意事项
- channel可以声明为只读,或者只写性质
- channel只读和只写的最佳实践案例
// 管道可以声明为只读或只写
// 1.在默认情况下,管道是双向
// var cha1 chan int 可读可写
// 2.声明为只写
var chan2 chan<- int
chan2 = make(chan int,3)
chan2 <- 20
// num := <-chan2 error
fmt.Println("chan2=",chan2)
// 3.声明为只读
var chan3 <- chan int
num2 := <-chan3
// chan3<- 30 err
fmt.Println("num2",num2)
-
使用select可以解决从管道取数据的阻塞问题
// 传统的方法在遍历管道时,如果不关闭会阻塞而导致deadlock // 问题:在实际开发中,可能我们不好确定什么时候关闭该管道 // 可以使用select方式 // label: for { select { // 注意:这里如果intChan一直没有关闭,不会一直阻塞而deadlock // 会自动到下一个case匹配 case v := <- intChan: fmt.Printf("从intChan读取的数据%d\n",v) time.Sleep(time.Second) case v := <- stringChan: fmt.Printf("从stringChan读取的数据%s\n",v) time.Sleep(time.Second) default: fmt.Printf("都取不到",v) time.Sleep(time.Second) return } } -
goroutine中使用recover,解决协程中出现panic,导致程序崩溃问题
说明:
如果我们起了一个协程,但是这个协程出现了panic,如果我们没有捕获这个panic,就会造成整个程序崩溃,这时我们可以在goroutine中使用recover来捕获panic,进行处理,这样即使协程发生的问题,但是主线程仍然不受影响,可以继续执行
func sayHello() { for i := 0; i < 10; i++ { time.Sleep(time.Second) fmt.Println("hello,world") } } func test() { // 这里可以使用defer + recover defer func() { // 捕获test抛出的panic if err := recover(); err != nil { fmt.Println("test() 发生错误", err) } }() // 定义了一个map var myMap map[int]string myMap[0] = "golang" //error } func main() { go sayHello() go test() }
五、反射
- 反射可以在运动时动态获取变量的各种信息,比如变量的类型,类别
- 如果是结构体变量,还可以获取到结构体本身的信息(包括结构体的字段、方法)
- 通过反射,可以修改变量的值,可以调用关联的方法
- 使用反射,需要import("reflect")
反射的应用场景:
常见的应用场景有以下两种
-
不知道接口调用的哪个函数,根据传入参数在运行时,确定调用的具体接口,这种需要对函数或方法反射。例如如下的桥接模式
func bridge(funcPtr interface{},args...interface{})第一个参数funcPtr以接口的形式传入函数指针,函数参数args以可变参数的形式传入,bridge函数中可以用反射来动态执行funcPtr函数
-
对结构体序列化时,如果结构体有指定tag,也会使用到反射生成对应的字符串
反射的重要函数和概念:
-
reflect.TypeOf(变量名),获取变量的类型,返回reflect.Type类型
-
reflect.ValueOf(变量名),获取变量的值,返回reflect.Value类型reflect.Value是一个结构体类型
-
变量、interface{}和reflect.Value是可以相互转换的,这点在实际开发中,会经常使用到
var student Stu var num int /* 专门用于做反射 func test(b interface{}){ // 1.如何将interface{}转成reflect.Value rVal:=reflect.ValueOf(b) // 2.如何将reflect.Value -> interface{} iVal := rVal.Interface() // 3.如何将interface{}转成原来的变量类型,使用类型断言v:=iVal.(Stu) } */
案例:
-
请编写一个案例,演示对(基本数据类型、interface{}、reflect.Value)进行反射的基本操作
// 专门演示反射 func reflectTest01(b interface{}) { // 通过反射获取的传入的变量的 type kind 值 // 1.先获取到reflect.Type rTyp := reflect.TypeOf(b) fmt.Println("rType=", rTyp) // 2.获取到reflect.Value rVal := reflect.ValueOf(b) n2 := 2 + rVal.Int() fmt.Println("n2=", n2) fmt.Printf("rVal=%v rVal type=%T\n", rVal, rVal) // 3.下面将rVal转成interface{} iV := rVal.Interface() // 将interface{} 通过断言转成需要的类型 num2 := iV.(int) fmt.Println("num2=", num2) } func main() { // 编写一个案例 // 演示对(基本数据类型、interface{}、felect.Value)进行反射的基本操作 // 1.先定义一个int var num int = 100 reflectTest01(num) } -
请编写一个案例,演示对(结构体类型、interface{}、reflect.Value)进行反射的基本操作
// 专门演示反射[对结构体的反射] func reflectTest02(b interface{}) { // 通过反射获取的传入的变量的 type kind 值 // 1.先获取到reflect.Type rTyp := reflect.TypeOf(b) fmt.Println("rType=", rTyp) // 2.获取到reflect.Value rVal := reflect.ValueOf(b) // 3.下面将rVal转成interface{} iV := rVal.Interface() fmt.Printf("iV = %v iV = %T\n", iV, iV) // 运行时的反射 // 将interface{}通过断言转成需要的类型 // 这里就简单使用了一带检测的类型断言 // 同学们可以使用switch 的断言形式来做的更加的灵活 stu, ok := iV.(Student) if ok { fmt.Printf("stu.Name=%v\n", stu.Name) } } type Student struct { Name string Age int } func main() { // 2.定义一个Student的实例 stu := Student{ Name: "tom", Age: 20, } reflectTest02(stu) }
反射的注意事项和细节说明:
-
reflect.Value.Kind 获取变量的类别,返回的是一个常量
-
Type是类型,Kind是类型,Type和Kind可能是相同的,也可能是不同的
比如:var num int = 10 num的Type是int,Kind也是int
比如:var Stu Student stu的Type是 包名.Student,Kind是struct
-
通过反射可以让变量在interface{}和reflect.Value之间相互转换
变量<------->interface{}<--------->reflect.Value
-
使用反射的方式来获取变量的值(并返回对应的类型),要求数据类型匹配,比如x是int,那么就应该使用reflect.Value(x).Int()而不能使用其它的,否则报panic
-
通过反射来修改变量,注意当使用setXXX方法来设置需要通过对应的指针类型来完成,这样才能改变传入的变量的值,同时需要使用reflect.Value.Elem()方法
-
reflect.Value.Elem()如何理解
// fn.Elem() 用于获取指针指向变量,类似 var num = 10 var b *int = &num *b = 3
常量补充知识:
- 常量使用const修改
- 常量在定义的时候必须初始化赋值
- 常量不能修改
- 常量只能修饰bool、数值类型(int,float系列)、string类型
- 语法:const identifier [type] = value
举例说明下面写法是否正确:
const name = "tom" //ok
const tax float64=0.8 //ok
const a int // error
const b = 9/3 // ok
const c = getVal() // err
比较简洁的写法:
func main() {
const (
a = 1
b = 2
)
fmt.Println(a,b)
}
还有一种专业的写法
/*表示给a赋值为0
b在a的基础上+1
c在b的基础上+1
这种写法就比较专业了*/
func main() {
const (
a = iota // 一行递增一次
b
c
)
fmt.Println(a,b,c)
}
常量使用注意事项:
- Go中没有常量名必须字母大写的规范,比如TAX_RATE
- 仍然通过首字母的大小写来控制常量的访问范围
反射练习:
var str string = "tom" // ok
fs := reflect.ValueOf(&str) // ok -> string 需要取地址
fs.Elem().SetString("jack") //ok
fmt.Printf("%v\n",str) //jack
反射的最佳实践:
-
使用反射来遍历结构体的字段,调用结构体的方法,并获取结构体标签的值
Method方法和Call方法
package main import ( "fmt" "reflect" ) // 定义了一个Monster结构体 type Monster struct { Name string `json:"name"` Age int `json:"monster_age"` Score float32 Sex string } // 方法,显示s的值 func (s Monster) Print() { fmt.Println("---start---") fmt.Println(s) fmt.Println("---end---") } // 方法,返回两个数的和 func (s Monster) GetSum(n1, n2 int) int { return n1 + n2 } // 方法,接收四个值,给Monster赋值 func (s Monster) Set(name string, age int, score float32, sex string) { s.Name = name s.Age = age s.Score = score s.Sex = sex } func TestStruct(a interface{}) { // 获取reflect.Type类型 typ := reflect.TypeOf(a) // 获取reflect.Value类型 val := reflect.ValueOf(a) // 获取到a对应的类别 kd := val.Kind() // 如果传入的不是struct,就退出 if kd != reflect.Struct { fmt.Println("expect struct") return } // 获取结构体有几个字段 num := val.NumField() fmt.Printf("struct has %d fields\n", num) for i := 0; i < num; i++ { fmt.Printf("Field %d:值为=%v\n", i, val.Field(i)) // 获取到struct标签,注意需要通过reflect.Type来获取tag标签的值 tagVal := typ.Field(i).Tag.Get("json") // 反序列化 // 如果该字段于tag标签就显示,否则就不显示 if tagVal != "" { fmt.Printf("Field %d: tag为=%v\n", i, tagVal) } } // 获取到该结构体有多少方法 numOfMethod := val.NumMethod() fmt.Printf("struct has %d methods\n", numOfMethod) // var params []reflect.Value val.Method(1).Call(nil) // 调用的时候是按照函数的ASCII码排的 // 调用结构体的第1个方法Method(0) var params []reflect.Value params = append(params, reflect.ValueOf(10)) params = append(params, reflect.ValueOf(40)) res := val.Method(0).Call(params) // 传入的参数是[]reflect.Value fmt.Println("res=", res[0].Int()) // 返回的结果是[]reflect.Value } // 定义了一个Monster结构体 func main() { // 创建了一个Monster实例 var a = Monster{ Name: "黄鼠狼", Age: 400, Score: 30.8, } // 将Monster实例传递给了TestStruct实例 TestStruct(a) } -
使用反射的方法来获取结构体的tag标签,遍历字段的值,修改字段值,调用结构体方法(要求:通过传递地址的方式完成,在前面案例上修改即可)
-
定义了两个函数test1和test2,定义了一个适配器函数用作统一处理接口[了解]
-
使用反射操作任意结构体类型[了解]
-
使用反射创建并操作结构体
六、网络编程
Go的设计目标之一就是面向大规模后端服务程序
网络编程有两种:
- TCP socket编程,是网络编程的主流,之所以叫TCP socket编程,是因为底层是基于TCP/ip协议,比如QQ
- b/s结构的http编程,我们使用的浏览器去访问服务器时,使用的就是http协议,而http底层依旧是用tcp socket实现的,比如京东
OSI与TCP/ip参考模型:
OSI模型(理论):物理层-数据链路层-网络层-传输层-会话层-表示层-应用层
TCP/IP模型(现实):链路层-网络层-传输层-应用层
端口:不是物理意义的端口,而是指TCP/IP协议中的端口,是逻辑意义上的端口,一个IP地址的端口可以有65536(256*256)端口号只有整数,范围是从0到65535(256*256-1)
端口分类:
-
0号是保留端口
-
1-1024是固定端口,又叫名端口,即被某些程序固定使用,一般程序员不使用
22:SSH远程登录协议 23:telnet使用 21:ftp使用 25:smtp服务使用 80:iis使用 7:echo服务
-
1025-65536是动态端口
这些端口,程序员可以使用
端口使用注意:
- 在计算机(尤其是做服务器)要尽量少开端口
- 一个端口只能被一个程序监听
- 如果使用netstat -an可以查看本机有哪些端口在监听
- 可以使用 netstat -anb来查看监听端口的pid,在结合任务管理器关闭不安全的端口
服务端的处理流程:
- 监听端口
- 接收客户端的tcp连接,简历客户端和服务端的连接
- 创建goroutine,处理该链接的请求(通常客户端会通过链接发送请求包)
客户端的处理流程:
- 建立与服务端的链接
- 发送请求数据,接收服务器端返回的结果数据
- 关闭链接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号