
CMU15445 B+Tree
首先,上一个 task buffer pool 和这里的 b+tree 具体实现肯定不一样,关于具体的存储的层次也不一样;
在 buffer pool 里,数据以 page 为单位,在 b+tree 中,每个索引结点而言,存储了很多的 key-value,每个 value 对应一个子节点(子节点是用 page_id 来标识),需要从 key 找对应的 page_id,这里 page_id 就对应的是下一个子节点所对应的 page。
一些性质
- m 阶 b+ 树,除了根之外的每个节点都包含最少floor(m / 2)最多 m - 1 个关键字,任意节点的关键字最多 m - 1, 非叶子节点(内部节点)最多 m 个孩子指针,根没有最少关键字的限制
实时绘制树结构
这个非常非常重要,随机了 10000 个数据去随机插入然后删除,发现了有些 bug,然后 debug,查看树的结构发现了叶子节点合并的时候忘记了更改后继。
第一种,在程序运行过程中使用 Draw 函数会生成一个 dot 图像,安装插件后能够打开,tree.Draw(bpm, "name.dot")
第二种,同样能够生成 dot 图像
# 绘制 B+ 树的工具
$ # To build the tool
$ mkdir build
$ cd build
$ make b_plus_tree_printer -j$(nproc)
$ ./bin/b_plus_tree_printer
>> ... USAGE ...
>> 5 5 # set leaf node and internal node max size to be 5
>> f input.txt # Insert into the tree with some inserts
>> i "key" # insert
>> d "key" # delete
>> g my-tree.dot # output the tree to dot format
>> q # Quit the test (Or use another terminal)
插入
空树是一种特殊情况,树中只有一个叶子结点时也是特殊情况,直到这个唯一的叶子结点分裂,导致索引节点的产生,这时候情况才比较 general,根节点的分裂也是一个特殊情况。
- 递归搜索到叶子节点,搜索过程中保存路径上节点的 WritePageGuard,因为后续插入有可能对路径上的节点造成影响,避免其他线程读写
- 达到叶子节点,插入后不满就直接插,否则先分裂,再插入到分裂的节点中,然后需要对其中分裂出来的节点向父节点插入一个索引,有可能会导致父节点也会满之后递归处理即可。先插入到目标节点,然后再分裂相对少了很多工作量,但是这样做有两个隐患:
- page 已经达到了最大容量,再插入是不合法的
- 想象始终向一个节点的某一段插入,极端情况下(先插入)会导致大量移动,如果先分裂,再插入可以减少一半的移动带来的时间消耗
- 在进行修改过程中,需要持有 header_page 的 WritePageGurad 防止其他线程访问,这里通过 Context 来存储这个 header_page,注意点是在后续访问过程中不能手动再去 FetchPageWrite 这个header_page,不然会阻塞,应该去调用 Context 里面的 header_page
- 节点的 maxsize 表示的是节点的儿子指针数目,所以 leaf 节点的 maxsize 比 internal 节点的 maxsize 小 1,在给定的测试样例中构建 B+ 树时也可以看到。
删除
删除相对插入比较复杂一点,这里贴出 Google 的 Go 实现的 btree 删除部分实现代码以及 bbolt db 的 bplus tree 实现
点击查看代码
// growChildAndRemove grows child 'i' to make sure it's possible to remove an
// item from it while keeping it at minItems, then calls remove to actually
// remove it.
//
// Most documentation says we have to do two sets of special casing:
// 1) item is in this node
// 2) item is in child
// In both cases, we need to handle the two subcases:
// A) node has enough values that it can spare one
// B) node doesn't have enough values
// For the latter, we have to check:
// a) left sibling has node to spare
// b) right sibling has node to spare
// c) we must merge
// To simplify our code here, we handle cases #1 and #2 the same:
// If a node doesn't have enough items, we make sure it does (using a,b,c).
// We then simply redo our remove call, and the second time (regardless of
// whether we're in case 1 or 2), we'll have enough items and can guarantee
// that we hit case A.
func (n *node) growChildAndRemove(i int, item Item, minItems int, typ toRemove) Item {
if i > 0 && len(n.children[i-1].items) > minItems {
// Steal from left child
child := n.mutableChild(i)
stealFrom := n.mutableChild(i - 1)
stolenItem := stealFrom.items.pop()
child.items.insertAt(0, n.items[i-1])
n.items[i-1] = stolenItem
if len(stealFrom.children) > 0 {
child.children.insertAt(0, stealFrom.children.pop())
}
} else if i < len(n.items) && len(n.children[i+1].items) > minItems {
// steal from right child
child := n.mutableChild(i)
stealFrom := n.mutableChild(i + 1)
stolenItem := stealFrom.items.removeAt(0)
child.items = append(child.items, n.items[i])
n.items[i] = stolenItem
if len(stealFrom.children) > 0 {
child.children = append(child.children, stealFrom.children.removeAt(0))
}
} else {
if i >= len(n.items) {
i--
}
child := n.mutableChild(i)
// merge with right child
mergeItem := n.items.removeAt(i)
mergeChild := n.children.removeAt(i + 1)
child.items = append(child.items, mergeItem)
child.items = append(child.items, mergeChild.items...)
child.children = append(child.children, mergeChild.children...)
n.cow.freeNode(mergeChild)
}
return n.remove(item, minItems, typ)
}
删除是这三个里面最复杂的
- 如果某个节点删除后失衡,那么首先看能不能从兄弟节点借一个,但是这里我的想法是尽量把两个兄弟节点的关键字数量平均一下(left_size + right_size)/ 2。最后 grade scope 以及本地在根节点 maxsize = 255,
- 考虑如何减小合并节点时的开销;
迭代器
迭代器本质上就是在维护一个指针;
迭代器也需要有存储空间,这里我们有几个考量
- 局部变量保存迭代器
- 实现双向迭代器
Concurrency Control
这里遇到了好几个 bug
由于 spring 2023 p1 需要我们实现了 page_guard,这里实现起来相对简单,
这里记录一些遇到的 bug
- 一开始我使用了一个全局的 Context 用来实现读写时的锁,但是 Context 是共享的,导致多个线程其实还是只有一个 Context,一开始没有意识到这个,所以后面修改为局部变量;
- 对于 root_page_id_ 的访问应该需要用读写锁;有个写线程从根出发,删除,最终的结果会变更根,没更改根之前有个读线程读到了 root_page_id,判断根不为空,打算读但是被阻塞,写线程写完之后,更改了根,此时读线程独到的根是无效的。所以直到有可能更改 root_page_id_ 之前都应该持有 root_page_id 的写锁。
- 迭代器的使用不需要考虑多线程
- 这里我遇到了 heap overflow 的问题,最终通过将 B+Tree 初始化时设置的 leaf_node 的大小更改了一下,默认情况下好像是有可能 internal_max_size 和 leaf_max_size 可以一样的,但是考虑极端情况,这个值很大,因为 leaf_pag header 比 internal_page 的 header 多出来 4 个字节,所以 leaf_max_size 最大值我感觉应该不超过 internal_max_size - 1
多线程运行时出现的错误是随机的,可以在本地运行下面的命令进行简单的测试
while xxxx/build/test/b_plus_tree_concurrent_test ; do echo 1; done;
用到的一些函数
std::copy(src_array, src_array + n, des_array);
template<class InputIt, class OutputIt>
OutputIt copy(InputIt first, InputIt last,
OutputIt d_first)
{
for (; first != last; (void)++first, (void)++d_first)
*d_first = *first;
return d_first;
}
std::move_backward(array_ + st, array_ + ed, des_array_ + ed);
// 下面一个可能的实现,注意这里是 move,并且从后往前拷贝
template< class BidirIt1, class BidirIt2 >
BidirIt2 move_backward(BidirIt1 first, BidirIt1 last, BidirIt2 d_last) {
while (first != last) {
*(--d_last) = std::move(*(--last));
}
return d_last;
}
// 计算[a.begin(), target) 之间元素个数,在这里返回 target 的元素下标
auto index = std::distance(a.begin(), target);
bug
- 叶子节点删除的时候,有时候需要 merge,这时候需要删除一个叶子,更改后继,忘记更改后继
- 当我们从叶子开始删
ref
- https://zh.wikipedia.org/wiki/B%2B树
- https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
- https://cloud.tencent.com/developer/article/1461421
- https://oi-wiki.org/ds/bplus-tree/
- https://zhuanlan.zhihu.com/p/636275627
- https://zhuanlan.zhihu.com/p/647915936
- https://zhuanlan.zhihu.com/p/580014163
- https://zhuanlan.zhihu.com/p/590579860
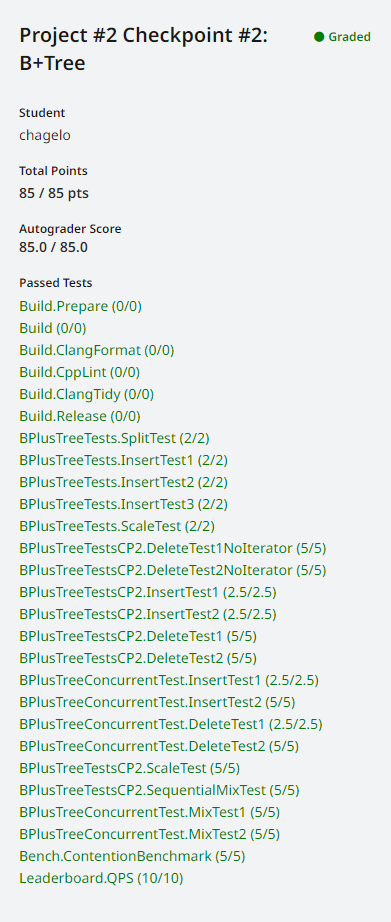
result
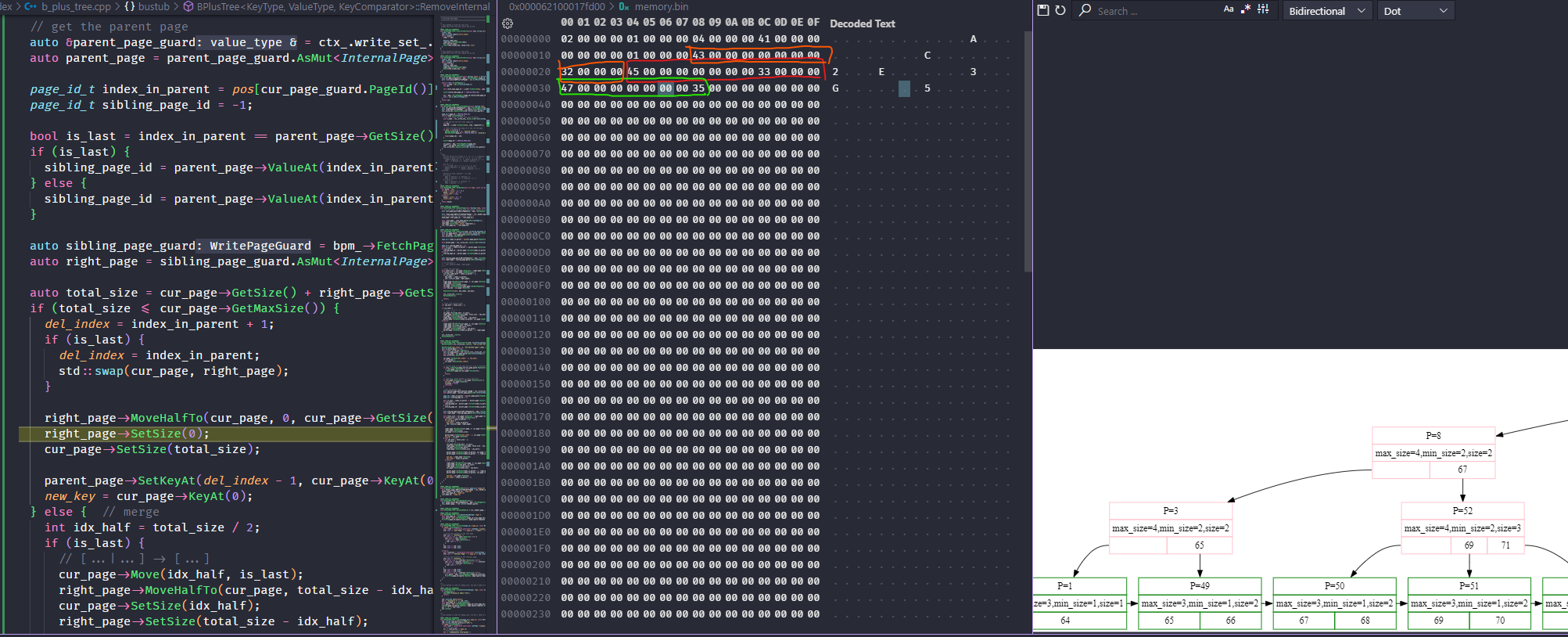
如图所示,b+ 树节点代表的 page 中,一个 kv 对占 12个字节。这个图里面第 12 个字节开始那个 0x41,0x01 也组成一队 kv,忘记圈了。其中 internal_page header 占 12 个字节,leaf_page header 占 16 个字节。
debug 人 debug 麻了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号