

PANDAS确定自动读取EXCEL文件的header(绕过开头的合并单元格,找字段名所在行数作为header)
Posted on 2022-01-01 19:32 o0o0o9 阅读(2175) 评论(0) 编辑 收藏 举报工作中经常需要处理大量的EXCEL文件入数据库,但很多人做表格第一行都是合并的表格名称,并且合并的行数不确定(即pandas read_excel时,多个文件的header不能确定),下面的def get_head可以自动判断header的值,下面的代码可以实现删掉一个文件夹里所有excel文件最上方的合并单元格。如下图所示
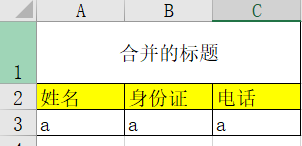
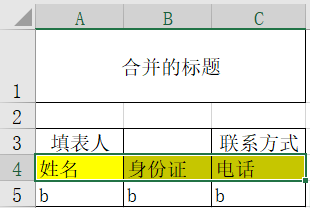
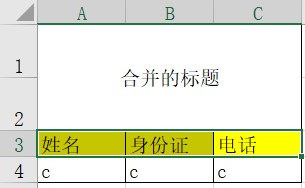
!!!!!注:下面的代码如果前五行里出现了不在字段名内的数据,可能识别错误。

1 # -*- coding:utf-8 -*- 2 # 读取当前目录下所有excel文件,并且输出第一行是excel的表头 3 import os 4 import pandas as pd 5 def get_head(df): # 根据df表第一个出现的非空字符最多的行数最为header的函数 6 list_temp=[] 7 for i in range(0,df.shape[0]): 8 list_temp.append(df.iloc[i].count()) 9 return list_temp.index(max(list_temp)) 10 11 files= os.listdir('./') 12 for f in files: 13 if f.endswith('.xls') or f.endswith('.xlsx'): 14 df_sheetname=pd.read_excel(f,sheet_name=None,nrows = 1) #只读一行确定有多少 15 excel_name=f.replace('.xlsx','').replace('.xls','') # 去掉文件名后的xlsx或xls 16 for s in list(df_sheetname): 17 df=pd.read_excel(f,sheet_name=s,header=None,dtype='str',nrows = 5) #只取前五行判断 18 head=get_head(df) # 使用函数得到 前五行里非空字符最多的行数(第一次出现的) 19 df=pd.read_excel(f,sheet_name=s,header=head,dtype='str') 20 df.to_excel(excel_name+'_'+s+'_result.xlsx',index=False) 21 #df.to_csv 22 #df.to_sql 23 print(excel_name+'_'+s+',OK!') 24 input("已经全部读取成功,请关闭页面")
本文来自博客园,作者:o0o0o9,转载请注明原文链接:https://www.cnblogs.com/o0o0o9/p/15755962.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具