树链剖分
引言
第一次接触树链/重链剖分的时候还是学习 \(Lca\), 没系统性的看过剖分, 今天刚重新学习了一下, 还是比较神奇的, 没想到一个树形结构能有这么多种神奇的操作, 总的来说, 树链剖分还是比较重要的一个策略
正文
定义
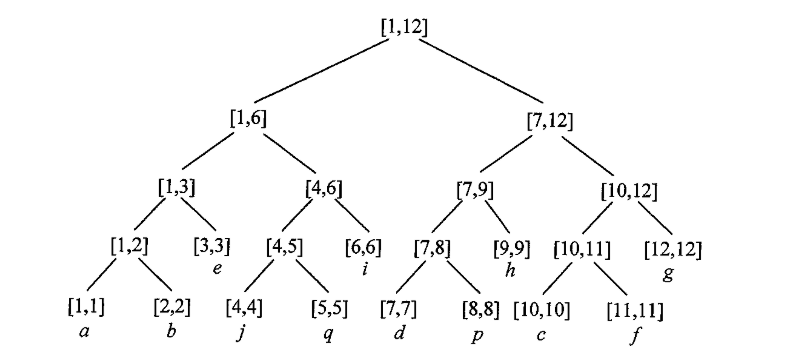
先给出图示
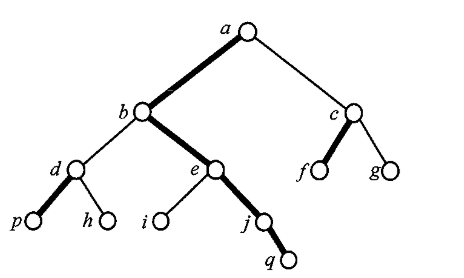
首先我们给出以下几个定义:
- 重儿子, 对于一个非叶子节点, 它的重儿子我们定义为, 以该节点为根的组成的子树大小最大的节点为重儿子, 例如图示中加粗的节点, 显然重儿子对于一个树来说只有一个
- 轻儿子, 对于一个非叶子节点, 除了重儿子就是轻儿子
- 重边, 由两个的重儿子组成的链称之为重边, 例如图示中的\((a, b)\), \((b, e)\) , 链中均为重儿子且连续
- 重链, 由连续的重边组成的链称为重链, 相邻节点均为父子关系, 例如图中的加粗链即是重链
- 轻边, 除了重边之外的边称为轻边, 两条重链之间存在一条轻边
- 链头, 重链的起点, 换句话说就是深度最浅的重儿子, 例如重链 \((a, b, e, j, q)\) 中, \(a\) 节点最浅, 故为链头
原理
利用上面剖好的链, 我们树形结构形成的重链不过超过 \(logn\) 条, 那么我们可以利用该性质, 从某个节点沿着各个链开始跳, 每次跳到链头, 最多只需要 \(logn\) 次就能到达根节点, 由于两个重链之间存在轻边, 那么也就是经过的轻边也小于 \(logn\) 条
下面给出证明:
从叶子节点出发, 考虑二叉树, 对于一条轻边, 其形成的子树大小必然小于 \(\frac{n}{2}\) 大小, 那么考虑两条重链开始跳, 从一条重链跳到另一条重链势必要经过一条轻边, 那么其子树大小必然会缩小到小于 \(\frac{1}{2}\), 这样我们最多经过 \(logn\) 条轻边即可到达根节点. 那么对于多叉树, 其缩小的范围会更大, 也就是不会超过 \(logn\) 条轻边
树剖求 \(LCA\)
考虑如何求 \(LCA\), 对于两个点 \(a, b\), 有以下步骤:
- 如果 \(a, b\) 的链头不一样, 那么谁的链头更深谁往上跳, 跳的时候可直接跳过轻边, 因为每个链头都是轻儿子, 则其父节点一定是重儿子, 依次递归
- \(a, b\) 在同一条重链上, 那么只需要比较谁的深度更浅即可, 浅的那个为最近公共祖先节点
代码
\(dfs1\) 是求出每个子树的大小 \(sz\) 以及每个节点的父节点 \(fa\), 还有重儿子 \(son\), 每个节点距离根节点的深度 \(dep\)
\(dfs2\) 是对每条重链都标记上链头 \(top\), 如果其有重儿子, 则直接递归, 一条重链上每个重儿子的链头都是一样的, 初始的链头是轻儿子
\(lca\) 即上述过程
#include <bits/stdc++.h>
#define int long long
using namespace std;
const int N = 1e6 + 10, mod = 1e9 + 7;
int dep[N], top[N], fa[N], sz[N], son[N];
vector<int> g[N];
void dfs1(int u){
sz[u] = 1, dep[u] = dep[fa[u]] + 1;
for (auto x : g[u]){
if (x == fa[u]) continue;
fa[x] = u;
dfs1(x);
sz[u] += sz[x];
if (sz[x] > sz[son[u]]) son[u] = x;
}
}
void dfs2(int u, int h){
top[u] = h;
if (son[u]) dfs2(son[u], h);
for (auto x : g[u]){
if (x == fa[u] || x == son[u]) continue;
dfs2(x, x);
}
}
int lca(int a, int b){
while (top[a] != top[b]){
if (dep[top[a]] > dep[top[b]]) a = fa[top[a]];
else b = fa[top[b]];
}
return dep[a] > dep[b] ? b : a;
}
signed main(){
std::ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
int n, m, s; cin >> n >> m >> s;
for (int i = 1; i <= n - 1; i++){
int a, b; cin >> a >> b;
g[a].push_back(b), g[b].push_back(a);
}
dfs1(s), dfs2(s, s);
while (m--){
int a, b;
cin >> a >> b;
cout << lca(a, b) << '\n';
}
return 0;
}
例题
P1. 重链剖分/树链剖分
在树剖过程中还有一些奇妙的性质, 例如一条重链中的节点均符合 \(dfs\) 序, 那么就可以根据 \(dfs\) 序进行某些操作, 具体操作在下面的例题中详细给出
【模板】重链剖分/树链剖分
题目描述
如题,已知一棵包含 \(N\) 个结点的树(连通且无环),每个节点上包含一个数值,需要支持以下操作:
-
1 x y z,表示将树从 \(x\) 到 \(y\) 结点最短路径上所有节点的值都加上 \(z\)。 -
2 x y,表示求树从 \(x\) 到 \(y\) 结点最短路径上所有节点的值之和。 -
3 x z,表示将以 \(x\) 为根节点的子树内所有节点值都加上 \(z\)。 -
4 x表示求以 \(x\) 为根节点的子树内所有节点值之和
输入格式
第一行包含 \(4\) 个正整数 \(N,M,R,P\),分别表示树的结点个数、操作个数、根节点序号和取模数(即所有的输出结果均对此取模)。
接下来一行包含 \(N\) 个非负整数,分别依次表示各个节点上初始的数值。
接下来 \(N-1\) 行每行包含两个整数 \(x,y\),表示点 \(x\) 和点 \(y\) 之间连有一条边(保证无环且连通)。
接下来 \(M\) 行每行包含若干个正整数,每行表示一个操作。
输出格式
输出包含若干行,分别依次表示每个操作 \(2\) 或操作 \(4\) 所得的结果(对 \(P\) 取模)。
样例 #1
样例输入 #1
5 5 2 24
7 3 7 8 0
1 2
1 5
3 1
4 1
3 4 2
3 2 2
4 5
1 5 1 3
2 1 3
样例输出 #1
2
21
提示
【数据规模】
对于 \(30\%\) 的数据: \(1 \leq N \leq 10\),\(1 \leq M \leq 10\);
对于 \(70\%\) 的数据: \(1 \leq N \leq {10}^3\),\(1 \leq M \leq {10}^3\);
对于 \(100\%\) 的数据: \(1\le N \leq {10}^5\),\(1\le M \leq {10}^5\),\(1\le R\le N\),\(1\le P \le 2^{30}\)。所有输入的数均在 int 范围内。
【样例说明】
树的结构如下:
各个操作如下:
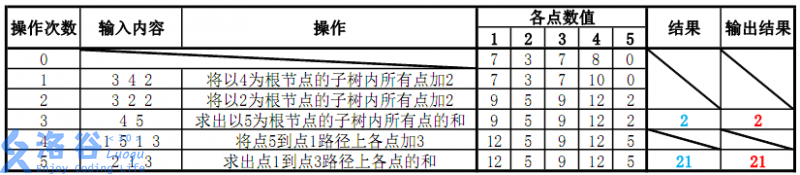
故输出应依次为 \(2\) 和 \(21\)。
思路
我们在 \(dfs2\) 函数中是先搜索的重儿子, 所以我们的重链具备一定的 \(dfs\) 的通有性质, 如果我们给每个点按照遍历次序编上编号, 会有如下特征
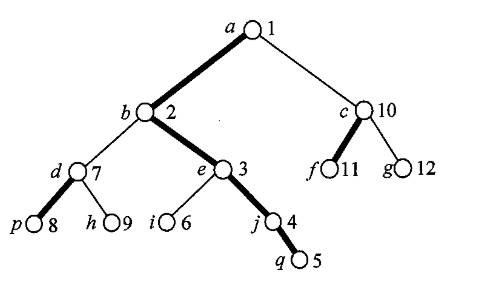
容易观察到, 每条重链内部是有序的, 每棵子树上的所有节点编号同样是有序的
所以我们有个很重要的性质 - 通过 \(dfs\) 序转化成序列, 从而在线段树上进行修改查询! 如图, 先建一颗线段树, 然后我们把线段树上的节点看作 \(dfs\) 序中的时间戳, 根据记录的编号权值分发到线段树叶节点上, \(dfs\) 序对应了原来树上的那些节点, 重链的节点在线段树上是连续的
注: 重链内部用线段树, 跳过轻边
- 修改 \(x\) 到 \(y\) 的权值, 我们进行类似 \(Lca\) 的操作, 当 \((a, b)\) 不处于同一条重链的时候, 我们直接区间修改深度深的那一条重链上的权值, 然后跳过轻边, 因为轻边的两个节点均在重链上. 重复操作, 直到处于同一条重链, 然后再修改链上的小区间即从 \(x\) 到 \(y\) 的这部分区间
- 查询 \(x\) 到 \(y\) 的权值, 过程类似于修改过程, 这里不再赘述
- 修改 \(x\) 的子树, 由于我们已知 \(Size_x\), 且子树内部也符合 \(dfs\) 序连续, 则我们直接对整棵子树修改即可
- 查询 \(x\) 的子树权值和, 类似上一步, 不再赘述
在树上跳重链的复杂度为 \(logn\), 每次跳跃在线段树上修改操作为 \(logn\), 共有 \(m\) 次询问, 故复杂度为: \(O(mlog^2n)\)
代码实现
#include <bits/stdc++.h>
#define int long long
#define ls u << 1
#define rs u << 1 | 1
using namespace std;
const int N = 1e6 + 10;
int mod, n, m, r, cnt;
int val1[N], val2[N], id[N], sz[N], dep[N], son[N], fa[N], top[N];
vector<int> g[N];
struct node{
int l, r, val, sum, tag;
}tr[N];
void pushup(int u){
tr[u].sum = tr[ls].sum + tr[rs].sum;
}
void pushdown(int u){
if(tr[u].tag){
tr[ls].sum = (tr[ls].sum + (tr[ls].r - tr[ls].l + 1) * tr[u].tag % mod) % mod;
tr[rs].sum = (tr[rs].sum + (tr[rs].r - tr[rs].l + 1) * tr[u].tag % mod) % mod;
tr[ls].tag += tr[u].tag, tr[rs].tag += tr[u].tag;
tr[u].tag = 0;
}
}
void build(int u, int l, int r){
if(l == r){
tr[u] = {l, r, val2[l], val2[l], 0};
return;
}
tr[u] = {l, r, 0, 0, 0};
int mid = l + r >> 1;
build(ls, l, mid), build(rs, mid + 1, r);
pushup(u);
}
void modify(int u, int l, int r, int x){
if(tr[u].l >= l && tr[u].r <= r){
tr[u].sum = (tr[u].sum + (tr[u].r - tr[u].l + 1) * x % mod) % mod;
tr[u].tag += x;
return;
}
pushdown(u);
int mid = tr[u].l + tr[u].r >> 1;
if(l <= mid) modify(ls, l, r, x);
if(r > mid) modify(rs, l, r, x);
pushup(u);
}
int query(int u, int l, int r){
if(tr[u].l >= l && tr[u].r <= r){
return tr[u].sum;
}
pushdown(u);
int mid = tr[u].l + tr[u].r >> 1, res = 0;
if(l <= mid) res += query(ls, l, r);
if(r > mid) res = (res + query(rs, l, r)) % mod;
return res;
}
void dfs1(int u){
sz[u] = 1, dep[u] = dep[fa[u]] + 1;
for(auto x : g[u]){
if(x == fa[u]) continue;
fa[x] = u;
dfs1(x);
sz[u] += sz[x];
if(sz[x] > sz[son[u]]) son[u] = x;
}
}
void dfs2(int u, int h){
top[u] = h, id[u] = ++cnt;
val2[cnt] = val1[u];
if(son[u]) dfs2(son[u], h);
for(auto x : g[u]){
if(x == fa[u] || x == son[u]) continue;
dfs2(x, x);
}
}
void update(int x, int y, int z){
while(top[x] != top[y]){
if(dep[top[x]] < dep[top[y]]) swap(x, y);
modify(1, id[top[x]], id[x], z);
x = fa[top[x]];
}
if(dep[x] > dep[y]) swap(x, y);
modify(1, id[x], id[y], z);
}
int get(int x, int y){
int res = 0;
while(top[x] != top[y]){
if(dep[top[x]] < dep[top[y]]) swap(x, y);
res = (res + query(1, id[top[x]], id[x])) % mod;
x = fa[top[x]];
}
if(dep[x] > dep[y]) swap(x, y);
res = (res + query(1, id[x], id[y])) % mod;
return res;
}
signed main()
{
std::ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
cin >> n >> m >> r >> mod;
for(int i = 1; i <= n; i++) cin >> val1[i];
for(int i = 1; i < n; i++){
int a, b; cin >> a >> b;
g[a].push_back(b), g[b].push_back(a);
}
dfs1(r), dfs2(r, r);
build(1, 1, n);
while(m--){
int op, x, y, z; cin >> op >> x;
if(op == 1) cin >> y >> z, update(x, y, z);
else if(op == 2) cin >> y, cout << get(x, y) % mod << '\n';
else if(op == 3) cin >> z, modify(1, id[x], id[x] + sz[x] - 1, z);
else cout << query(1, id[x], id[x] + sz[x] - 1) % mod << '\n';
}
return 0;
}
