

Python基础第一天

1989年,为了打发圣诞节假期,Guido开始写Python语言的编译器。Python这个名字,来自Guido所挚爱的电视剧Monty Python’s Flying Circus。他希望这个新的叫做Python的语言,能符合他的理想:创造一种C和shell之间,功能全面,易学易用,可拓展的语言
1991年,第一个Python编译器诞生。它是用C语言实现的,并能够调用C语言的库文件。从一出生,Python已经具有了:类,函数,异常处理,包含表和词典在内的核心数据类型,以及模块为基础的拓展系统
Granddaddy of Python web frameworks, Zope 1 was released in 1999
Python 1.0 - January 1994 增加了 lambda, map, filter and reduce.
Python 2.0 - October 16, 2000,加入了内存回收机制,构成了现在Python语言框架的基础
Python 2.4 - November 30, 2004, 同年目前最流行的WEB框架Django 诞生
Python 2.5 - September 19, 2006
Python 2.6 - October 1, 2008
Python 2.7 - July 3, 2010
In November 2014, it was announced that Python 2.7 would be supported until 2020, and reaffirmed that there would be no 2.8 release as users were expected to move to (2014年11月,宣布Python 2.7将支持到2020年,并重申将不会有2.8版本,用户尽快迁移到Python 3.4+)
Python 3.4+ as soon as possible
Python 3.0 - December 3, 2008
Python 3.1 - June 27, 2009
Python 3.2 - February 20, 2011
Python 3.3 - September 29, 2012
Python 3.4 - March 16, 2014
Python 3.5 - September 13, 2015
Python 3.6 - December 16,2016
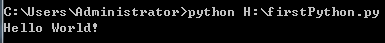
#!/usr/bin/env python print('Hello World!')
|
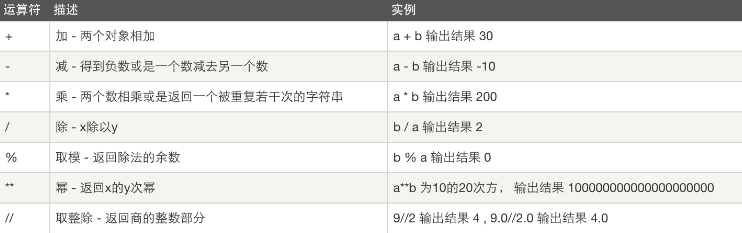
Bin(二进制)
|
Oct(八进制) |
Dec(十进制)
|
Hex(十六进制)
|
缩写/字符
|
解释
|
|
0000 0000
|
0
|
0
|
00
|
NUL(null)
|
空字符
|
|
0000 0001
|
1
|
1
|
01
|
SOH(start of headline)
|
标题开始
|
|
0000 0010
|
2
|
2
|
02
|
STX (start of text)
|
正文开始
|
|
0000 0011
|
3
|
3
|
03
|
ETX (end of text)
|
正文结束
|
|
0000 0100
|
4
|
4
|
04
|
EOT (end of transmission)
|
传输结束
|
|
0000 0101
|
5
|
5
|
05
|
ENQ (enquiry)
|
请求
|
|
0000 0110
|
6
|
6
|
06
|
ACK (acknowledge)
|
收到通知
|
|
0000 0111
|
7
|
7
|
07
|
BEL (bell)
|
响铃
|
|
0000 1000
|
10
|
8
|
08
|
BS (backspace)
|
退格
|
|
0000 1001
|
11
|
9
|
09
|
HT (horizontal tab)
|
水平制表符
|
|
0000 1010
|
12
|
10
|
0A
|
LF (NL line feed, new line)
|
换行键
|
|
0000 1011
|
13
|
11
|
0B
|
VT (vertical tab)
|
垂直制表符
|
|
0000 1100
|
14
|
12
|
0C
|
FF (NP form feed, new page)
|
换页键
|
|
0000 1101
|
15
|
13
|
0D
|
CR (carriage return)
|
回车键
|
|
0000 1110
|
16
|
14
|
0E
|
SO (shift out)
|
不用切换
|
|
0000 1111
|
17
|
15
|
0F
|
SI (shift in)
|
启用切换
|
|
0001 0000
|
20
|
16
|
10
|
DLE (data link escape)
|
数据链路转义
|
|
0001 0001
|
21
|
17
|
11
|
DC1 (device control 1)
|
设备控制1
|
|
0001 0010
|
22
|
18
|
12
|
DC2 (device control 2)
|
设备控制2
|
|
0001 0011
|
23
|
19
|
13
|
DC3 (device control 3)
|
设备控制3
|
|
0001 0100
|
24
|
20
|
14
|
DC4 (device control 4)
|
设备控制4
|
|
0001 0101
|
25
|
21
|
15
|
NAK (negative acknowledge)
|
拒绝接收
|
|
0001 0110
|
26
|
22
|
16
|
SYN (synchronous idle)
|
同步空闲
|
|
0001 0111
|
27
|
23
|
17
|
ETB (end of trans. block)
|
结束传输块
|
|
0001 1000
|
30
|
24
|
18
|
CAN (cancel)
|
取消
|
|
0001 1001
|
31
|
25
|
19
|
EM (end of medium)
|
媒介结束
|
|
0001 1010
|
32
|
26
|
1A
|
SUB (substitute)
|
代替
|
|
0001 1011
|
33
|
27
|
1B
|
ESC (escape)
|
换码(溢出)
|
|
0001 1100
|
34
|
28
|
1C
|
FS (file separator)
|
文件分隔符
|
|
0001 1101
|
35
|
29
|
1D
|
GS (group separator)
|
分组符
|
|
0001 1110
|
36
|
30
|
1E
|
RS (record separator)
|
记录分隔符
|
|
0001 1111
|
37
|
31
|
1F
|
US (unit separator)
|
单元分隔符
|
|
0010 0000
|
40
|
32
|
20
|
(space)
|
空格
|
|
0010 0001
|
41
|
33
|
21
|
!
|
叹号 |
|
0010 0010
|
42
|
34
|
22
|
"
|
双引号 |
|
0010 0011
|
43
|
35
|
23
|
#
|
井号 |
|
0010 0100
|
44
|
36
|
24
|
$
|
美元符 |
|
0010 0101
|
45
|
37
|
25
|
%
|
百分号 |
|
0010 0110
|
46
|
38
|
26
|
&
|
和号 |
|
0010 0111
|
47
|
39
|
27
|
'
|
闭单引号 |
|
0010 1000
|
50
|
40
|
28
|
(
|
开括号
|
|
0010 1001
|
51
|
41
|
29
|
)
|
闭括号
|
|
0010 1010
|
52
|
42
|
2A
|
*
|
星号 |
|
0010 1011
|
53
|
43
|
2B
|
+
|
加号 |
|
0010 1100
|
54
|
44
|
2C
|
,
|
逗号 |
|
0010 1101
|
55
|
45
|
2D
|
-
|
减号/破折号 |
|
0010 1110
|
56
|
46
|
2E
|
.
|
句号 |
|
00101111
|
57
|
47
|
2F
|
/
|
斜杠 |
|
00110000
|
60
|
48
|
30
|
0
|
数字0 |
|
00110001
|
61
|
49
|
31
|
1
|
数字1 |
|
00110010
|
62
|
50
|
32
|
2
|
数字2 |
|
00110011
|
63
|
51
|
33
|
3
|
数字3 |
|
00110100
|
64
|
52
|
34
|
4
|
数字4 |
|
00110101
|
65
|
53
|
35
|
5
|
数字5 |
|
00110110
|
66
|
54
|
36
|
6
|
数字6 |
|
00110111
|
67
|
55
|
37
|
7
|
数字7 |
|
00111000
|
70
|
56
|
38
|
8
|
数字8 |
|
00111001
|
71
|
57
|
39
|
9
|
数字9 |
|
00111010
|
72
|
58
|
3A
|
:
|
冒号 |
|
00111011
|
73
|
59
|
3B
|
;
|
分号 |
|
00111100
|
74
|
60
|
3C
|
<
|
小于 |
|
00111101
|
75
|
61
|
3D
|
=
|
等号 |
|
00111110
|
76
|
62
|
3E
|
>
|
大于 |
|
00111111
|
77
|
63
|
3F
|
?
|
问号 |
|
01000000
|
100
|
64
|
40
|
@
|
电子邮件符号 |
|
01000001
|
101
|
65
|
41
|
A
|
大写字母A |
|
01000010
|
102
|
66
|
42
|
B
|
大写字母B |
|
01000011
|
103
|
67
|
43
|
C
|
大写字母C |
|
01000100
|
104
|
68
|
44
|
D
|
大写字母D |
|
01000101
|
105
|
69
|
45
|
E
|
大写字母E |
|
01000110
|
106
|
70
|
46
|
F
|
大写字母F |
|
01000111
|
107
|
71
|
47
|
G
|
大写字母G |
|
01001000
|
110
|
72
|
48
|
H
|
大写字母H |
|
01001001
|
111
|
73
|
49
|
I
|
大写字母I |
|
01001010
|
112
|
74
|
4A
|
J
|
大写字母J |
|
01001011
|
113
|
75
|
4B
|
K
|
大写字母K |
|
01001100
|
114
|
76
|
4C
|
L
|
大写字母L |
|
01001101
|
115
|
77
|
4D
|
M
|
大写字母M |
|
01001110
|
116
|
78
|
4E
|
N
|
大写字母N |
|
01001111
|
117
|
79
|
4F
|
O
|
大写字母O |
|
01010000
|
120
|
80
|
50
|
P
|
大写字母P |
|
01010001
|
121
|
81
|
51
|
Q
|
大写字母Q |
|
01010010
|
122
|
82
|
52
|
R
|
大写字母R |
|
01010011
|
123
|
83
|
53
|
S
|
大写字母S |
|
01010100
|
124
|
84
|
54
|
T
|
大写字母T |
|
01010101
|
125
|
85
|
55
|
U
|
大写字母U |
|
01010110
|
126
|
86
|
56
|
V
|
大写字母V |
|
01010111
|
127
|
87
|
57
|
W
|
大写字母W |
|
01011000
|
130
|
88
|
58
|
X
|
大写字母X |
|
01011001
|
131
|
89
|
59
|
Y
|
大写字母Y |
|
01011010
|
132
|
90
|
5A
|
Z
|
大写字母Z |
|
01011011
|
133
|
91
|
5B
|
[
|
开方括号 |
|
01011100
|
134
|
92
|
5C
|
\
|
反斜杠 |
|
01011101
|
135
|
93
|
5D
|
]
|
闭方括号 |
|
01011110
|
136
|
94
|
5E
|
^
|
脱字符 |
|
01011111
|
137
|
95
|
5F
|
_
|
下划线 |
|
01100000
|
140
|
96
|
60
|
`
|
开单引号 |
|
01100001
|
141
|
97
|
61
|
a
|
小写字母a |
|
01100010
|
142
|
98
|
62
|
b
|
小写字母b |
|
01100011
|
143
|
99
|
63
|
c
|
小写字母c |
|
01100100
|
144
|
100
|
64
|
d
|
小写字母d |
|
01100101
|
145
|
101
|
65
|
e
|
小写字母e |
|
01100110
|
146
|
102
|
66
|
f
|
小写字母f |
|
01100111
|
147
|
103
|
67
|
g
|
小写字母g |
|
01101000
|
150
|
104
|
68
|
h
|
小写字母h |
|
01101001
|
151
|
105
|
69
|
i
|
小写字母i |
|
01101010
|
152
|
106
|
6A
|
j
|
小写字母j |
|
01101011
|
153
|
107
|
6B
|
k
|
小写字母k |
|
01101100
|
154
|
108
|
6C
|
l
|
小写字母l |
|
01101101
|
155
|
109
|
6D
|
m
|
小写字母m |
|
01101110
|
156
|
110
|
6E
|
n
|
小写字母n |
|
01101111
|
157
|
111
|
6F
|
o
|
小写字母o |
|
01110000
|
160
|
112
|
70
|
p
|
小写字母p |
|
01110001
|
161
|
113
|
71
|
q
|
小写字母q |
|
01110010
|
162
|
114
|
72
|
r
|
小写字母r |
|
01110011
|
163
|
115
|
73
|
s
|
小写字母s |
|
01110100
|
164
|
116
|
74
|
t
|
小写字母t |
|
01110101
|
165
|
117
|
75
|
u
|
小写字母u |
|
01110110
|
166
|
118
|
76
|
v
|
小写字母v |
|
01110111
|
167
|
119
|
77
|
w
|
小写字母w |
|
01111000
|
170
|
120
|
78
|
x
|
小写字母x |
|
01111001
|
171
|
121
|
79
|
y
|
小写字母y |
|
01111010
|
172
|
122
|
7A
|
z
|
小写字母z |
|
01111011
|
173
|
123
|
7B
|
{
|
开花括号 |
|
01111100
|
174
|
124
|
7C
|
|
|
垂线 |
|
01111101
|
175
|
125
|
7D
|
}
|
闭花括号 |
|
01111110
|
176
|
126
|
7E
|
~
|
波浪号 |
|
01111111
|
177
|
127
|
7F
|
DEL (delete)
|
删除
|
#!/usr/bin/env python print('你好 世界!')
#!/usr/bin/env python # -*- encoding: utf-8 -*- print('你好 世界!')
#!/usr/bin/env python print('你好 世界!')
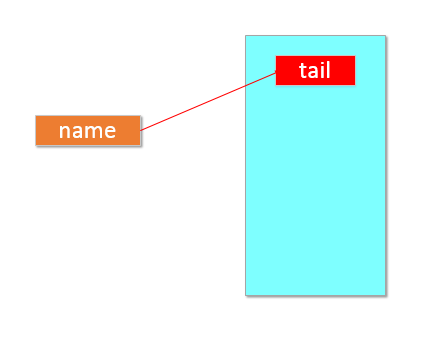
#将用户输入的内容赋值给 name 变量 name = input("请输入用户名:") #打印输入的内容 print(name)
name = input("请输入用户名:") age = input("请输入你的年龄:") hometown = input("请输入你的家乡地址:") print("Hello ",name, "your are ", age, "years old, you came from ",hometown)
请输入用户名:小红 请输入你的年龄:18 请输入你的家乡地址:中国 Hello 小红 your are 18 years old, you came from 中国
>>> a= 2**64
>>> type(a) #type()是查看数据类型的方法
<type 'long'>
>>> b = 2**30
>>> type(b)
<type 'int'>
>>> a= 2**64
>>> type(a) #type()是查看数据类型的方法
<type 'int'>
>>> name = "NZD" #双引号 >>> age = "24" #只要加引号就是字符串 >>> age2 = 24 #int >>> >>> msg = '''My name is NZD, I am 24 years old!''' #3个引号也可以 >>> >>> hometown = 'ShanDong' #单引号也可以
msg = ''' 今天我想写首小诗, 歌颂我的同桌, 你看他那乌黑的短发, 好像一只炸毛鸡。 ''' print(msg)
输出:
今天我想写首小诗,
歌颂我的同桌,
你看他那乌黑的短发,
好像一只炸毛鸡。
>>> name = 'NZD' >>> age = ' 24' >>> >>> name + age #相加其实就是简单拼接'NZD 24' NZD 24 >>> >>> name * 10 'NZDNZDNZDNZDNZDNZDNZDNZDNZDNZD'
>>> name = 'NZD' >>> age = 24 >>> name + age Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: cannot concatenate 'str' and 'int' objects #错误提示数字 和 字符 不能拼接
>>> a=3
>>> b=5
>>> a > b #不成立就是False,即假False
False
>>> a < b #成立就是True, 即真
True
name = input("Name:") age = input("Age:") job = input("Job:") hobbie = input("Hobbie:") #info里的每个%s就是一个占位符,本行的代表 后面拓号里的 name info = ''' ------------ info of %s ----------- Name : %s #代表 name Age : %s #代表 age job : %s #代表 job Hobbie: %s #代表 hobbie ------------- end ----------------- ''' %(name,name,age,job,hobbie) # 这行的 % 号就是 把前面的字符串 与拓号 后面的 变量 关联起来 print(info)
Name:小红 Age:18 Job:Teacher Hobbie:running ------------ info of 小红 ----------- Name : 小红 #代表 name Age : 18 #代表 age job : Teacher #代表 job Hobbie: r #代表 hobbie ------------- end -----------------


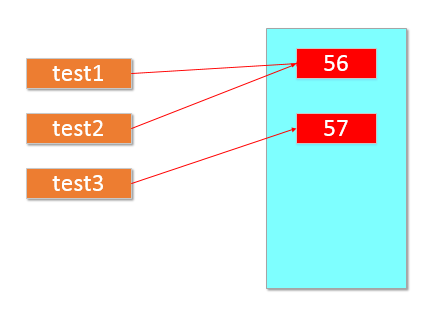
针对逻辑运算的进一步研究:在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算
print(3>4 or 4<3 and 1==1) # 3>4 or 假 = 假 print(1 < 2 and 3 < 4 or 1>2 ) # 真 or 1>2 = 真 print(2 > 1 and 3 < 4 or 4 > 5 and 2 < 1) # 真 or 假 = 真 print(1 > 2 and 3 < 4 or 4 > 5 and 2 > 1 or 9 < 8) # 假 or 假 or 9 < 8 >> 假 or 9 < 8 = 假 print(1 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6) # 假 or 假 and 9 > 8 or 7 < 6 >> 假 or 假 or 7 < 6 = 假 print(not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6) # 假 and 3 < 4 or 假 or 7 < 6 >> 假 or 假 or 7 < 6 = 假
输出:
False
True
True
False
False
False
例2:
print(8 or 4) #真 8 print(0 and 3) #假 0 print(4 and 3) #真 3 print(0 and 3) #假 0 print(0 or 3) #真 3 print(0 or 4 and 3 or 7 or 9 and 6) # 0 or 3 or 7 or 9 and 6 >> 0 or 3 or 7 or 6 >> 3 or 7 or 6 >> 3
输出:
8 0 3 0 3 3
1)、6 or 2 > 1 6 2)、3 or 2 > 1 3 3)、0 or 5 < 4 False 4)、5 < 4 or 3 3 5)、2 > 1 or 6 True 6)、3 and 2 > 1 True 7)、0 and 3 > 1 0 8)、2 > 1 and 3 3 9)、3 > 1 and 0 0 10)、3 > 1 and 2 or 2 < 3 and 3 and 4 or 3 > 2 2
>>> 'in' in ['and','in','not in'] True >>> 'x' in 'zxcvbnm' True >>> 'x' not in 'zxcvbnm' False
AgeOfOldboy = 48
if AgeOfOldboy > 50 :
print("Too old, time to retire..")
else:
print("还能折腾几年!")
var age = 56 if ( age < 50){ console.log("还能折腾") console.log('可以执行多行代码') }else{ console.log('太老了') }
同一级别的代码,缩进必须一致
score = int(input("输入分数:")) if score > 100: print("我擦,最高分才100...") elif score >= 90: print("A") elif score >= 80: print("B") elif score >= 60: print("C") elif score >= 40: print("D") else: print("太笨了...E")
count = 0 while count <= 100: # 只要count<=100就不断执行下面的代码 print("loop ", count) if count == 5: #只要count=5就跳出while循环 break count += 1 # 每执行一次,就把count+1,要不然就变成死循环啦,因为count一直是0 print("-----out of while loop ------")
输出:
loop 0 loop 1 loop 2 loop 3 loop 4 loop 5 -----out of while loop ------
count = 0 while count <= 100: count += 1 if count > 5 and count < 95: # 只要count在6-94之间,就不走下面的print语句,直接进入下一次loop continue print("loop ", count) print("-----out of while loop ------")
输出:
loop 1 loop 2 loop 3 loop 4 loop 5 loop 95 loop 96 loop 97 loop 98 loop 99 loop 100 loop 101 -----out of while loop ------
count = 0 while count <= 5: count += 1 if count == 3: pass print("Loop", count) else: print("循环正常执行完啦") print("-----out of while loop ------")
输出:
Loop 1 Loop 2 Loop 3 Loop 4 Loop 5 Loop 6 循环正常执行完啦 -----out of while loop ------
count = 0 while count <= 5 : count += 1 if count == 3: break print("Loop",count) else: #while循环没有break,则执行else语句 print("循环正常执行完啦") print("-----out of while loop ------")
输出:
Loop 1 Loop 2 -----out of while loop ------
22、相关练习
1、使用while循环输入 1 2 3 4 5 6 8 9 10
n = 0 while n < 10: n += 1 if n == 7: print() n += 1 # continue print(n)
2、求1-100的所有数的和
n = 0 sum = 0 while n < 100: n += 1 sum += n print(sum)
3、输出 1-100 内的所有奇数
n = 0 sum = 0 while n < 100: n += 1 if n%2 == 1: sum += n print(sum)
4、输出 1-100 内的所有偶数
n = 0 sum = 0 while n < 100: n += 1 if n%2 == 0: sum += n print(sum)
5、求1-2+3-4+5 ... 99的所有数的和
n = 0 sum = 0 while n < 99: n += 1 if n%2 == 1: sum += n else: sum -= n print(sum)
6、用户登陆(三次机会重试)
n = 0 NAME = '中国' PASSWD = 'China' while True: n += 1 name = input("请输入您的用户名:") passwd = input("请输入密码:") if name == NAME and passwd == PASSWD: print("恭喜您登录成功!") break elif (name != NAME or passwd != PASSWD) and n < 3: print("用户名错误或密码错误,您还有%d次机会,请继续输入!" % (3-n)) continue elif (name != NAME or passwd != PASSWD) and n == 3: print("用户名错误或密码错误,登录失败!") break
n = 0 NAME = '中国' PASSWD = 'China' while n < 3: n += 1 name = input("请输入您的用户名:") passwd = input("请输入密码:") if name == NAME and passwd == PASSWD: print("恭喜您登录成功!") break elif n == 3: print("登录失败!") else: print("用户名错误或密码错误,您还有%d次机会,请继续输入!" % (3-n))
n = 1 NAME = '中国' PASSWD = 'China' while n <= 3: name = input("请输入您的用户名:") passwd = input("请输入密码:") if name == NAME and passwd == PASSWD: print("恭喜您登录成功!") break else: print("用户名错误或密码错误,您还有%d次机会,请继续输入!" % (3-n)) if n == 3: flag = input("是否继续(y/n):").strip() if flag == 'y': n = 0 n += 1 else: print('登录失败!')
