
一、什么是base 64编码
Base64是网络上最常见的用于传输 8Bit字节代码的编码方式之一。
base64 编码可以用于在 HTTP环境下传递较长的标识信息。例如:在Java Persistence系统Hibernate中,就采用了Base64来将一个较长的唯一标识符(一般为128-bit的UUID)编码为一个字符串,用作HTTP表单和HTTP GET URL中的参数。在其他应用程序中,也常常需要把二进制数据编码为适合放在URL(包括隐藏表单域)中的形式。
这时采用base64编码不仅比较简单,同时还具有不可读性,即所编写的数据不会被人眼所直接识别。
但是,标准的 Base64 编码并不适合直接放到URL里面传输,因为URL编码器会把标准 Base64中的(/)和(%)变形为例如(%XX)的形式,并且这些(%)在存入数据库的时候还要进行转换,因为ANSI SQL中已将(%)用作通配符。
为了解决这个问题,可以采用一种用于URL的改进 Base64编码,不在末尾填充(=)号,并且将标准Base64 中的(+)和(/)分被改成了(*)和(-),这样就避免了在URL 编码解码和数据库存储时所要做的转换,避免了编码长度在此过程中的增加,并且统一了数据库、表单等处对象标识符的格式。
Base64 要求把每三个 8Bit的字节转换为四个 6Bit的字节(3*8 = 6*4 = 24),然后再把 6Bit再添加两位高位 0,组成四个 8Bit 的字节,也就是说,转换后的字符串理论上将要比原来的长1/3。
为什么要使用Base64编码?
Base64 是一种很常见的编码方式,利用它可以将任何二进制的字符编码为可以打印的64个之中,这样,无论是图片还是中文文本等都可以编码成只有 ASCII 的纯文本。
为什么要进行这样的转换呢?
最初主要是在EMail领域,早期的一些邮件网关只识别ASCII,如果发现邮件中有其他的字符,就会将这些 “异类” 字符过滤掉,这样中文的邮件或是有些附带图片的邮件通过这些网关的时候就会发生问题,于是将中文和图片都使用 Base64 编码然后再进行传输,接受后再解码就可以克服了这个问题。Base64除了可以在上面这样相似的场合使用,还可以用于简单的加密。
二、Base64 的编码和解码
在Base64 中所有可能出现的字符总共有 64个:(A~Z)、(a~z)、(0~9)、(+ 和 /)还有末尾的 =,如下表所示。
Base64 编码表
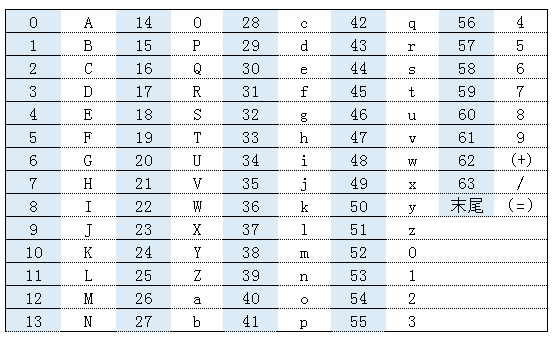
编码和解码的方式是:
从输入缓冲中依次取出字符,
第一个字符,从最高位开始取出 6个Bit,这六个Bit的值的范围在 0~63,将这个值作为索引,对应上面的表格,找到相应的字符,这就是第一个Base64 后的字符,
第二个字符,将第一个字符左移 2位与第二个字符右移 4位组成 6个Bit,得到第二个 Base64 字符;
第三个字符,将第二个字符左移 2位,再加上第三个字符右移 6位,即得到第三个 Base64字符;
第四个字符,取第三个字符的右 6位获得第四个目标字符。
以此类推,从左向右没凑足 6个Bit就转成一个 Base64字符,由于缓冲中 每 3个字符包含24个Bit,这24个bit正好可以转成 4个Base64位字符,所以每3个字符能组成一个转换循环。
如果输入缓冲中字符的个数正好是 3的整数倍,那么结果就是 4的整数倍,两者的长度是 3:4 关系;
但是如果输入字符不是 3的整数倍,这就涉及到了末尾填充问题。
输入缓冲的末尾,可能会余下一个字符,或是两个字符:
1、如果余下一个字符,前 6个bit 转换为 base64 ,剩下的低 2位要右边补0,凑成 6bit,然后转换成 Base64,为了让解析者了解这个情况,在输出缓冲的最后要加上两个 (=);
2、如果剩下两个字符,同样转换出两个 Base64字符之后,在剩下的4个 Bit 右边补 0,凑成 6个bit,然后转成 base64 ,同样在缓冲的末尾要补上一个(=);
由此可见 Base64 后的字符串,长度一定是 4的整数倍,末尾有一个、两个又或者没有(=)。
注意:为了兼容某些邮件服务器,Base64后的字符串经常要插入来确保每一行,不超过76个字符,解析时要超过它们。
编码规则:1、把3个字符变成 4个字符;2、每76个字符加一个换行符;3、最后的结束符也要处理
例如:
- 转换前:aaaaaabb ccccdddd eeffffff
- 转换后:00aaaaaa 00bbcccc 00ddddee 00ffffff
上面的三个字节是原文,下面的四个字节是转换后的Base64 编码,其前两位均为0.
实例:
- 转换前 10101101 10111010 01110110
- 转换后 00101011 00011011 00101001 00110110
十进制 43 27 41 54;对应表中的值 r b p 2
所以上面的24位编码,编码后的 Base64值为 rbp2
如果想要解码,把rbq2 的二进制位连接上再重组得到三个 8位值,得出原码(解码只是编码的逆过程)
三、base64的弊端
在前端开发中使用base64 的弊端
1、图片在进行 base64 编码之后要比原图大,跟原图片相比base64要比原图片的大小要大1/3。
2、而且如果将大图片编码到 html或是 CSS中,就会造成文件体积明显增加,会影响网页打开的速度。
3、如果使用外链图片,就可以在页面渲染完之后继续在单独加载图片,不会造成网页阻塞。
4、如果base64 是被编码到 css或Js中的,因为css和 js是可以缓存的,所以在文件中的base64编码也是可以缓存的,单独的base64是无法缓存的;
5、使用base64 还有一个弊端,那就是 IE的兼容性问题。IE8之下的浏览器不支持data url,IE8虽然开始支持data url,但是却有大小限制(32k);
6、如果使用的构建工具比较落后·,手动插入大量的base64是很恐怖的一件事情,编辑器会卡。大量的编码字符,也会影响代码的美观。
在线编辑工具:
参考文章:
