数据库索引数据结构btree,b-tree和b+tree树
1.B-Tree树的介绍:
1)是一种适用于外查找的树,它是一种平衡的多叉树,称为B树
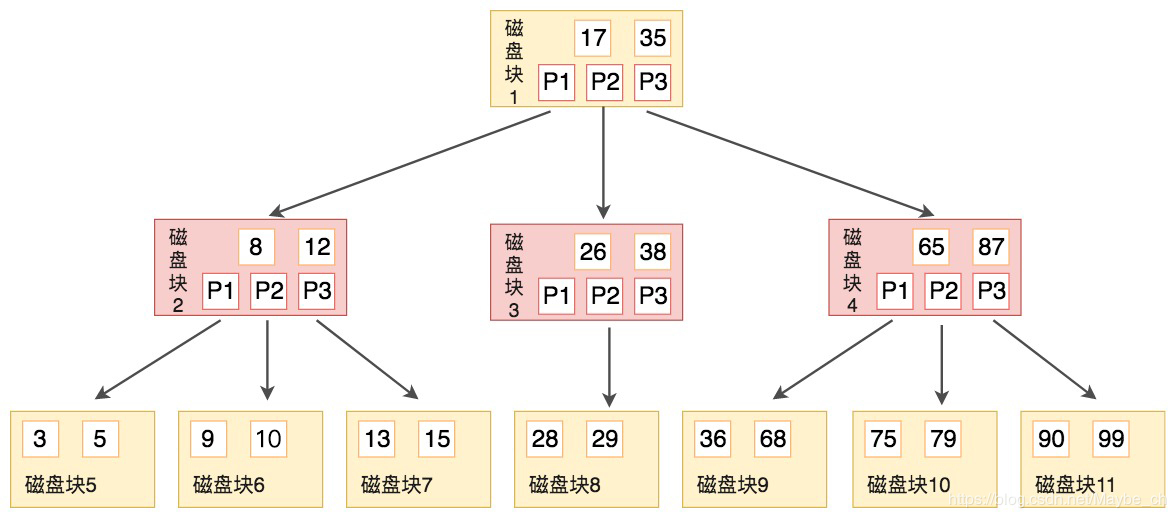
2)一颗M阶B-Tree具有的特性:
1)如果根结点不是叶子结点的话,那么它的子结点数至少为2
2)除结点与叶子结点外,其他结点的孩子数为[ceil(m/2),m]个,ceil函数表示向上取整数
3)所有叶子结点都在同一层(因为它是分裂向上生成父结点的)
4)各个结点的关键字都是从小到大排序的,
5)且每个结点的关键字数量满足[ceil(m / 2)-1,m-1],floor为向下取整函数
6)父结点的关键字的左孩子都小于它,右孩子都大于它.
3)B-Tree树的插入操作
1)插入新元素,如果叶子结点的空间足够,则插入其中,根据与根节点的判断其插入的位置
2)如果结点空间满了的话,进行分裂,将结点中的中间关键字上移作为父节点,将结点中的其他的一半关键字分别作为此结点的左右结点
4)B-Tree树的删除操作
1)先查找B-tree树需要删除的元素,如果该元素在B-tree中存在,则将该元素在结点中删除
2)删除元素后,判断元素有无左右孩子结点,如果有,则上移与删除元素相近的孩子结点元素到父结点中;
3)然后判断所有结点中元素个数个数是否有小于ceil(m/2)-1的,找到其相邻兄弟元素个数是否大于ceil(m/2)-1
如果足够:
1)向父节点借一个元素,同时将借的元素的孩子结点中相邻后继元素上移到父结点中;
如果不够:
2)其相邻兄弟借完后结点元素个数少于floor(m/2),那将父结点的元素下移到要合并的左右子结点中,然后进行合并(且父元素的值应该是处于左右孩子之间的)
3)由于索引文件,无论是插入还是删除B-Tree结点,不断地分裂和合并结点来维持B-Tree结构是非常昂贵的操作,所有数据库的索引都采用的B+tree
2.B+Tree树的介绍:
1)MySQL索引采用B+Tree,它是应文件系统所需而产生的一种B-tree的变形树
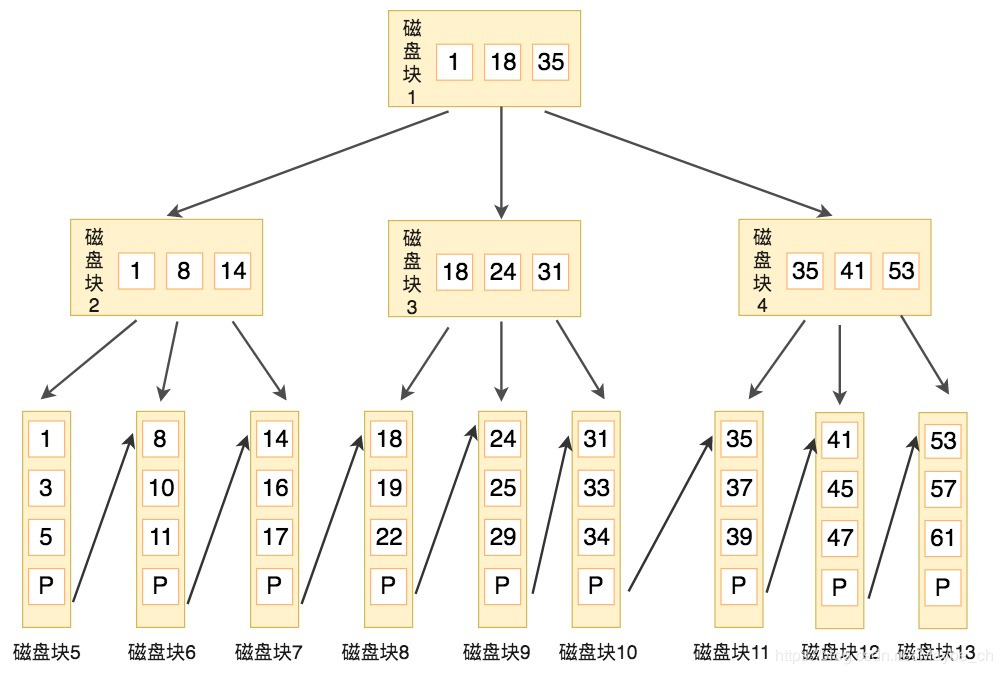
2)与B-Tree树的差异:
1)非叶子结点的子树指针与关键字个数相同
2)B+树父结点中记录,存储的是下层子树中的最小值
3)所有叶子结点通过一个链指针相连
4)所有关键字都在叶子结点出现;
3)B+Tree的分裂:
1)当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;
2)B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
3.B*Tree的介绍:
1)B*Tree是B+树的变体,在B+Tree的非根和非叶子结点再增加指向兄弟的指针
2)B*Tree的区别:
1)B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2);
2)B*树的分裂:
1)当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,
2)再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了)
3);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
4.总结:
B-树:多路搜索树,每个结点存储floor(M/2)到M-1个关键字,非叶子结点存储指向关键字范围的子结点;
所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中
B+树:在B-树的基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现
,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中
B*树:在B+树的基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3
补充:B*树分配新结点的概率比B+树要低,空间使用率更高

 浙公网安备 33010602011771号
浙公网安备 33010602011771号