
2.keras实现-->深度学习用于文本和序列
1.将文本数据预处理为有用的数据表示
- 将文本分割成单词(token),并将每一个单词转换为一个向量
- 将文本分割成单字符(token),并将每一个字符转换为一个向量
- 提取单词或字符的n-gram(token),并将每个n-gram转换为一个向量。n-gram是多个连续单词或字符的集合
将向量与标记相关联的方法有:one-hot编码与标记嵌入(token embedding)
具体见https://www.cnblogs.com/nxf-rabbit75/p/9970320.html
2.使用循环神经网络
(1)simpleRNNsimpleRNN可以在两种不同的模式下运行,这两种模式由return_sequences这个构造函数参数来控制 |
|||
| 一种是返回每个时间步连续输出的完整序列, 其形状为(batch_size,timesteps,output_features); |
另一种是只返回每个输入序列的最终输出,其形状为(batch_size,output_features) | ||
# 例子1 from keras.models import Sequential from keras.layers import Embedding,SimpleRNN model = Sequential() model.add(Embedding(10000,32)) #(batch_size,output_features) model.add(SimpleRNN(32)) model.summary()
|
|
||

|
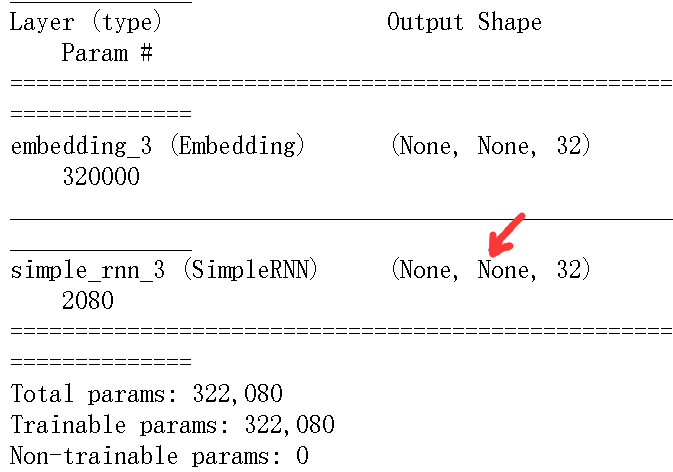
|
||
我们将这个模型应用IMDB电影评论分类问题
 #准备imdb数据 from keras.datasets import imdb from keras.preprocessing import sequence max_features = 10000# 作为特征的单词个数最多10000,多了不算 max_len = 500 # 在这么多单词之后截断文本 batch_size = 32 (input_train,y_train),(input_test,y_test) = imdb.load_data(num_words = max_features) print(len(input_train),'train sequences') print(len(input_test),'test sequences') input_train = sequence.pad_sequences(input_train,maxlen=max_len) input_test = sequence.pad_sequences(input_test,maxlen=max_len) print(input_train.shape) print(input_test.shape)
|
首先对数据进行预处理 25000 train sequences
25000 test sequences
(25000, 500)
(25000, 500)
|
#定义模型 from keras.models import Sequential from keras.layers import Embedding,Flatten,Dense model = Sequential() model.add(Embedding(max_features,32)) model.add(SimpleRNN(32)) model.add(Dense(1,activation='sigmoid')) model.summary() model.compile(loss='binary_crossentropy',optimizer='rmsprop',metrics=['acc']) history = model.fit(input_train,y_train, epochs = 10, batch_size = 128, validation_split = 0.2)
|

|
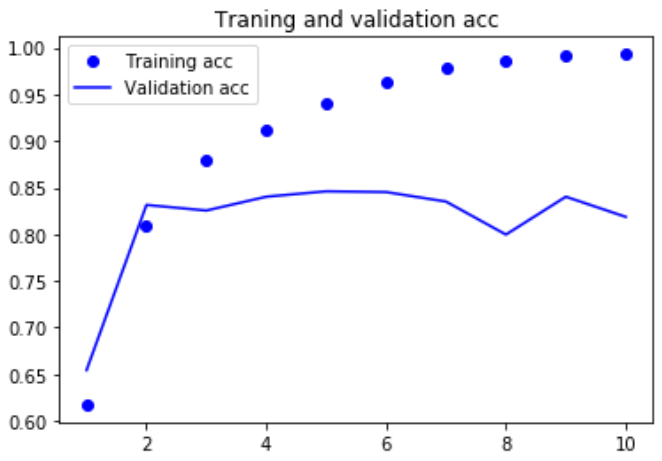
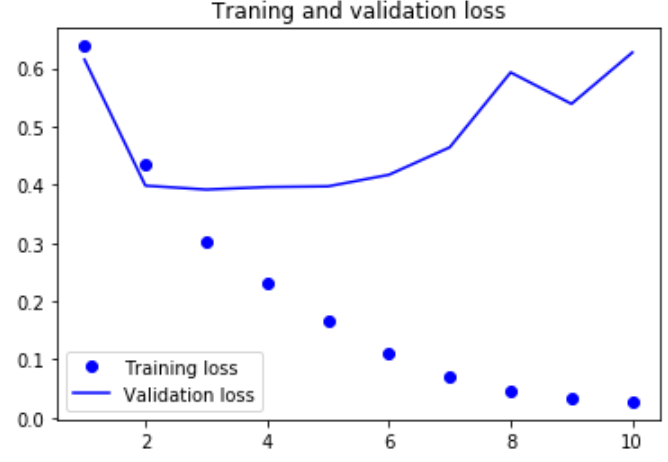
import matplotlib.pyplot as plt acc = history.history['acc'] loss = history.history['loss'] val_acc = history.history['val_acc'] val_loss = history.history['val_loss'] epochs = range(1,len(acc)+1) plt.plot(epochs,acc,'bo',label='Training acc') plt.plot(epochs,val_acc,'b',label='Validation acc') plt.title('Traning and validation acc') plt.legend() plt.figure() plt.plot(epochs,loss,'bo',label='Training loss') plt.plot(epochs,val_loss,'b',label='Validation loss') plt.title('Traning and validation loss') plt.legend() plt.show()
|
|
|
总结: 这个小型循环网络的表现并不好,问题的部分原因在于: 输入只考虑了前500个单词,而不是整个序列,因此RNN获得的信息比前面的基准模型更少。 另一部分原因在于,simpleRNN不擅长处理长序列,比如文本。 其他类型的循环层的表现要好得多,比如说LSTM层和GRU层 理论上来说,SimpleRNN应该能够记住许多时间步之前见过的信息,但实际上他是不可能学到这种长期以来的,原因在于梯度消失问题, 这一效应类似于在层数较多的非循环网络(即前馈网络),随着层数的增加,网络最终变得无法训练。 LSTM和GRU都是为了解决这个问题而设计的 |
|
(2)LSTM# keras实现LSTM的一个例子 from keras.layers import LSTM model = Sequential() model.add(Embedding(max_features,32)) model.add(LSTM(32)) model.add(Dense(1,activation='sigmoid')) model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc']) history = model.fit(input_train,y_train, epochs = 10, batch_size = 128, validation_split = 0.2) |
|
|
这次,验证精度达到了,比simpleRNN好多了,主要是因为LSTM受梯度消失问题的影响要小得多,这个结果也比第三章的全连接网络略好, 虽然使用的数据量比第三章少。此处在500个时间步之后将序列截断,而在第三章是读取整个序列 |
|
- 循环dropout (降低过拟合)
- 堆叠循环层 (提高网络的表示能力(代价是更高的计算负荷))
- 双向循环层 (将相同的信息以不同的方式呈现给循环网络,可以提高精度并缓解遗忘问题)
我们将使用一个天气时间序列数据集-->德国耶拿的马克思-普朗克生物地球化学研究所的气象站记录
温度预测问题数据集:每十分钟记录14个不同的量(比如气温、气压、湿度、风向等),原始数据可追溯到2003年。本例仅适用2009-2016年的数据, 这个数据集非常适合用来学习处理数值型时间序列我们将会用这个数据集来构建模型, 输入最近的一些数据(几天的数据点),可以预测24小时之后的气温。
|
|||
import os data_dir = 'jena_climate' fname = os.path.join(data_dir,'jena_climate_2009_2016.csv') f = open(fname) data = f.read()#所有行组成一个字符串,每行由\n隔开 f.close() lines = data.split('\n') header = lines[0].split(',') lines = lines[1:] print(header) #时间步+14个与天气有关的值 print(lines[0]) print(len(lines))#有420551行数据
|
日期+14个特征名称
一行的数据为:
|
||
import numpy as np float_data = np.zeros((len(lines),len(header)-1)) for i,line in enumerate(lines): values = [float(x) for x in line.split(',') [1:]] float_data[i,:] = values float_data[1,:]
|

|
||
|
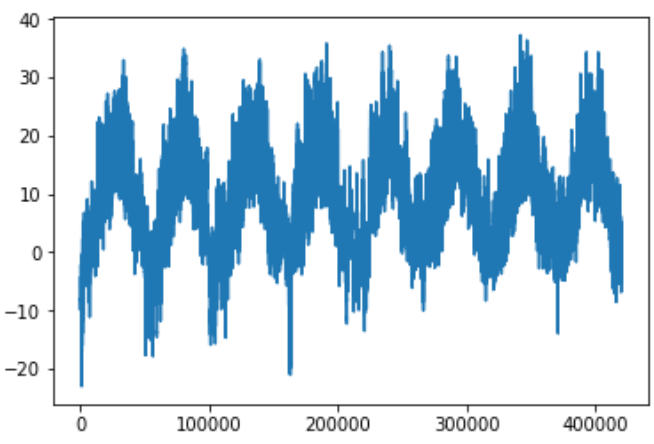
|
||
|
|
||
|
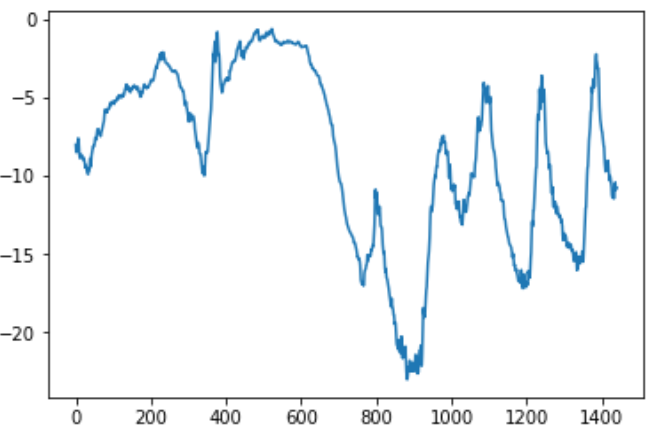
上面这张图,可以看到每天的周期性变化,尤其是最后4天特别明显。 如果想根据过去几个月的数据来预测下个月的平均温度,那么问题很简单, 因为数据具有可靠的年度周期性。 从这几天的数据来看,温度看起来更混乱一些。以天作为观察尺度,这个时间序列是可以预测的吗? |
|||
|
准备数据
lookback = 720:给定过去5天内的观测数据 steps = 6:每6个时间步采样一次数据 delay = 144:目标是未来24小时之后的数据 |
float_data
|
||
|
|||
|
|||
#准备训练生成器,验证生成器,测试生成器 lookback =1440 step = 6 delay = 144 batch_size = 128 train_gen = generator(float_data,lookback=lookback,delay=delay, min_index=0,max_index=200000,shuffle=True,batch_size=batch_size,step=step) val_gen = generator(float_data,lookback=lookback,delay=delay, min_index=200001,max_index=300000,shuffle=True,batch_size=batch_size,step=step) test_gen = generator(float_data,lookback=lookback,delay=delay, min_index=300001,max_index=None,shuffle=True,batch_size=batch_size,step=step) |
|||
#为了查看整个训练集,需要从train_gen中抽取多少次 train_steps = (200000-0-lookback) // batch_size #为了查看整个验证集,需要从val_gen中抽取多少次 val_steps = (300000-200001-lookback) // batch_size #为了查看整个测试集,需要从val_gen中抽取多少次 test_steps = (len(float_data)-300001-lookback) // batch_size print(train_steps) print(val_steps) print(test_steps) |
1551 769 930 |
||


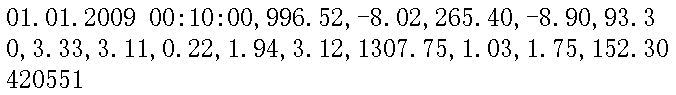

# 一种基于常识的、非机器学习的基准方法-->始终预测24小时后的温度等于现在的温度 def evaluate_naive_method(): batch_maes = [] for step in range (val_steps): samples, targets = next (val_gen) preds = samples[:, -1, 1] mae = np.mean (np.abs (preds - targets)) batch_maes.append (mae) evaluate_naive_method () # 将MAE转换成摄氏温度误差 std = float_data[:200000].std (axis=0) celsius_mae = 0.29 * std[1] # celsius_mae |
|
from keras.models import Sequential from keras import layers #对比1.全连接网络 model = Sequential() model.add(layers.Flatten(input_shape=(lookback//step,float_data.shape[-1]))) model.add(layers.Dense(32,activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='RMSprop',loss='mae') history = model.fit_generator( train_gen, steps_per_epoch=50, epochs=10, validation_data=val_gen, validation_steps=val_steps )
|
|
|
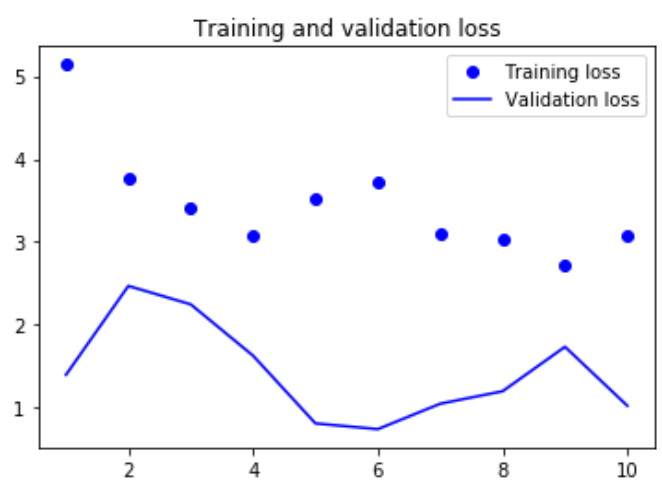
第一个全连接方法的效果并不好,但这并不意味机器学习不适用于这个问题,该方法首先将时间序列展平, 这从输入数据中删除了时间的概念。 数据本身是个序列,其中因果关系和顺序都很重要。 |
|
#对比2.循环网络GRU #训练并评估一个基于GRU的模型 from keras.models import Sequential from keras.layers import Dense,GRU model = Sequential() model.add(GRU(32,input_shape=(None,float_data.shape[-1]))) model.add(Dense(1)) model.compile(optimizer='rmsprop',loss='mae') history = model.fit_generator(train_gen, steps_per_epoch=50, epochs=5, validation_data = val_gen, validation_steps = val_steps) # loss: 0.3403 - val_loss: 0.3160
|

|
#使用dropout来降低过拟合 from keras.models import Sequential from keras.layers import Dense,GRU model = Sequential() model.add(GRU(32,dropout=0.2,recurrent_dropout=0.2,input_shape=(None,float_data.shape[-1]))) model.add(Dense(1)) model.compile(optimizer='RMSprop',loss='mae') history = model.fit_generator(train_gen, steps_per_epoch=50, epochs=5, validation_data = val_gen, validation_steps = val_steps)
|

|
模型不再过拟合,但似乎遇到了性能瓶颈,所以我们应该考虑增加网络容量。增加网络容量直到过拟合变成主要的障碍。 只要过拟合不是太严重,那么很可能是容量不足的问题 |
|
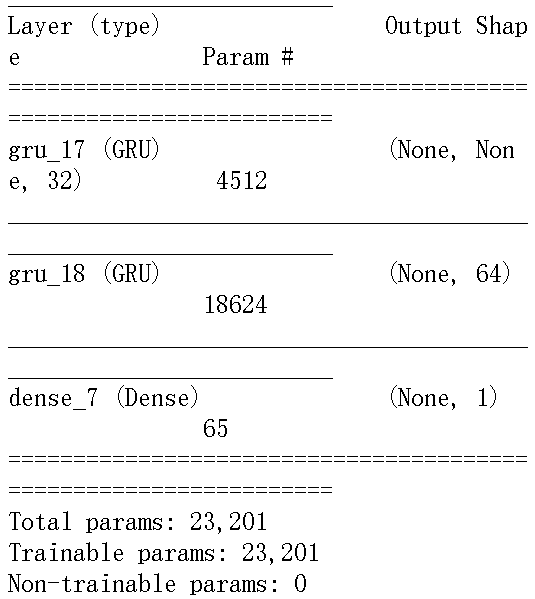
#对比3.循环层堆叠 #训练并评估一个使用dropout正则化的堆叠GRU模型 #数据集:温度 from keras.models import Sequential from keras.layers import Dense,GRU model = Sequential() model.add(GRU(32,dropout=0.1,recurrent_dropout=0.5,input_shape=(None,float_data.shape[-1]),return_sequences=True)) # return_sequences=True,在keras中逐个堆叠循环层,所有中间层都应该返回完整的输出序列, # 而不是只返回最后一个时间步的输出 model.add(GRU(64,activation='relu',dropout=0.1,recurrent_dropout=0.5)) # 但是最后一个LSTM层return_sequences通常为false model.add(Dense(1)) model.summary() model.compile(optimizer='rmsprop',loss='mae') history = model.fit_generator(train_gen, steps_per_epoch=50, epochs=5, validation_data = val_gen, validation_steps = val_steps)
|
|

|
结果如上图所示,可以看出,添加一层的确对结果有所改进,但并不显著,我们可以得到两个结论:1.因为过拟合仍然不是很严重,所以可以放心的增大每层的大小, 以进一步改进验证损失,但这么做的计算成本很高 2.添加一层厚模型并没有显著改进,所以你可能发现,提高网络能力 的回报在逐渐减小 |
#对比4:逆序序列评估LSTM
|

|
|
总结:模型性能与正序LSTM几乎相同,这证实了一个假设,虽然单词顺序对理解语言很重要,但使用哪种顺序不重要。 双向RNN正是利用这个想法来提高正序RNN的性能,他从两个方向查看数据,从而得到更加丰富的表示,并捕捉到仅使用正序RNN时可能忽略的一些模式 |
|
(3)Bidirectional RNN#训练并评估一个双向LSTM #数据集imdb model = Sequential() model.add(layers.Embedding(max_features,32)) model.add(layers.Bidirectional(layers.LSTM(32))) model.add(layers.Dense(1,activation='sigmoid')) model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc']) history = model.fit(x_train,y_train, epochs = 5, batch_size = 128, validation_split = 0.2) |
|
#训练一个双向GRU #数据集 温度 model = Sequential() model.add(layers.Bidirectional(layers.GRU(32),input_shape=(None,float_data.shape[-1]))) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop',loss='mae') history = model.fit_generator(train_gen, epochs = 5, steps_per_epoch = 50, validation_data = val_gen, validation_steps = val_steps)
|
|
|
更多尝试
|
|
3.使用一维卷积神经网络处理序列
## 用卷积神经网络处理序列 ## 实现一维卷积神经网络 #准备imdb数据 from keras.datasets import imdb from keras.preprocessing import sequence from keras import layers from keras.models import Sequential max_features = 10000 max_len = 500 (x_train,y_train),(x_test,y_test) = imdb.load_data(num_words = max_features) print('x_train序列长度',len(x_train)) print('x_test序列长度',len(x_test)) x_train = sequence.pad_sequences(x_train,maxlen = max_len) x_test = sequence.pad_sequences(x_test,maxlen = max_len) print('x_train shape',x_train.shape) print('x_test shape',x_test.shape) |
x_train序列长度 25000
x_test序列长度 25000
x_train shape (25000, 500)
x_test shape (25000, 500)
|
#在imdb数据上训练并评估一个简单的一维卷积神经网络 from keras.models import Sequential from keras import layers from keras.optimizers import RMSprop model = Sequential() model.add(layers.Embedding(max_features,128,input_length=max_len)) model.add(layers.Conv1D(32,7,activation='relu')) model.add(layers.MaxPooling1D(5)) model.add(layers.Conv1D(32,7,activation='relu')) model.add(layers.GlobalMaxPooling1D()) #GlobalMaxPooling1D和GlobalMaxPool1D有啥关系? model.add(layers.Dense(1)) model.summary() model.compile(optimizer=RMSprop(lr=1e-4), loss = 'binary_crossentropy', metrics = ['acc']) history = model.fit(x_train,y_train, epochs = 2, batch_size = 128, validation_split = 0.2) |
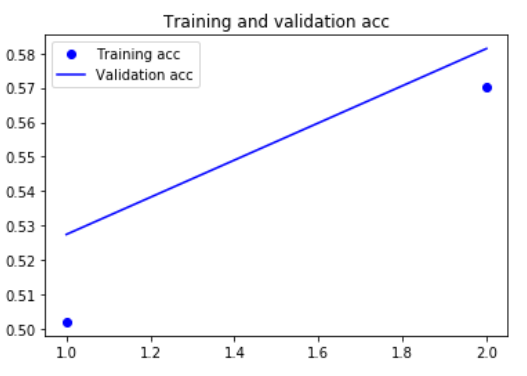
|
|
总结: 用一维卷积神经网络验证精度略低于LSTM,但在CPU和GPU上的运行速度都要更快 |
|
#在耶拿数据上训练并评估一个简单的一维卷积神经网络 from keras.models import Sequential from keras import layers from keras.optimizers import RMSprop model = Sequential() model.add(layers.Conv1D(32,5,activation='relu',input_shape=(None,float_data.shape[-1]))) model.add(layers.MaxPooling1D(3)) model.add(layers.Conv1D(32,5,activation='relu')) model.add(layers.MaxPooling1D(3)) model.add(layers.Conv1D(32,5,activation='relu')) model.add(layers.GlobalMaxPooling1D()) #GlobalMaxPooling1D和GlobalMaxPool1D有啥关系? model.add(layers.Dense(1)) model.summary() model.compile(optimizer=RMSprop(),loss = 'mae') history = model.fit_generator(train_gen, epochs = 5, steps_per_epoch = 50, validation_data = val_gen, validation_steps = val_steps) |
验证MAE停留在0.4-0.5,使用小型卷积神经网络甚至无法击败基于尝试的基准方法。同样,这是因为卷积神经网络在输入时间序列的所有位置寻找模式,它并不知道所看到某个模式的时间位置(距开始多长时间,距结束多长时间等)。对于这个具体的预测问题,对最新数据点的解释与对较早数据点的解释应该并不相同,所以卷积神经网络无法得到有意义的结果。
卷积神经网络对IMDB数据来说并不是问题,因为对于正面情绪或负面情绪相关联的关键词模式,无论出现在输入句子中的什么位置,它所包含的信息量是一样的 |
|
要想结合卷积神经网络的速度与轻量 与 RNN的顺序敏感性,一种方法是在RNN前面使用一维神经网络作为预处理步骤。 对于那些非常长,以至于RNN无法处理的序列,这种方法尤其有用。卷积神经网络可以将长的输入序列转换为高级特征组成的更短序列(下采样) 然后,提取的特征组成的这些序列成为网络中RNN的输入。 |
|
|
在RNN前面使用一维卷积神经网络作为预处理步骤 长序列-->通过一维CNN-->更短的序列(CNN特征)->通过RNN-->输出 这里将step减半,得到时间序列的长度变为之前的两倍,温度数据的采样频率为每30分钟一个数据点 |
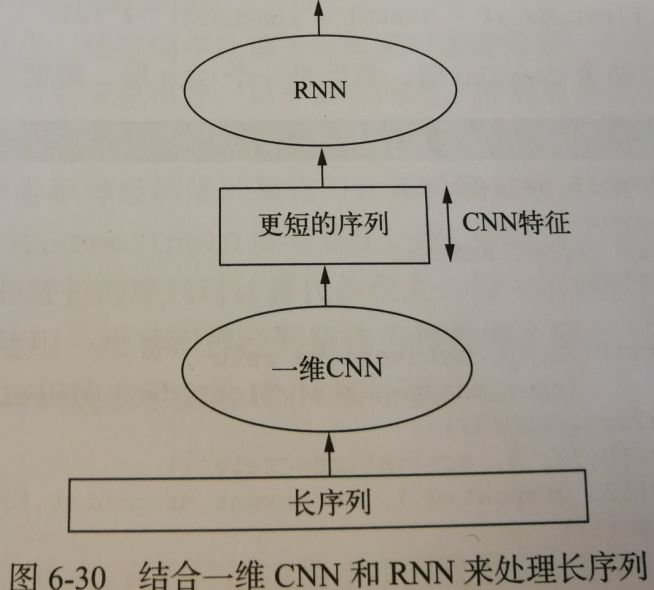
|
#准备训练生成器,验证生成器,测试生成器 lookback =720 step = 3 delay = 144 batch_size = 128 train_gen = generator(float_data,lookback=lookback,delay=delay, min_index=0,max_index=200000,shuffle=True,batch_size=batch_size,step=step) val_gen = generator(float_data,lookback=lookback,delay=delay, min_index=200001,max_index=300000,shuffle=True,batch_size=batch_size,step=step) test_gen = generator(float_data,lookback=lookback,delay=delay, min_index=300001,max_index=None,shuffle=True,batch_size=batch_size,step=step) #为了查看整个训练集,需要从train_gen中抽取多少次 train_steps = (200000-0-lookback) // batch_size #为了查看整个验证集,需要从val_gen中抽取多少次 val_steps = (300000-200001-lookback) // batch_size #为了查看整个测试集,需要从val_gen中抽取多少次 test_steps = (len(float_data)-300001-lookback) // batch_size print(train_steps) print(val_steps) print(test_steps) |
1556 775 936 |
#结合一维CNN和GRU来处理长序列 from keras.models import Sequential from keras import layers from keras.optimizers import RMSprop model = Sequential() model.add(layers.Conv1D(32,5,activation='relu',input_shape=(None,float_data.shape[-1]))) model.add(layers.MaxPooling1D(3)) model.add(layers.Conv1D(32,5,activation='relu')) model.add(layers.GRU(32,dropout=0.1,recurrent_dropout=0.5)) model.add(layers.Dense(1)) model.summary() model.compile(optimizer=RMSprop(),loss = 'mae') history = model.fit_generator(train_gen, epochs = 5, steps_per_epoch = 50, validation_data = val_gen, validation_steps = val_steps) |

从验证损失来看,这种架构的效果不如只用正则化GPU,但速度要快很多,它查看了两倍的数据量,在本例中可能不是非常有用,但对于其他数据集可能非常重要 |



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现