
2.keras实现-->字符级或单词级的one-hot编码 VS 词嵌入
1. one-hot编码
 # 字符集的one-hot编码 import string samples = ['zzh is a pig','he loves himself very much','pig pig han'] characters = string.printable token_index = dict(zip(range(1,len(characters)+1),characters)) max_length =20 results = np.zeros((len(samples),max_length,max(token_index.keys()) + 1)) for i,sample in enumerate(sample): for j,character in enumerate(sample): index = token_index.get(character) results[i,j,index] = 1 results characters= '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVW XYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c' |

|
# keras实现单词级的one-hot编码 from keras.preprocessing.text import Tokenizer samples = ['zzh is a pig','he loves himself very much','pig pig han'] tokenizer = Tokenizer(num_words = 100) #创建一个分词器(tokenizer),设置为只考虑前1000个最常见的单词 tokenizer.fit_on_texts(samples)#构建单词索引 sequences = tokenizer.texts_to_sequences(samples) one_hot_results = tokenizer.texts_to_matrix(samples,mode='binary') # one_hot_results.shape --> (3, 100) word_index = tokenizer.word_index print('发现%s个unique标记',len(word_index))
|
sequences = [[2, 3, 4, 1], 发现10个unique标记 {'pig': 1, 'zzh': 2, 'is': 3, 'a': 4, 'he': 5,
|
one-hot 编码的一种办法是 one-hot散列技巧(one-hot hashing trick)如果词表中唯一标记的数量太大而无法直接处理,就可以使用这种技巧。这种方法没有为每个单词显示的分配一个索引并将这些索引保存在一个字典中,而是将单词散列编码为固定长度的向量,通常用一个非常简单的散列函数来实现。 优点:节省内存并允许数据的在线编码(读取完所有数据之前,你就可以立刻生成标记向量) 缺点:可能会出现散列冲突 如果散列空间的维度远大于需要散列的唯一标记的个数,散列冲突的可能性会减小 |
|
import numpy as np samples = ['the cat sat on the mat the cat sat on the mat the cat sat on the mat','the dog ate my homowork'] dimensionality = 1000#将单词保存为1000维的向量 max_length = 10 results = np.zeros((len(samples),max_length,dimensionality)) for i,sample in enumerate(samples): for j,word in list(enumerate(sample.split()))[:max_length]: index = abs(hash(word)) % dimensionality results[i,j,index] = 1
|

|
2. 词嵌入
获取词嵌入的两种方法:
- 在完成主任务的同时学习词嵌入。在这种情况下,一开始是随机的词向量,然后对这些词向量进行学习,其学习方式与学习神经网络的权重相同。
- 在不同于待解决的机器学习任务上预计算好词嵌入,然后将其加载到模型中。这些词嵌入叫作预训练词嵌入
实验数据:imdb电影评论,我们添加了以下限制,将训练数据限定为200个样本(打乱顺序)。

| (1)使用embedding层学习词嵌入 | |
# 处理imdb原始数据的标签 # _*_ coding:utf-8 _*_ import os imdb_dir = 'imdb' train_dir = os.path.join(imdb_dir,'train') labels = [] texts = [] for label_type in ['neg','pos']: dir_name = os.path.join(train_dir,label_type) for fname in os.listdir(dir_name): if fname[-4:] == '.txt': f = open(os.path.join(dir_name,fname),encoding='UTF-8') texts.append(f.read()) f.close() if label_type == 'neg': labels.append(0) else: labels.append(1)
|
len(texts)=25000 len(labels)=25000 |
# 对imdb原始数据的文本进行分词 from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences max_len = 100 #每句话最大长度不超过100个单词 training_samples = 200 validation_samples = 10000 max_words = 10000 #只考虑数据集中前10000个最常见的单词 tokenizer = Tokenizer(num_words=max_len) tokenizer.fit_on_texts(texts) sequences = tokenizer.texts_to_sequences(texts) len(sequences)
|
sequence[0]
|
|
word_index = tokenizer.word_index |
#88592个unique单词 word_index
|
|
data = pad_sequences(sequences,maxlen=max_len) |
data.shape = (25000,100) data[0]
|
|
labels = np.asarray(labels) |
#asarray会跟着原labels的改变,算是浅拷贝吧, |
|
indices = np.arange(data.shape[0]) np.random.shuffle(indices) |
indices array([ 2501, 4853, 2109, ..., 2357, 22166, 12397]) |
#将data,label打乱顺序
|
x_val.shape,y_val.shape (10000, 100) (10000,) |
#2014年英文维基百科的预计算嵌入:Glove词嵌入(包含400000个单词) glove_dir = 'glove.6B' embeddings_index = {} f = open(os.path.join(glove_dir,'glove.6B.100d.txt'),encoding='utf8') for line in f: values = line.split() word = values[0] coefs = np.asarray(values[1:],dtype='float32') embeddings_index[word] = coefs f.close()
|
len(embeddings_index) 400000 f.readline() #'the -0.038194 -0.24487 ...' |
#准备glove词嵌入矩阵 embedding_dim = 100 # 每个单词都有编号,根据编号得到对应的矩阵 embedding_matrix = np.zeros((max_words,embedding_dim)) for word,i in word_index.items(): # print(word,i)--> the 1 if i < max_words: embedding_vector = embeddings_index.get(word) if embedding_vector is not None: embedding_matrix[i] = embedding_vector # print(embedding_matrix[0])
|
把数据集里面的单词在glove中找到对应的词向量,组成embedding_matrix, 若在glove中不存在,那就为0向量 |
#定义模型 from keras.models import Sequential from keras.layers import Embedding,Flatten,Dense model = Sequential() model.add(Embedding(max_words,embedding_dim,input_length=max_len)) model.add(Flatten()) model.add(Dense(32,activation='relu')) model.add(Dense(1,activation='sigmoid')) model.summary() #将预训练的词嵌入加载到embedding层中, model.layers[0].set_weights([embedding_matrix]) #embedding_matrix ==>(max_words,embedding_dim) model.layers[0].trainable = False
|

|
model.compile(loss='binary_crossentropy',optimizer='rmsprop',metrics=['acc']) history = model.fit(x_train,y_train, epochs = 10, batch_size = 32, validation_data = (x_val,y_val)) model.save_weights('pre_trained_glove_model.h5')
|
|
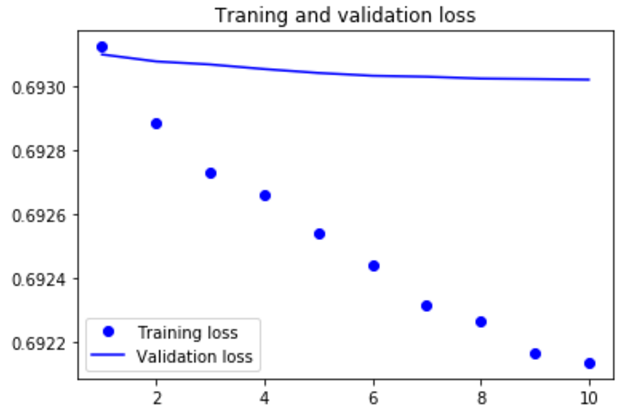
import matplotlib.pyplot as plt acc = history.history['acc'] loss = history.history['loss'] val_acc = history.history['val_acc'] val_loss = history.history['val_loss'] epochs = range(1,len(acc)+1) plt.plot(epochs,acc,'bo',label='Training acc') plt.plot(epochs,val_acc,'b',label='Validation acc') plt.title('Traning and validation acc') plt.legend() plt.figure() plt.plot(epochs,loss,'bo',label='Training loss') plt.plot(epochs,val_loss,'b',label='Validation loss') plt.title('Traning and validation loss') plt.legend() plt.show()
|
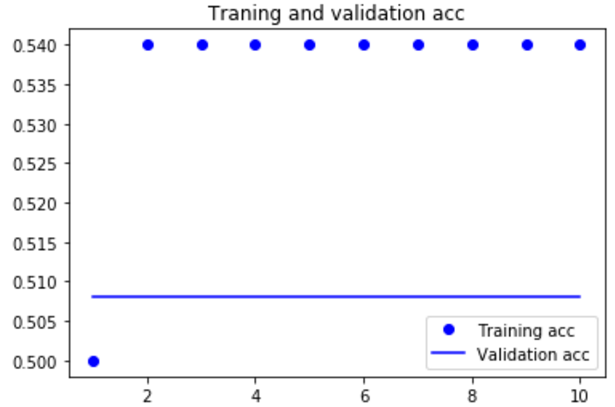
|
模型很快就开始过拟合,考虑到训练样本很少,这也很情有可原的 |

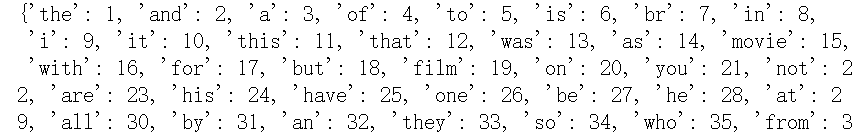

| (2)下面在不使用预训练词嵌入的情况下,训练相同的模型 | |
#定义模型 from keras.models import Sequential from keras.layers import Embedding,Flatten,Dense model = Sequential() model.add(Embedding(max_words,embedding_dim,input_length=max_len)) model.add(Flatten()) model.add(Dense(32,activation='relu')) model.add(Dense(1,activation='sigmoid')) model.summary() model.compile(loss='binary_crossentropy',optimizer='rmsprop',metrics=['acc']) history = model.fit(x_train,y_train, epochs = 10, batch_size = 32, validation_data = (x_val,y_val))
|

|
import matplotlib.pyplot as plt acc = history.history['acc'] loss = history.history['loss'] val_acc = history.history['val_acc'] val_loss = history.history['val_loss'] epochs = range(1,len(acc)+1) plt.plot(epochs,acc,'bo',label='Training acc') plt.plot(epochs,val_acc,'b',label='Validation acc') plt.title('Traning and validation acc') plt.legend() plt.figure() plt.plot(epochs,loss,'bo',label='Training loss') plt.plot(epochs,val_loss,'b',label='Validation loss') plt.title('Traning and validation loss') plt.legend() plt.show()
|
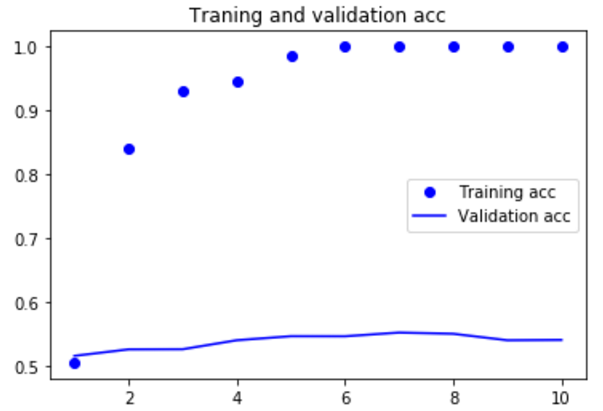
|
#在测试集上评估模型 test_dir = os.path.join(imdb_dir,'test') labels = [] texts = [] for label_type in ['neg','pos']: dir_name = os.path.join(test_dir,label_type) for fname in os.listdir(dir_name): if fname[-4:] == '.txt': f = open(os.path.join(dir_name,fname),encoding='UTF-8') texts.append(f.read()) f.close() if label_type == 'neg': labels.append(0) else: labels.append(1) sequence = tokenizer.texts_to_sequences(texts) x_test = pad_sequences(sequences,maxlen = max_len) y_test = np.asarray(labels)
|
|
|
model.load_weights('pre_trained_glove_model.h5') model.evaluate(x=x_test,y=y_test) |
|
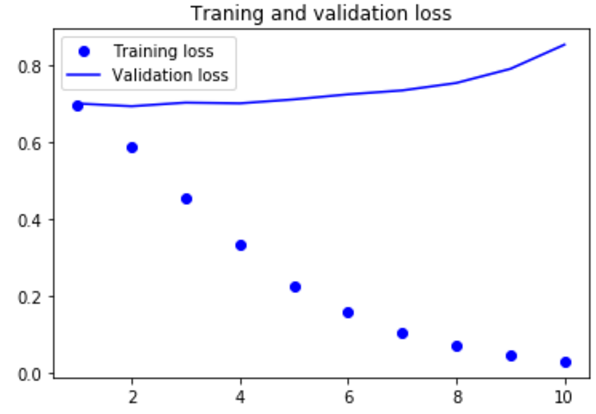
如果增加训练集样本的数量,可能使用词嵌入得到的效果会好很多。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现