
【序列模型】第三课--序列模型和注意力机制
1.基础模型basic model
以翻译为例,将如下一句法文翻译成英文,输入是法文的每个单词,输出是英文的每个单词,分别用表示:
如何构建一个模型,使得输入法文序列的词,输出英文序列的词呢?接下去要介绍的知识与思想主要来自于这两篇论文:
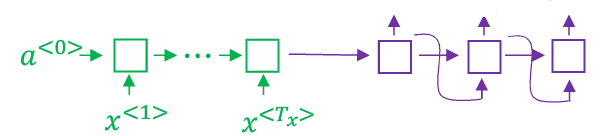
(1)首先建立一个网络,称之为encoder network,是一个RNN结构。RNN结构中的单元可以是GRU,也可以是LSTM。每个时刻只向该网络输入一个法语单词;当接收完所有单词之后,这个人NN网络会输出一个向量来代表这个输入序列。
(2)接着建立一个网络,称之为decoder network。每个时刻输出一个英文单词,直到它输出句子的结尾标记,这个解码网络的工作就结束了。
以上两步如下图所示:
事实证明,当训练的样本足够多时,这个模型确实在翻译上有非常优秀的表现。
有一个与此类似的结构被用来做图像描述,即输入一张图片,输出一句对图像描述的句子。
首先将图片经过一个预训练的卷积神经网络(比如Alexnet),去掉最后一层的softmax层,将前一层的结果(4096维的向量)作为encoder network获取到的编码后的向量,输入给decoder network。与翻译模型一样,decoder network在每一个时刻输出一个词,所有词组合起来就是句对图像的描述的句子。比如输入的句子将会是:a cat sitting on a chair
结构如下:
2.选择最可能的句子
通过encoder-decoder的RNN,会将输入的法语句子翻译成英语句子,decoder输出单词的过程与语言模型生成序列一样,但是语言模型生成的序列是随机的,而机器翻译中生成的序列需要依据输入的语言,给出最好的翻译,是有条件的,因此称之为条件语言模型。
但是对同一句法语的翻译可能会有多个分布,机器翻译追求的是精准,因此并不是随机取样,而是要选出最好的最可能的翻译句子,即使得一下的条件概率最大化:
其中,x是输入的序列,y是输出的序列。
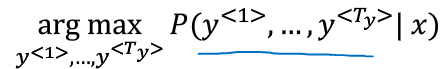
要选出最优的结果,你可能会想到“贪心搜索(greedy search)”,什么是贪心搜索呢?
首先会去选出最优的第一个词,在选出了第一个词的基础之上,再选出最优的第二个词,以此类推。但是贪心搜索在机器翻译中并不合适,我们要的是一词性输出整体最优的句子,使得整体的概率最大化。比如下面两个句子,显然第一个币第二个翻译得更好,因为第一个更简洁:

但是,若按照贪心算法,当选择好前两个词jane is 之后根据贪心算法,第三个词会是going最优,因此就会给出第二个句子,但是整个句子的条件概率并没有最大化。
贪心搜索的另一个缺点是计算量大,假设有10000个词,要生成10个词的句子,那么就是去计算10000的10次方。
因此可以使用一种近似的搜索算法,叫做beam search algrithm,下一节中介绍。
3.集束搜索beam search
(1)第一步,选出第一个词。与上面的贪心搜索不同之处,首先在decoder端的第一个输出,是在所有词库中选择出概率最大的3个词做为起始词。即最大。比如选出了如下B个词(B是认为设定的,比如3):
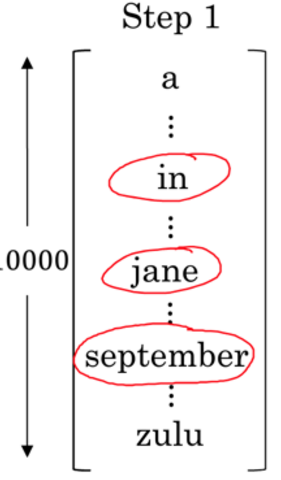
(2)第二步,针对每个起始词,都在decoder端的第二个时刻输出一个所有词库里的最优词,使该词与第一个词的联合条件概率最大,即最大,该概率可以如下计算得到:
比如第一个词为”in”时第二最好的词是september;
第一个词为”jane”时第二最好的词是is;
第一个词为”september”时第二最好的词是XXX;
于是总共需要计算3*10000词,然后对这第二轮的30000个词进行评估选出概率最大的3个,这3个词不一定是要分别来自3个decoder输出,可以来自同一个。比如概率最大的是in–>september,第二大是jane–>is;第三大是jane–>visit,以september开头的并没有次入选。于是beam search会将这三组词保存在内存中。
于是原来有3种起始词,现在只剩2种了,棒极了。
(3)第三步,继续根据第二步生成3种情况,寻找联合条件概率最好的第三个词。
也是同样的套路,分别有3个RNN与之对应,每次寻找一个词,但获取出最有可能的3组,直到最后遇到句子的终止词,选出最优的一个句子
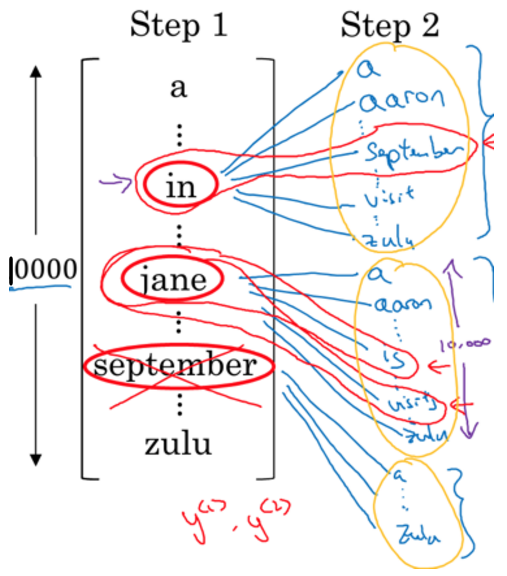
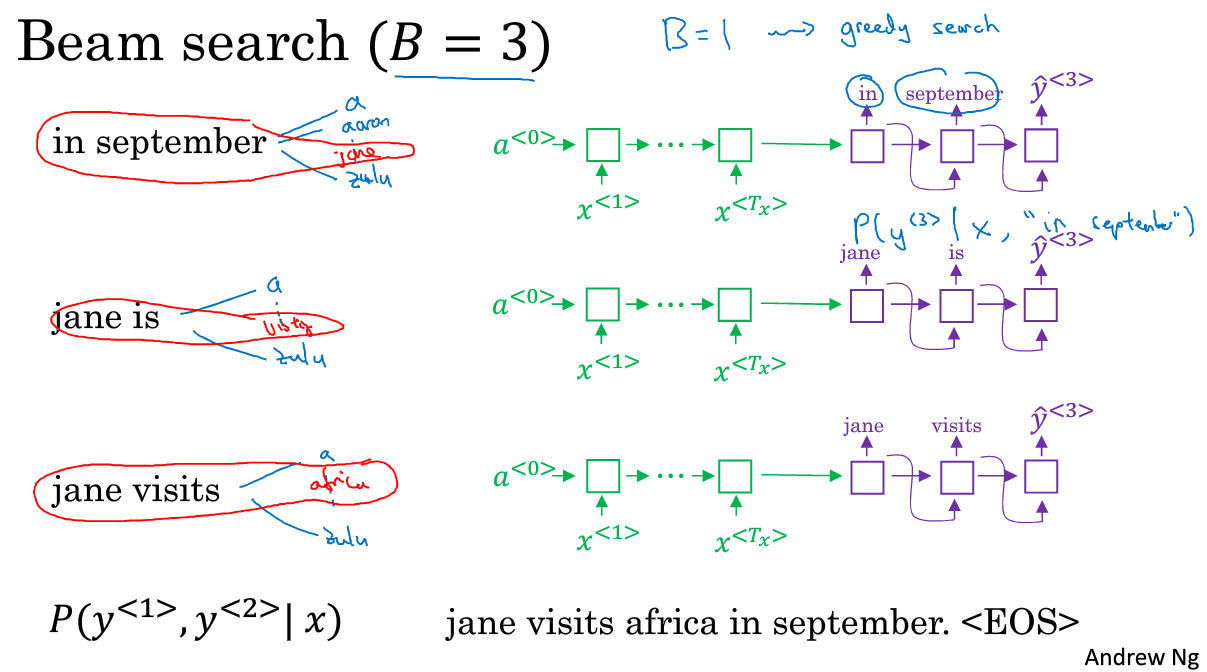
注意,若把B=1,则等同于贪婪搜索。但将B设置为>1,则往往会找到比贪婪算法更优的结果。
4.改进beam search
4.1长度归一化
长度归一化是对beam search对小优化。
上文介绍了beam search就是对以下概率对最大化:
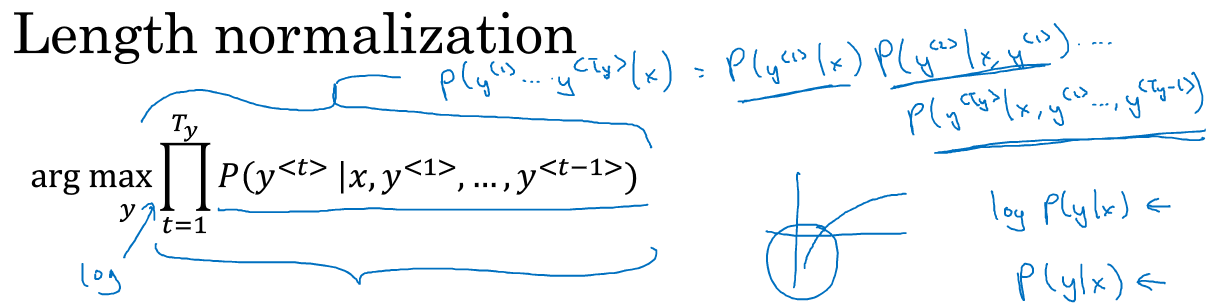
以上公式的乘积其实就等于。但酱紫计算有很大缺点,因为每一项p都是小于1的,假设这个要预测的序列很长,那么就会有很多P相乘,会得到很小很小的数字,导致电脑的浮点不能精确得储存。
因此,实际中会将上述乘积形式的公式做调整,变成log形式求和的模式:
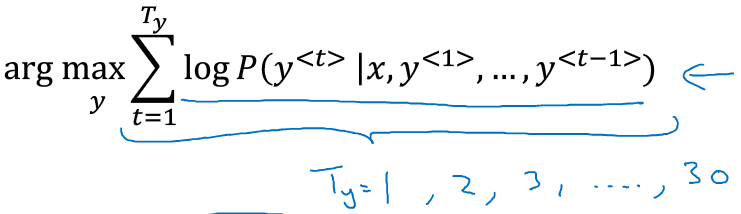
但这还有一个缺点,当序列很长的时候,每一项的概率值很小,那么log之后就为负,所有log项相加就会越来越负,使得模型更倾向于输出较短的句子。
因此,又将公式做调整,不去求log和的最大值,而是去求log项的均值:
是句子的长度,即用长度做归一化。
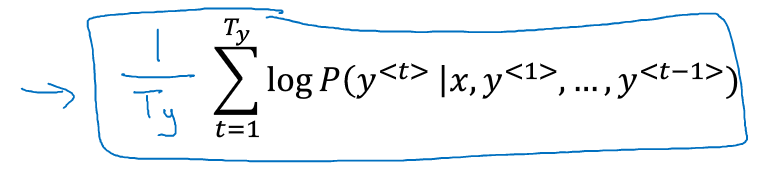
为了使其更柔和,往往会在上放一个指数系数:
当时等价于用序列长度去归一化,当时就相当于完全没有归一化,而则是在归一化与不归一化之间寻找一个合适的位置。a是一个超参数,需要在实验中调整大小来获得最好的结果。
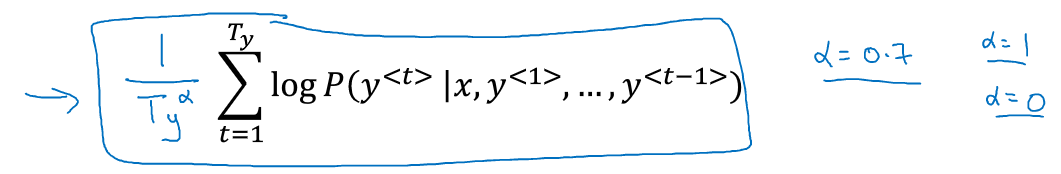
4.2 其他
4.2.1 如何选择B
B越大,你考虑的范围就越大,找到的句子可能越好,但是计算量也越大。
在大部分企业应用中,一般会使用B=10左右,设为100已经很大了;但是在科研中,往往为了得到最最最优秀的结果发论文,会设置B=1000或者3000
5.beam search的误差分析
beam search是一种近似搜索算法,也被称做启发式搜索算法。它不总是输出可能性最大的句子,它只会根据认为设定的B,去选取前B种可能。那么如果beam search 算法出现错误怎么办呢?下面介绍下误差分析与beam search算法是如何互相起作用,使我们发现到底是beam search算法出现了错误还是RNN模型出现了错误。
将这句法语:
翻译成英语应该是:
但是模型通过训练后给出的翻译是:
啊!不对不对,模型翻译错了,这个时候就要去找原因了,到底是beam search处理不当导致的错误,还是说RNN本身有与训练急太少等原因导致的错误呢?
这个时候我们会想到,无论是谁的错,反正我就增大B,或者增多训练样本就行。但是就算这样也不一定能得到你想要的结果。

好了,现在我们来看看到底什么情况下该用什么办法。
回顾翻译模型RNN的结构:
分别计算人工翻译对的句子(表示)和翻译错的句子(表示)的条件概率,即比较与的大小,从而来判断错误的预测应该归咎于RNN还是beam search。
(1)若 > ,则说明RNN并没有错,是beam search的错
(1)若 <= ,则说明beam search并没有错,是RNN的错
对所有预测出错的句子都进行如上计算,并统计出有多少比例是归咎与beam search,有多少比例是归咎于RNN。

6.Bleu(bilingual evaluation understudy)
从一种语言翻译成另一种语言,自然没有完全的一个标准答案,翻译模型有时可能会输出多个都很正确的结果,那么此时要如何评估一个机器翻译系统呢?通常,会使用bleu score来评估。
法语:
可以翻译成:
也可以翻译成:
上面两句人工翻译都是准确的,
此时对于机器翻译给出的句子,会给每个句子都计算一个Bleu得分,来进行比较。评估的依据是如果翻译的句子离人工翻译的结果越接近则Bleu score应越高。
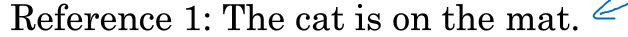
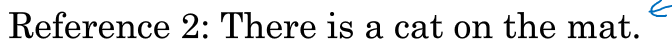
6.1 对单个单词进行评估
假设机器给出的翻译是:
嗯,这简直是个极差的翻译,现在我们来评估它的precision
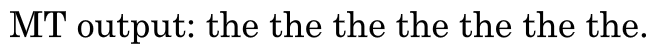
假设机器翻译的句子中的单词出现在了任意一句人工翻译句子中,则得1分。那么由于the出现在了人工翻译中,于是机器翻译句子总共7个单词,出现在人工翻译中的单词有7个,y.这显然不符合常理,因为给这个句子打0分都不足为过。
于是,做了改进,分子的上限是该单词在所有人工翻译句子中出现次数的最大值,the在reference1中存现2词,在reference2中出现了1词,于是上限是2,因此modified precision=2/7。
6.2 对二元词组进行评估
除了对单个词计算precision还可以对二元词组(即相邻的两个单词)计算precision
仍然是上面这个例子,这一次模型给出的翻译稍微好一丢丢了:
获取这个句子出现的所有二元词组,并分别计算每个词组出现的次数,同时计算这些词组在人工翻译句子中出现的最大次数(分别是以下3列表示):
将第三列的和除以第二列的和,得到的分值就是基于二元组的分值:4/6
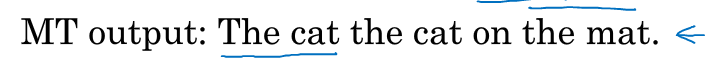

6.3 公式化Bleu的计算
将上面的过程用公式来表示一下。
一元评估:
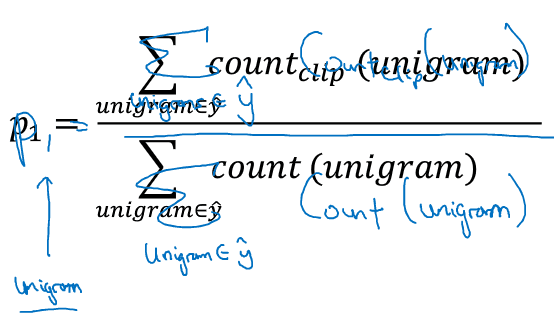
n元评估:
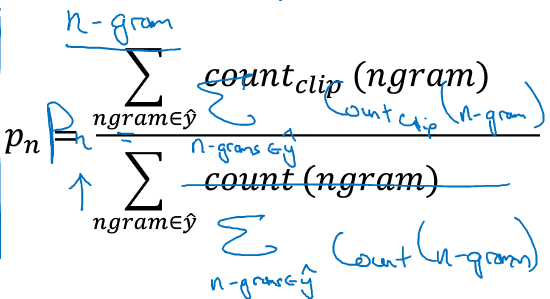
可见,如果机器翻译的句子和任何一句人工给出的翻译一模一样,那么以上得分将都为1
6.4 Bleu details
上面都在讲precision,那么说好的Bleu score呢?
根据以上的precision来构造最终的blue score。
用Pn表示Bleu score on n-grams only.分别计算处机器翻译的句子的P1,P2,P3,P4;然后求均值得到平均的Bleu score.
但这还不算最终的Bleu score,需要再给均值项上乘以一个惩罚因子BP(brevity penalty),顾名思义,即给较短的句子给予惩罚:

这个BP的原理是,如果翻译的句子越短,那么越有可能具备较高的bleu score,但是越短的句子并不是越好,较高的bleu score会误导我们的选择,因此需要给短句一个惩罚,使它的bleu score均值乘以一个0-1之间的系数。
7.注意力模型直观理解
7.1为什么要用注意力模型
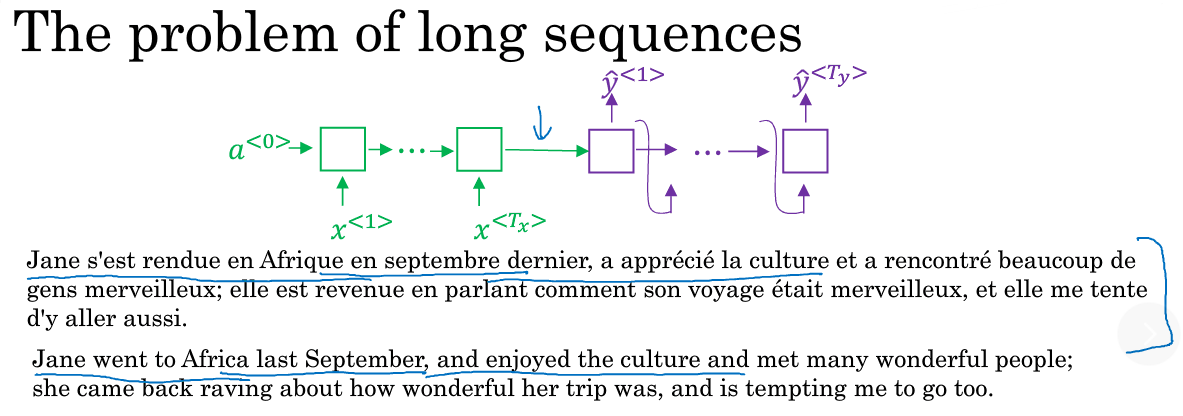
至此,我们讲到的翻译案例都是一句很短的话,使用单纯到encoder-decoder RNN可以取得较高到Bleu。
但是当翻译一段很长的句子到时候,比如:
就有点吃力了,因为encoder阶段要记住整句输入再传递给decoder进行翻译。就像人一样,在翻译一个长句时,往往无法全部读完并记住法语,再一词性翻译成英语,而是读一部分会事先翻一部分,等所有都读完翻完,在纵观整个句子调整与组合出正确的全文翻译。那么RNN要在长句中取得与短句同样好的表现,也需要这样一个机制,于是就需要“注意力机制”来帮忙实现。
7.2 直观理解
注意力机制虽然源于机器翻译,但也广泛推广到了其他领域。
为了讲解方便,使用回这个短句来做演示:
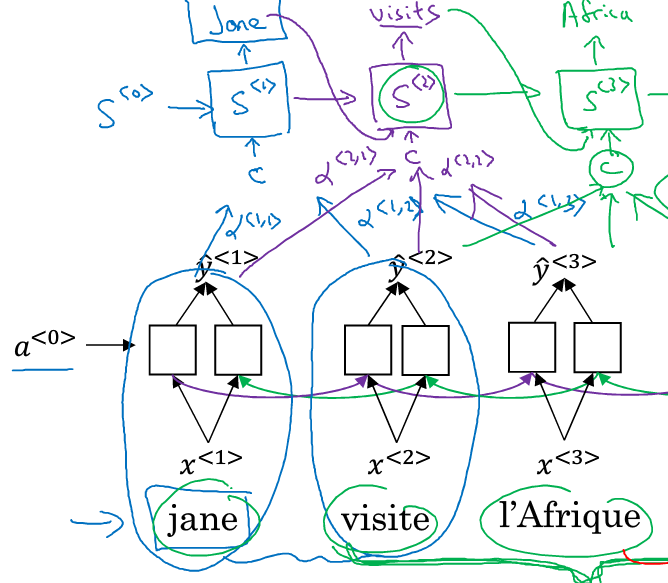
这里我们使用一个双向的RNN,每一个时刻的输入是一个法语单词,属于encoder端
decoder端是另一个RNN,输入记为,第一个时刻的输出应该是jane,为了使这个输出更准确,需要去回看一下输入的第一个单词或者与第一个单词相邻的单词是啥。这个回看的过程就是注意力的过程,用表示第一个输出需要给第一个输入多少注意力,翻译的过程不是词的一对一,因此可能第二个输入也会影响到第一个输出,因此用表示预测第一个词需要给多少注意力给第二个输入的单词。以此类推,也会有.所有的注意力信息用c表示,输入给
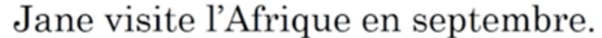
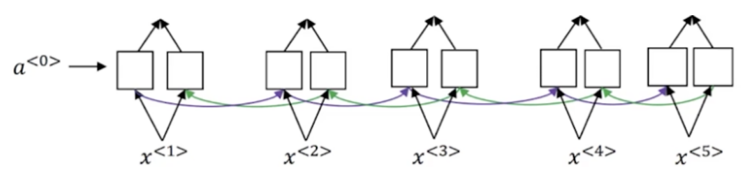
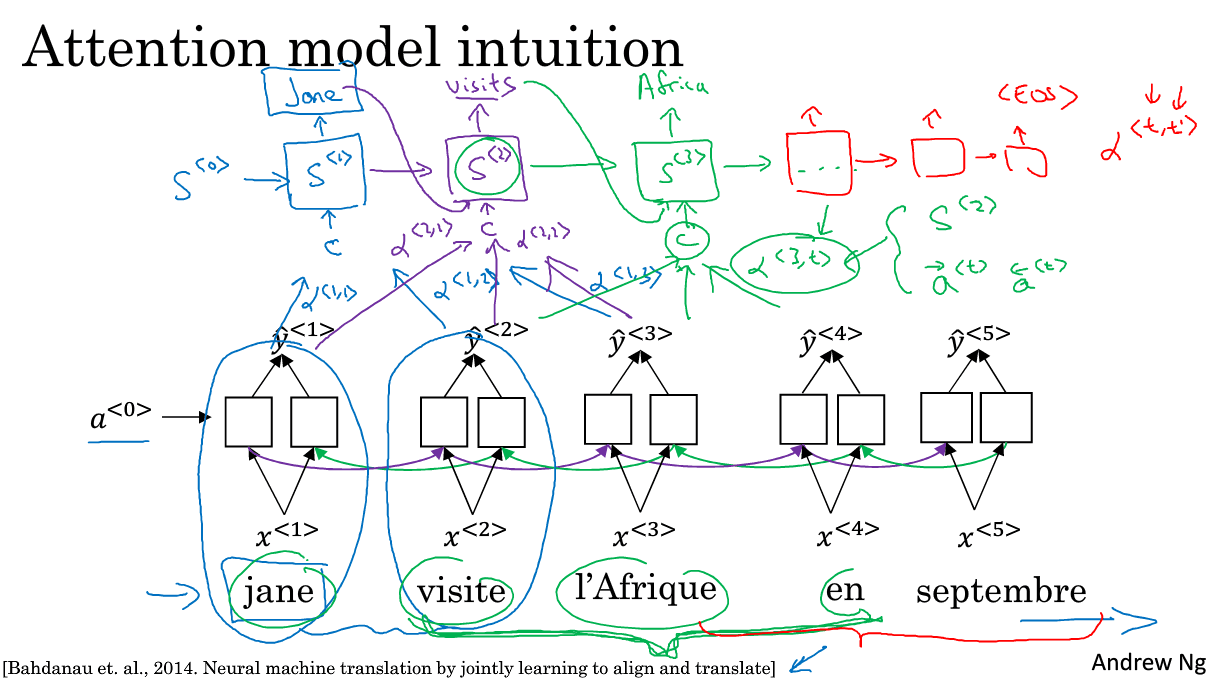
同理,也会有相应的注意力信息C输入,同时它原来的两个输入也是存在的:上一个时刻的输出与上一个熟客的隐层信息(记忆)。剩下的词以此类推,直到输出则完成翻译。
8.注意力模型深入理解
对注意力模型有了一个大概的了解之后,现在来深入讲一讲其运行机制。
encoder端如下,
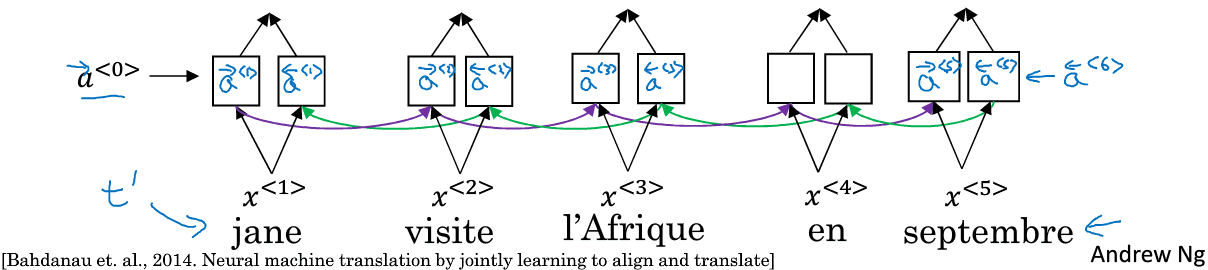
由于是双向RNN,因此每个时刻都有两个激活值,为了表示方便,我们两这两个激活值合起来表示成:
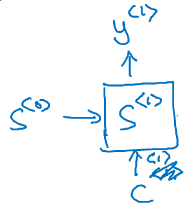
在decoder端是一个单向的RNN,时刻t=1时,有两个输入:,注意力信息C
第一个C是来自于输入端的注意力信息,,的和:
将所有加起来应等于1.
的计算公式如下:
代表着预测的单词需要给多少注意力给输入单词的激活项a
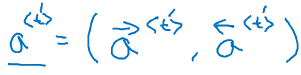
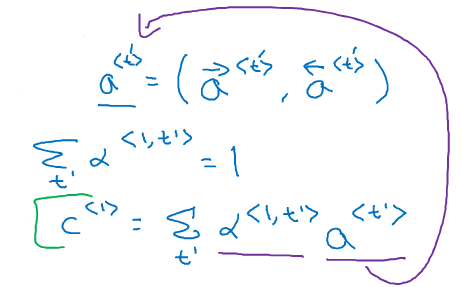
那么如何计算呢?公式如下:
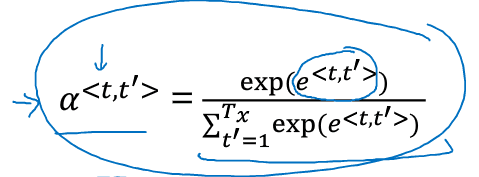
之所以用exp()来表示,可以保证所有求和后能等于1.
那么公式中的又是咋来的呢?可以用如下一个下的神经网络训练出来:
输入时上一时刻的激活值,是该时刻对应的encoder端的激活值。
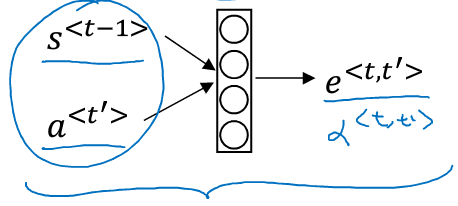
如果输入的词有个,输出的词有个,则注意里系数共有个。因此这个算法有着三次方的消耗。
在机器翻译上,输入与输出的句子大部分情况下都不会太长,因此三次方的消耗也还可以接受;但也有很多研究工作需要去尝试减少这样的消耗。
注意力系数可以可视化,比如:
不同的颜色表示注意力的大小

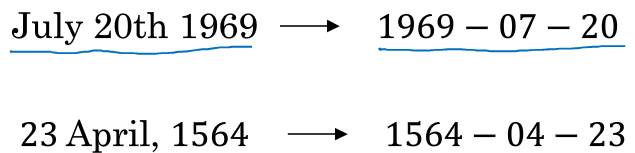
注意力机制可以用来把规则不一致的日期变有序
机器翻译就到此为止,机器翻译的结构也同时被很多其他领域借鉴,比如“图片描述生成”
9.语音辨识
AI领域最令人兴奋的发展之一就是seq2seq model使得语音识别的准确率大大提升了。
9.1什么是语音识别
简单地介绍语音识别是什么?
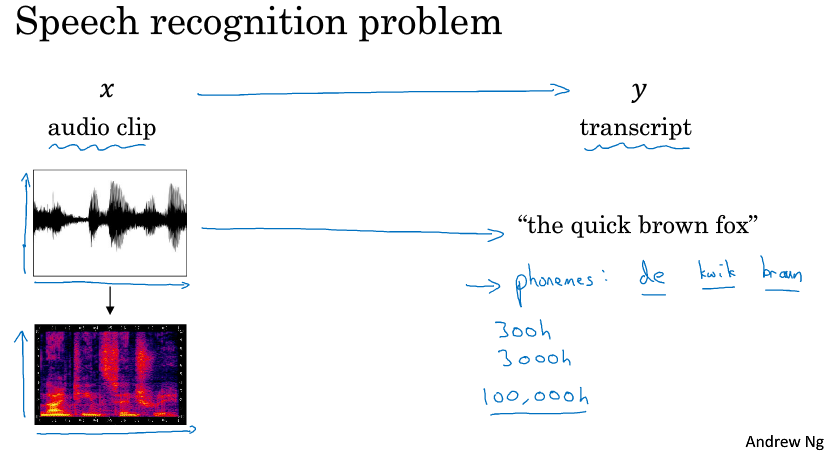
有一段音频x,任务是要自动生成文本y:
人脑处理音频是根据不同频率和强度的声波。音频数据点常见预处理步骤,是运行原始音频,然后生成一个声谱图,横轴是时间,纵轴是音频,颜色代表声波能量大小。
曾经有段时间,语音识别系统是通过音位来构建的,也就是人工设定的基本单元。但是现在有了seq2seq model之后就不需要人为设基本单元了,而是可以直接构造一个系统,向系统收入音频片段,系统直接输出文本。不过要构建这个系统需要一个很大的训练数据集,可能长达300小时,3000小时,目前最好的商业系统已经训练了100000个小时了。
9.2 如何建立语音识别系统
结构和机器翻译一样
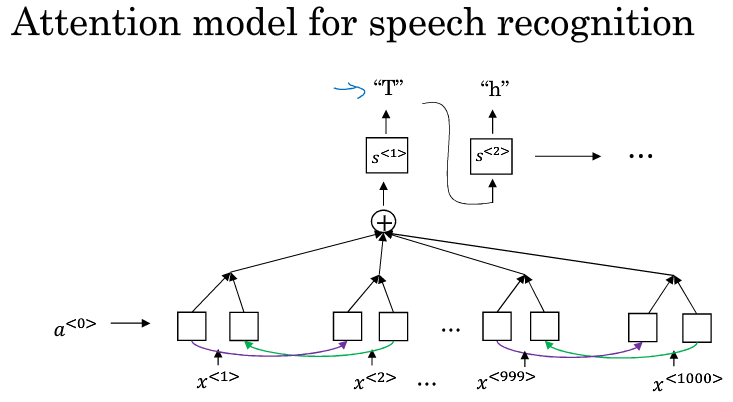
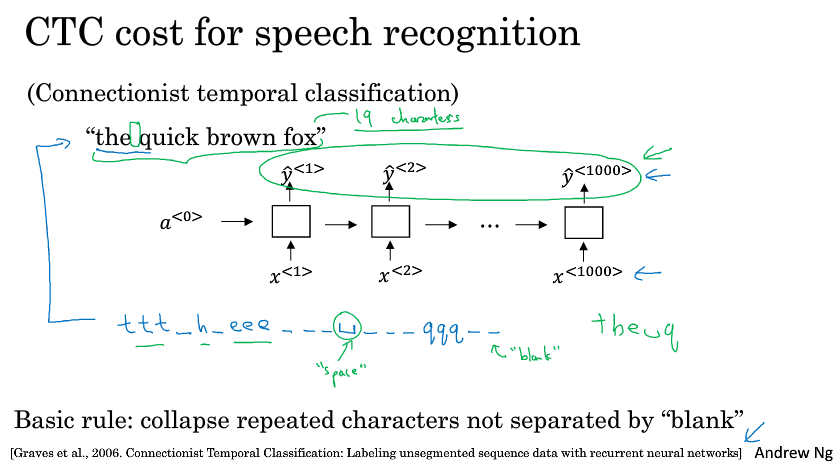
还有一种不错的方法,就是使用CTC损失函数来做语音识别(CTC:Connectionist Temporal Classification)
假设输入的语音是“the quick brown fox”
首先构建一个RNN网络(实际中更复杂,这里先用一个简单的单向网络做示范“:
在实际中,输入的时间步骤要比输出的时间步数大很多。比如你有一段10秒的音频,特征是100赫兹的,即美妙有100个样本,于是这段音频总共有1000个输入。但你的输出可能是十几个单词而已。
一个单词中的字母会重复多次,CTC就是将重复的字母叠起来组合起来,形成the q…的一句话。
10.触发字检测
什么是触发字检测呢?假设你买了一个天猫精灵音响,你每次要跟他说话之前,都必须先喊一下“天猫精灵”触发他启动,他才能去有意识得听你接下去讲的话。像这样的产品很多,他们都需要具备“触发字检测”来唤醒。
触发字检测目前还是初始状态,所以还说不上来什么算法最好,目前还没有广泛多定论。
这里简单介绍一个算法。

现在有一段音频,
先将他转换成音谱特征,然后放入RNN中,当音频中出现了触发字,则RNN在该时刻的输出就为1,否则为0
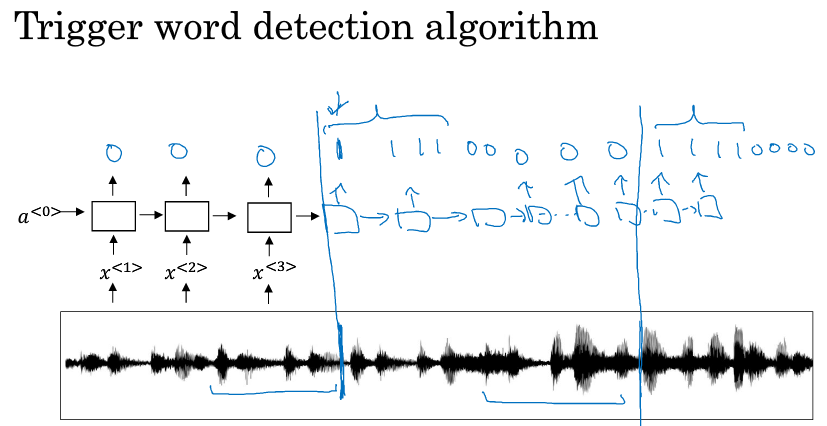
但是这个算法有很大缺点,就是它构建了一个很不平衡的训练集:0的数量比1多太多了。有一个粗暴的解决方法,就是在识别了触发词之后,即某个时刻开始输出1之后,后面就算出现了非触发词,也让他标注为1,这样就增多了1的比例。因为我们只需要识别出是否有触发词,从而判断是否唤醒,一旦识别到了1就行了。
参考文献:
第三课--序列模型和注意力机制


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现