
机器学习策略(二)---误差分析、训练集与开发测试集不相配怎么办、迁移学习/多任务学习、端到端深度学习
1.误差分析
1.1 误差分析
当算法还没有到达human level时,你需要去分析算法带来的误差,并且决定接下去应该如何优化,从而减小误差。这个过程叫做误差分析。
将设在猫狗分类的任务上,若dev set上的error有10%,此时你需要找出这些错误的case,然后统计猫错分成狗,和狗错分成猫各自的比例,如果你发现:
狗错分成猫的比例是5%
猫错分成狗的比例是95%
则此时,你无需再花大量时间在处理dog上,否则最多提升5%的正确率;而应该去分析后者。
比如针对猫的图片,将所(一部分)有bad cases找出来之后,依次分析每个badcase造成的原因,并进行统计个二类错误的比例,比如
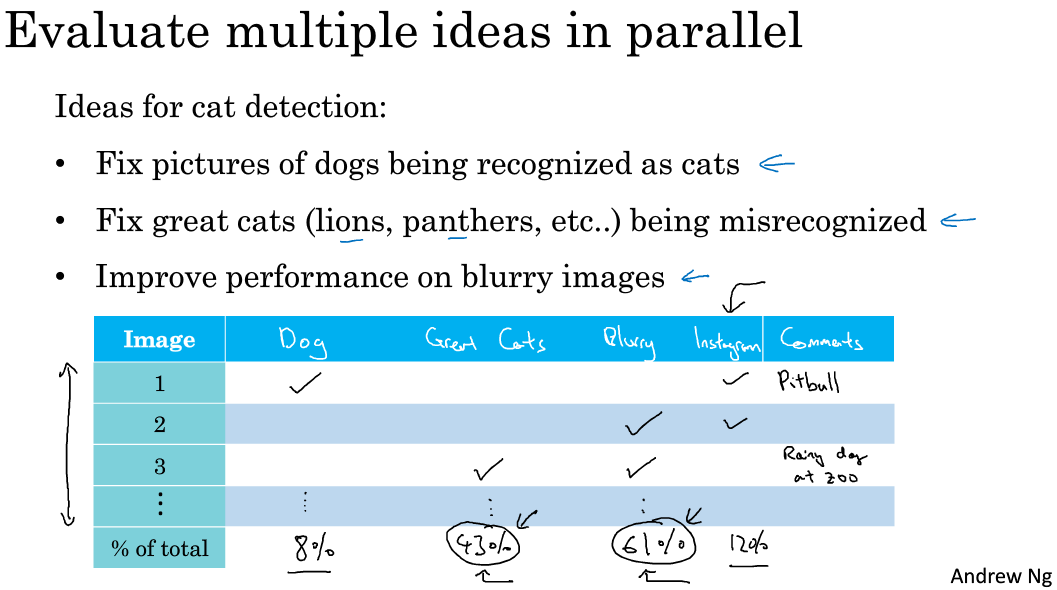
有了这个表之后,就可以针对每个问题用相应的方法去逐个解决问题。
对error analysis做一个总结
(1)找出所有bad cases
(2)逐一对每个badcase 分析找出原因
(3)分析对应的error 类别
(4)统计不同error类别站总体的比例
(5)发现问题的优先级
(6)构思新的优化方法
1.2 清除错误标注数据
(1)分析错误标注的数据
在训练集中,有人为标记错的样本很正常,因为人也不能百分之百保证正确,但这个标记错分为两类:
a.随机标记错,比如太累了或者没看清,有的时候把猫标成狗,有的时候会把狗标记成猫;
b.系统性错误,比如这批标记的人,就真的没有见过吉娃娃狗,以为他们是猫,于是把所有吉娃娃狗都标记成猫了。
对于随机错误,只要整体的训练样本足够大,则放着也没事,因为深度学习会对训练集中的随机错误有很好的鲁棒性;
但对于系统错误,则必须修正,因为分类器会学到错误的分类
因此,在误差分析中,统计badcase的同事也顺便把标注错误的数据也统计一下,然后分析是否有必要花时间去修正。
若标注错误的比例很小,对dev/test set的评估有较大影响,则需要修正
否则不修改也行。
(2)修正错误标注数据的注意点
- 若对训练集进行修正,记得也要给dev/test set进行同样的操作,以保证它们的分布是一致的。
- 对分类器分对的例子也应该有审核,也有可能有标记错误的例子。
(不过一般不会对分对的例子检查,否则实在太耗时,尤其是分类器准确率较高的情况下)
1.3 快速搭建你的第一个系统并进行迭代
建立一个全新的机器学习系统的步骤:
(1)建立训练集,开发集,测试集,以及评价指标–>制定好target
(2)快速建立一个初步的模型,并观察在训练/开发/测试集上的评估指标的表现
(3)使用bias/variance分析 & error分析 来一步一步优化模型。
(注意分析并确定优化的步骤,尤其是error anlysis, 可以发现不同error类型的重要性,找到正确的优化方向)
2.训练集与开发/测试集不相配
2.1 训练集与开发/测试不同分布怎么办?
问题:
训练集来自网络专业的图片,清晰美丽,有200,000份
测试集来自于APP用户上传的图片,模糊,取景不佳, 有10,000份
而算法更关注模型在测试集上的表现。
但若在用户上传的图片数据训练,则数据量太小,而在网络图片上训练,又无法正确应用到测试集的分布上。
怎么办呢?
法1:
将两类数据混合,再随机分出train/dev/test set:
training set: 205,000
dev set: 2500
test set: 2500
这样做的优点是:train/dev/test set都来自于同一个分布
缺点是:在每个数据集中,APP的用户图片比例非常非常少,以至于评价指标的好坏并不能满足真正业务需求需要评估水平的。因为业务上,可能是想得到对于用户图片的识别的评价指标。
法2:
将2类数据混合,并且
training set: 200000张来自于web, 5000张来自于user
dev set: 2500 来自于user
test set: 2500 来自于user
这样做的优点是:由于dev/test是来自于用户,因此优化模型在它们上的变现与实际业务需求目标相吻合
缺点是:training和dev/test的分布不同了
2.2 不相配数据分布产生的偏差与方差
假设training set和dev set来自不同分布,且error如下:
human error: 0%
training error: 1%
dev error: 10%
此时尴尬的是由于training set和dev set来自不同分布,因此不知道training error和dev error的方差9%,到底是来自于算法不好导致的方差,还是来自于分布不同导致的。
又怎么办呢?
为了区分以上两个原因分别带来的error,可以这样做
(1)将原训练集随机打乱,分割成training set和training-dev set(两组数据同分布)
(2)在新的training set上训练模型
(3)计算模型在training set, training-dev,dev set上分别的error
1> 假设结果是:
training error 1%
training-dev error 9%
dev error 10%
则8%的误差来自于模型无法泛化的variance导致的
2> 若结果是:
training error 1%
training-dev error 1.5%
dev error 10%
则8.5%的误差来自于分布不同导致
3> 若结果是:
human error 0%
training error 10%
training-dev error 11%
dev error 12%
则有10%的avoidable bias(可避免偏差)
4> 若结果是:
human error 0%
training error 10%
training-dev error 11%
dev error 22%
则有10%的avoidable bias(可避免偏差),还有11%的分布不同导致的误差
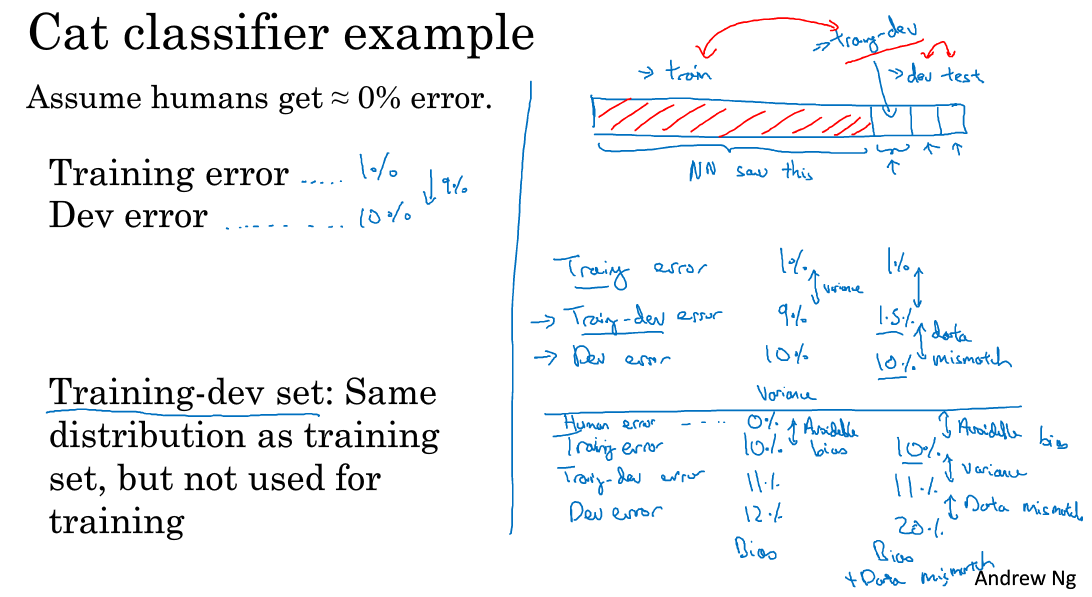
总结

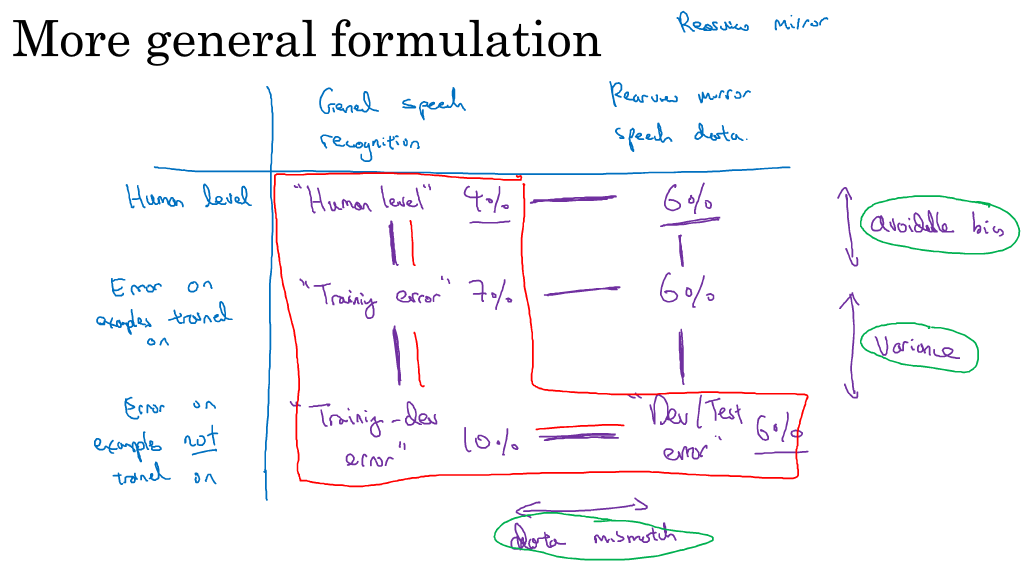
2.3 解决数据不匹配问题
(1)利用误差分析分析差异的原因
(2)使得训练数据与dev/test数据分布相同
比如人工合成数据:在音频识别中,若发现training set中是清晰的声音,但是dev set中许多汽车的噪音,则进行合成数据,在training set中也加入汽车噪声,从而使得两者分布相同。


3.其他学习任务
3.1 迁移学习
如何进行迁移学习?
(1)在数据集A上训练一个神经网络(比如训练了猫狗分类的)
(2)将以上训练好的神经网络用在B数据集上训练(比如X光照片分类)
- 若B数据集size小,则可只重新训练最后一层的参数
- 若B数据集size大,则可重新训练整个神经网络的所有参数(将原训练好的神经网络的参数作为初始参数,即通过A数据集进行预训练初始参数pre-train the weight of NN)
以上过程叫做fine-tuning
为什么进行迁移学习?
在原数据集上学到的边缘特征,有助于在新数据集中有更好的算法表现(比如结构信息,图像形状信息等其中有些信息可能会有用)
什么时候进行迁移学习?
(1)taskA,B必须有相同的input,比如都是image或者都是音频
(2)当对于你想要解决的问题数据集很小的时候,则先用大量数据做预训练,然后用少量的目标数据做迁移学习。
(3)A数据的low level特征对学习B数据有帮助的时候
3.2 多任务学习
如何进行多任务学习?
迁移学习:串行的,先执行task A-->再迁移到task B上
多任务学习:并行的,使用同一个神经网络同时实现多个目标
多任务的例子:(物体检测)
input:一张交通的图片
同时实现多个目标:检测是否有行人+是否有车+是否有stop sign+是否有light

以上例子换成神经网络图如下:
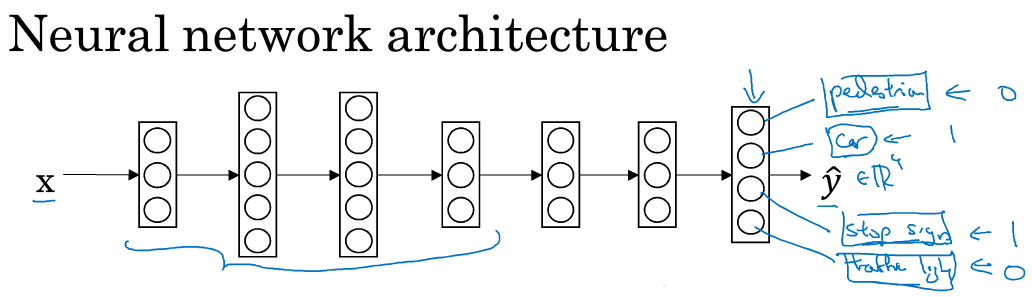
输出层有4个神经元,分别对用4个task的二维预测结果
损失函数的形式是:
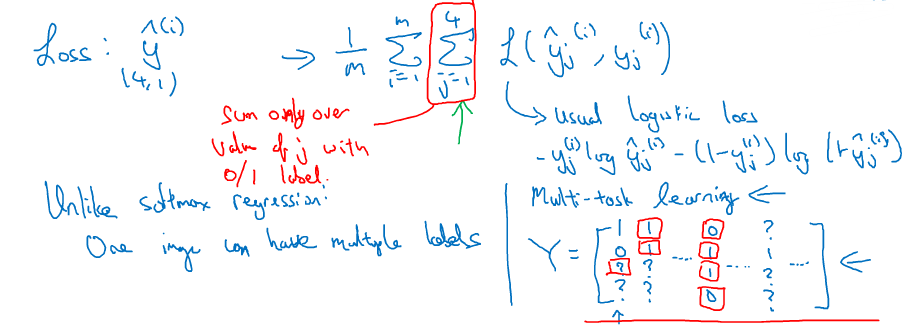
即单个样本的损失,是该样本上4个task的损失之和
训练以上神经网络即为多任务学习
注意:对于标记的训练样本,不需要对每一张图片都做以上4个label的完备标记,可以有些图片缺少某些label,也不影响神经网络的训练
什么时候进行多任务学习?
(1)当一系列task可以共享low level特征的时候
(2)usually(not always),每个任务单独所具备的训练样本数量很相似
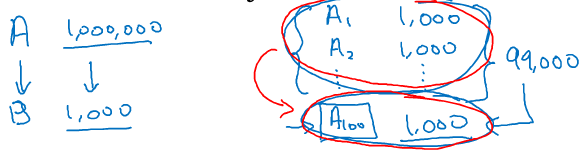
(3)训练一个足够大的多任务神经网络来代替所有单独的任务
平均来说,目前迁移学习使用频率更高
4.端到端深度学习
4.1 什么是端到端深度学习
以语音识别为例:
传统的方式:语音->特征->音位->words->transcript
端到端的方式:语音------------------------------>transcript
(端到端的方式需要足够大的数据,小数据上传统的方式更好)
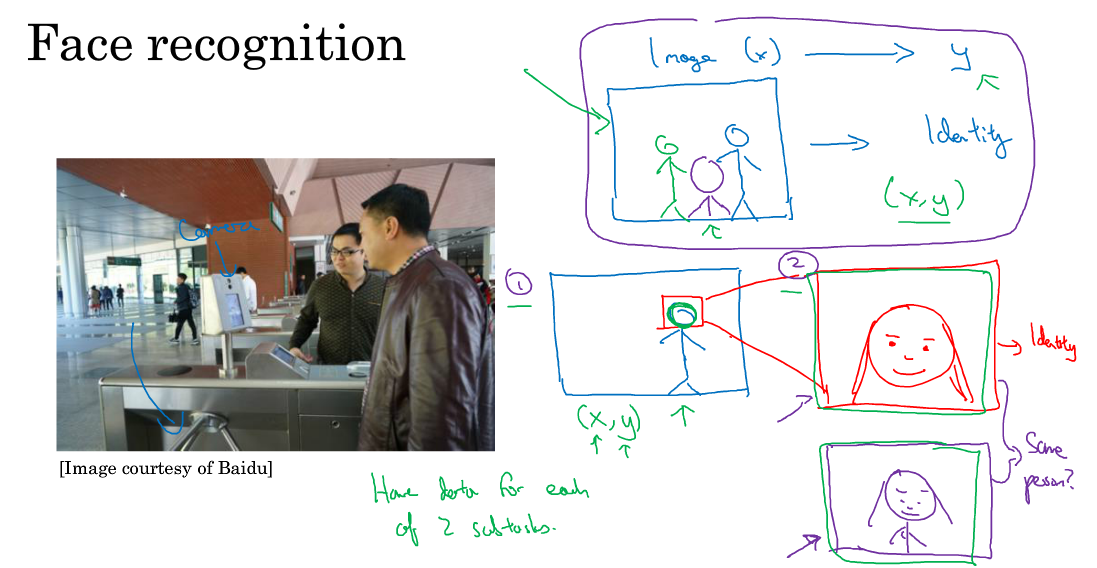
对于人脸识别,并非end to end 最好,一般分成以下2小步:
(1)识别人脸并取出人脸部分
(2)将人脸部分放大的制定大小,再喂给神经网络
对于机器翻译
如今又大量的2种语言的对应训练数据,因此目前end to end在机器翻译中表现优异

对于根据X照片判断小孩的年龄
(1)现将X照片中的每一块骨头都识别出来并取出
(2)测量每一块骨头的长度去匹配表中数据
(3)判别年龄
因为X光照的年龄数据其实很难得到,因此不适用于end to end.
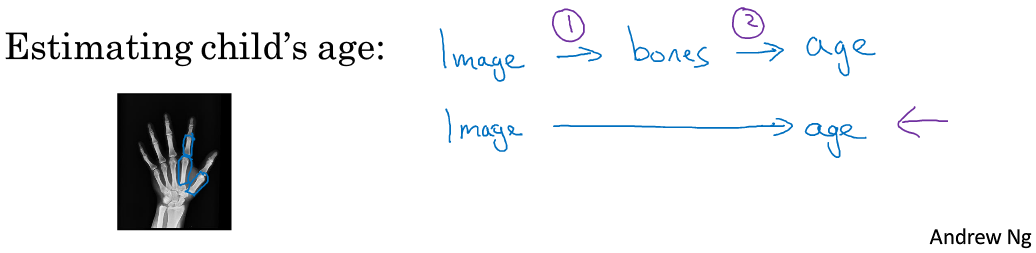
4.2 评价端到端深度学习
优点:
“”phonemes“” --> c a t
让神经网络自己学习x–>y的映射,无需人为设计与提取特征或中间表达式
缺点:
(1)需要大量数据
(2)排除了某些可能非常有用的人为设计的东西
考虑是否需要用end to end 深度学习的时候可以问自己一个问题:
Do you have sufficient data to learn a function of compexity needed to map x to y?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号