

Leetcode---3.BFS篇
BFS 相对 DFS 的最主要的区别是:BFS 找到的路径一定是最短的,但代价就是空间复杂度可能比 DFS 大很多。
BFS框架:
// 计算从起点 start 到终点 target 的最近距离
int BFS(Node start, Node target) {
Queue<Node> q; // 核心数据结构
Set<Node> visited; // 避免走回头路
q.offer(start); // 将起点加入队列
visited.add(start);
int step = 0; // 记录扩散的步数
while (q not empty) {
int sz = q.size();
/* 将当前队列中的所有节点向四周扩散 */
for (int i = 0; i < sz; i++) {
Node cur = q.poll();
/* 划重点:这里判断是否到达终点 */
if (cur is target)
return step;
/* 将 cur 的相邻节点加入队列 */
for (Node x : cur.adj()) {
if (x not in visited) {
q.offer(x);
visited.add(x);
}
}
}
/* 划重点:更新步数在这里 */
step++;
}
}
BFS 的核心数据结构;cur.adj() 泛指 cur 相邻的节点,比如说二维数组中,cur 上下左右四面的位置就是相邻节点;visited 的主要作用是防止走回头路,大部分时候都是必须的,但是像一般的二叉树结构,没有子节点到父节点的指针,不会走回头路就不需要 visited。
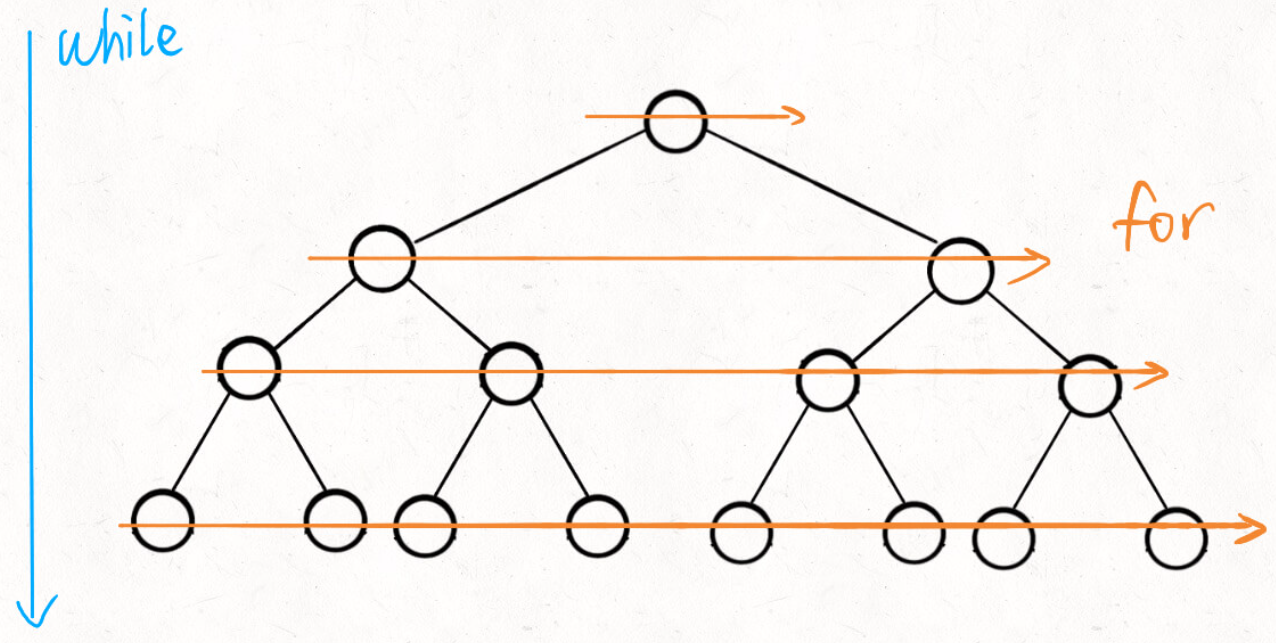
while 循环和 for 循环的配合,while 循环控制一层一层往下走,for 循环利用 sz 变量控制从左到右遍历每一层二叉树节点。
为什么 BFS 可以找到最短距离,DFS 不行吗?
首先,你看 BFS 的逻辑,depth 每增加一次,队列中的所有节点都向前迈一步,这保证了第一次到达终点的时候,走的步数是最少的。
DFS 不能找最短路径吗?其实也是可以的,但是时间复杂度相对高很多。你想啊,DFS 实际上是靠递归的堆栈记录走过的路径,你要找到最短路径,肯定得把二叉树中所有树杈都探索完才能对比出最短的路径有多长对不对?而 BFS 借助队列做到一次一步「齐头并进」,是可以在不遍历完整棵树的条件下找到最短距离的。
形象点说,DFS 是线,BFS 是面;DFS 是单打独斗,BFS 是集体行动。
既然 BFS 那么好,为啥 DFS 还要存在?
BFS 可以找到最短距离,但是空间复杂度高,而 DFS 的空间复杂度较低。
还是拿刚才我们处理二叉树问题的例子,假设给你的这个二叉树是满二叉树,节点数为 N,对于 DFS 算法来说,空间复杂度无非就是递归堆栈,最坏情况下顶多就是树的高度,也就是 O(logN)。
但是你想想 BFS 算法,队列中每次都会储存着二叉树一层的节点,这样的话最坏情况下空间复杂度应该是树的最底层节点的数量,也就是 N/2,用 Big O 表示的话也就是 O(N)。
由此观之,BFS 还是有代价的,一般来说在找最短路径的时候使用 BFS,其他时候还是 DFS 使用得多一些(主要是递归代码好写)。
参考链接:
【1】BFS 算法解题套路框架 :: labuladong的算法小抄
