
Scikit-learn---5.聚类模型
(一)通用方法、参数
1.通用方法
-
get_params([deep]):返回模型的参数。deep: 如果为True,则可以返回模型参数的子对象。
-
set_params(**params):设置模型的参数。params:待设置的关键字参数。
-
fit(X[, y, sample_weight]):训练模型。X:样本集合。通常是一个numpy array,每行代表一个样本,每列代表一个特征。y:样本的标签集合。它与X的每一行相对应。sample_weight:样本的权重。其形状为[n_samples,],每个元素代表一个样本的权重。
-
predict(X, sample_weight):返回每个样本所属的簇标记。X:样本集合。通常是一个numpy array,每行代表一个样本,每列代表一个特征。sample_weight:样本的权重。其形状为[n_samples,],每个元素代表一个样本的权重。
-
fit_predict(X[, y, sample_weight]):训练模型并执行聚类,返回每个样本所属的簇标记。X:样本集合。通常是一个numpy array,每行代表一个样本,每列代表一个特征。y:样本的标签集合。它与X的每一行相对应。sample_weight:样本的权重。其形状为[n_samples,],每个元素代表一个样本的权重。
-
transform(X):将数据集X转换到cluster center space。在
cluster center space中,样本的维度就是它距离各个聚类中心的距离。X:样本集合。通常是一个numpy array,每行代表一个样本,每列代表一个特征。
-
fit_transform(X[, y, sample_weight]):训练模型并执行聚类,将数据集X转换到cluster center space。X:样本集合。通常是一个numpy array,每行代表一个样本,每列代表一个特征。y:样本的标签集合。它与X的每一行相对应。sample_weight:样本的权重。其形状为[n_samples,],每个元素代表一个样本的权重。
2.通用参数
-
n_jobs:一个正数,指定任务并形时指定的CPU数量。如果为
-1则使用所有可用的CPU。 -
verbose:一个正数。用于开启/关闭迭代中间输出日志功能。- 数值越大,则日志越详细。
- 数值为0或者
None,表示关闭日志输出。
-
max_iter:一个整数,指定最大迭代次数。如果为
None则为默认值(不同solver的默认值不同)。 -
tol:一个浮点数,指定了算法收敛的阈值。 -
random_state:一个整数或者一个RandomState实例,或者None。- 如果为整数,则它指定了随机数生成器的种子。
- 如果为
RandomState实例,则指定了随机数生成器。 - 如果为
None,则使用默认的随机数生成器。
一、KMeans
二、DBSCAN
1 2 | class sklearn.cluster.DBSCAN(eps=0.5, min_samples=5, metric='euclidean', metric_params=None, algorithm='auto', leaf_size=30, p=None, n_jobs=None) |
1.参数
-
eps:参数,用于确定邻域大小。
MinPts -
min_samples:参数,用于判断核心对象。 -
metric:一个字符串或者可调用对象,用于计算距离。如果是字符串,则必须是
metrics.pairwise.calculate_distance中指定的。 -
metric_params:一个字典,当metric为可调用对象时,为metric提供关键字参数。 -
algorithm:一个字符串,用于计算两点间距离并找出最近邻的点。可以为:'auto':由算法自动选取合适的算法。'ball_tree':用ball树来搜索。'kd_tree':用kd树来搜索。'brute':暴力搜索。
-
leaf_size:一个整数,用于指定当algorithm=ball_tree或者kd_tree时,树的叶结点大小。该参数会影响构建树、搜索最近邻的速度,同时影响存储树的内存。
-
p:一个浮点数,指定闵可夫斯基距离的值。ϵ -
n_jobs:指定并行度。
2.属性
-
core_sample_indices_:一个形状为[n_core_samples,]的数组,给出了核心样本在原始训练集中的位置。 -
components_:一个形状为[n_core_samples,n_features]的数组,给出了核心样本的一份拷贝 -
labels_:一个形状为[n_samples,]的数组,给出了每个样本所属的簇标记。对于噪音样本,其簇标记为 -1。
3.方法
fit(X[, y, sample_weight]):训练模型。fit_predict(X[, y, sample_weight]):训练模型并执行聚类,返回每个样本所属的簇标记。
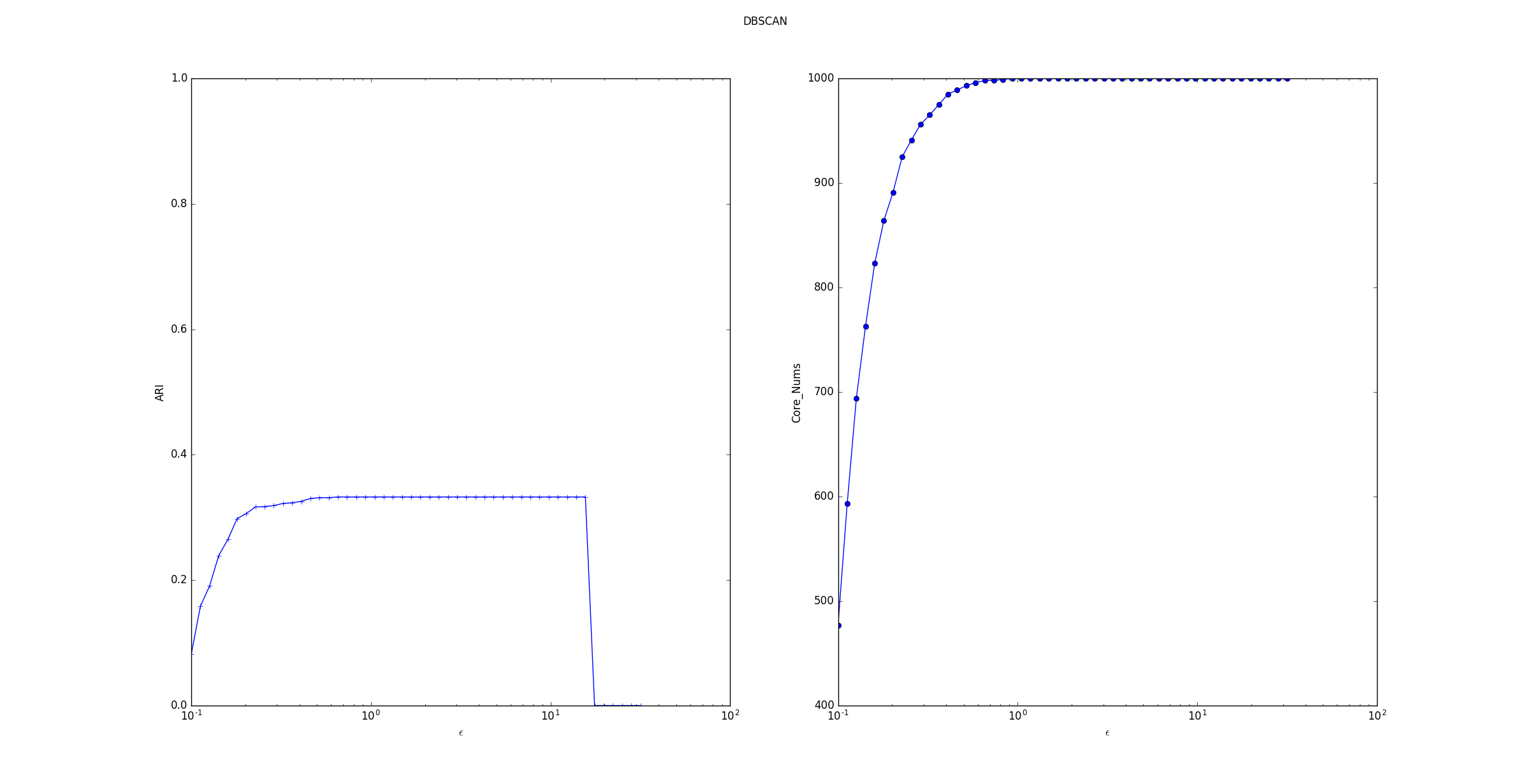
4.考察参数的影响
-
ARI指数随着 的增长,先上升后保持平稳最后断崖下降。 断崖下降是因为产生的训练样本的间距比较小,最远的两个样本点之间的距离不超过 30。当ϵ过大时,所有的点都在一个邻域中。
-
核心样本数量随着ϵ的增长而上升。这是因为随着ϵ的增长,样本点的邻域在扩展,则样本点邻域内的样本会更多,这就产生了更多满足条件的核心样本点。但是样本集中的样本数量有限,因此核心样本点数量的增长到一定数目后稳定。
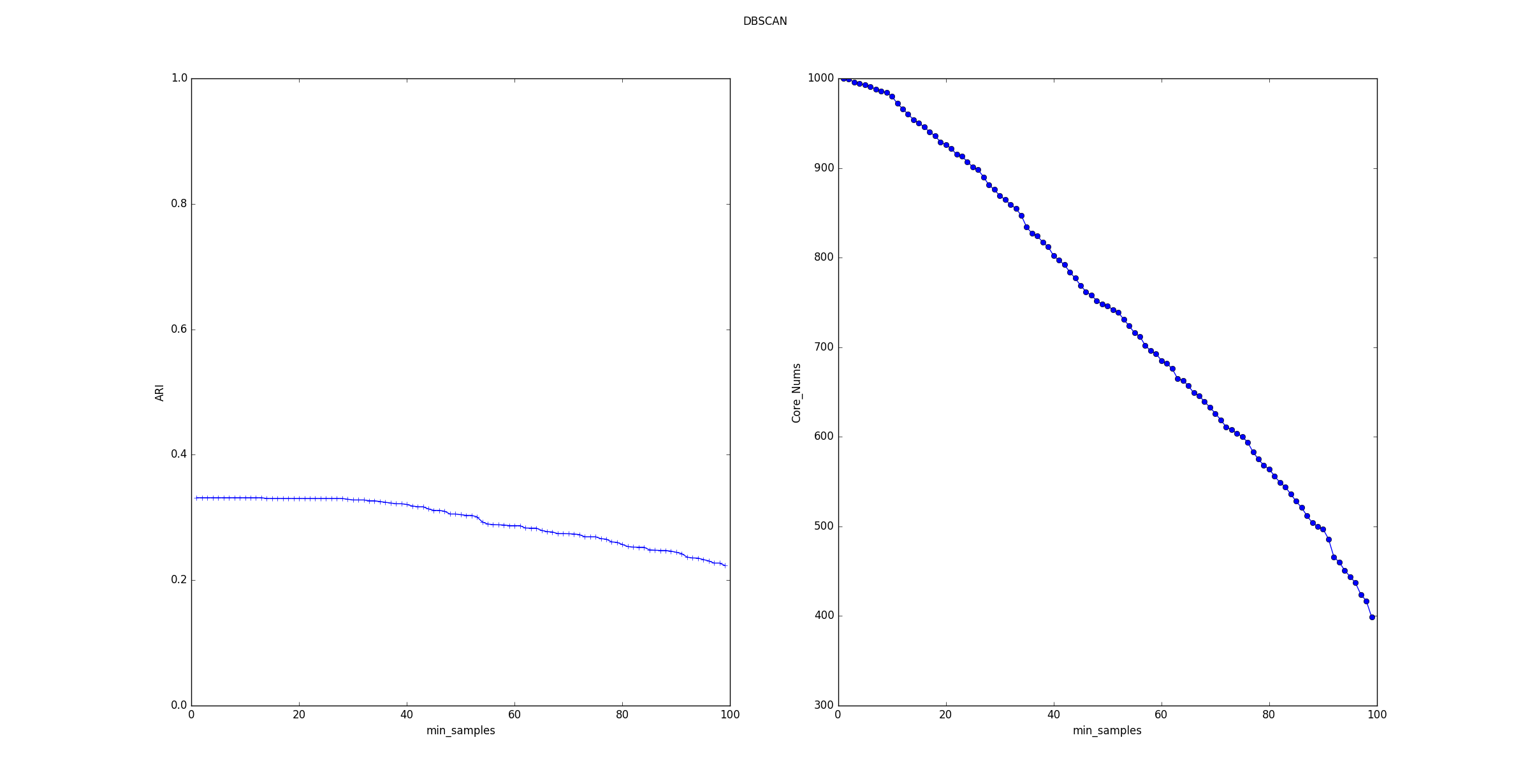
5.考察MinPts参数的影响
-
ARI指数随着的增长,平稳的下降。
-
核心样本数量随着MinPts的增长基本上线性下降。这是因为随着MinPts的增长,样本点的邻域中必须包含更多的样本才能使它成为一个核心样本点。因此产生的核心样本点越来越少。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现
2018-12-27 去掉python的警告