
Pandas---3.下标存取([]/loc/iloc/ix/at/iat/query方法/多级索引/整数label)
一、[ ] 操作符
1.Index
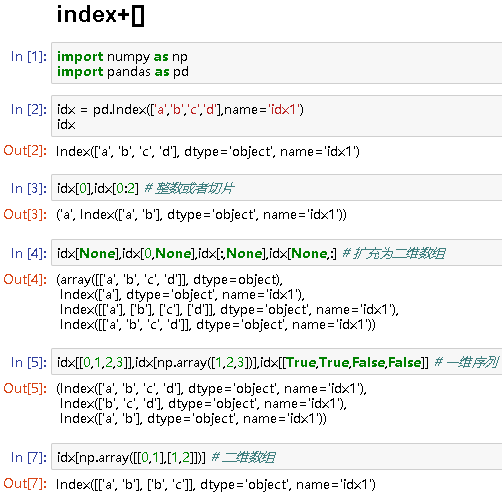
对于Index对象,可以通过[]来选取数据,它类似于一维ndarray的索引。下标可以为下列几种下标对象:
-
一个整数下标。此时返回对应的
label -
一个整数
slice。此时返回对应的Index(根据一维labels先切片,再组装成Index) -
一个
array-like对象(元素可以为下标或者布尔值)。此时返回对应的Index。(根据一维labels先索引,再组装成Index) -
由
None组成的二元组,其中None相当于新建一个轴。- 如果
None为第一个元素,则新建的轴为 0 轴; - 如果
None为第二个元素,则新建的轴为 1 轴。 - 另外
idx[None]等价于idx[None,:],但是idx[None]返回的是ndarray。 - 它并没有将
Index转换成MultiIndex,只是将Index内部的数据数组扩充了一个轴
- 如果
Index 的索引只支持整数/整数
slice/整数序列/布尔序列/整数数组/布尔数组/None 等。
举例:
import numpy as np
import pandas as pd
idx = pd.Index(['a','b','c','d'],name='idx1')
idx
# Index(['a', 'b', 'c', 'd'], dtype='object', name='idx1')
idx[0],idx[0:2] # 整数或者切片
# ('a', Index(['a', 'b'], dtype='object', name='idx1'))
idx[None],idx[0,None],idx[:,None],idx[None,:] # 扩充为二维数组
# (array([['a', 'b', 'c', 'd']], dtype=object),
Index(['a'], dtype='object', name='idx1'),
Index([['a'], ['b'], ['c'], ['d']], dtype='object', name='idx1'),
Index([['a', 'b', 'c', 'd']], dtype='object', name='idx1'))
idx[[0,1,2,3]],idx[np.array([1,2,3])],idx[[True,True,False,False]] # 一维序列
# (Index(['a', 'b', 'c', 'd'], dtype='object', name='idx1'),
Index(['b', 'c', 'd'], dtype='object', name='idx1'),
Index(['a', 'b'], dtype='object', name='idx1'))
idx[np.array([[0,1],[1,2]])] # 二维数组
# Index([['a', 'b'], ['b', 'c']], dtype='object', name='idx1')
2.Series
(1)[]
对于Series对象,可以通过[]来选取数据,它类似于一维ndarray的索引。下标可以为下列几种下标对象:
-
一个整数下标/一个属性(属性名为某个
label)/字典索引(键为label):返回对应的数值 -
一个整数切片/一个
label切片:返回对应的Series。(根据一维Series先切片,再组装成Series)。注意:label切片同时包含了起始label和终止label -
一个整数
array-like/一个label array-like/一个布尔ndarray:返回对应的Series。(根据一维Series先索引,再组装成Series) - 一个二维整数
array-like/二维label array-like:返回对应值组成的二维ndarray
注意:
Series必须使用布尔数组来索引,不支持布尔序列来索引(抛出KeyError异常)。
举例:
idx # Index(['a', 'b', 'c', 'd'], dtype='object', name='idx1') s = pd.Series([0,3,5,7],index=idx,name='ser1') s # idx1 a 0 b 3 c 5 d 7 Name: ser1, dtype: int64 s.a,s['b'],s[2] # 单个label,单个loc # (0, 3, 5) print(s['a':'c'],s[0:2],sep='\n------\n') # 切片labels,切片loc # idx1 a 0 b 3 c 5 Name: ser1, dtype: int64 ------ idx1 a 0 b 3 Name: ser1, dtype: int64 print(s[['a','c','b']],s[[3,0,1]],sep='\n------\n') # 序列label,序列loc # idx1 a 0 c 5 b 3 Name: ser1, dtype: int64 ------ idx1 d 7 a 0 b 3 Name: ser1, dtype: int64 r1 = s[np.array(['a','c','b'])] r2 = s[np.array([0,1,1,3])] r3 = s[np.array([[0,1],[1,3]])] print(r1,type(r1),r2,type(r2),r3,type(r3),sep="\n----------\n") # 数组label,数组loc # idx1 a 0 c 5 b 3 Name: ser1, dtype: int64 ---------- <class 'pandas.core.series.Series'> ---------- idx1 a 0 b 3 b 3 d 7 Name: ser1, dtype: int64 ---------- <class 'pandas.core.series.Series'> ---------- [[0 3] [3 7]] ---------- <class 'numpy.ndarray'> r = s[s>4] print(r) # 数组label,数组loc # idx1 c 5 d 7 Name: ser1, dtype: int64


(2)索引标签
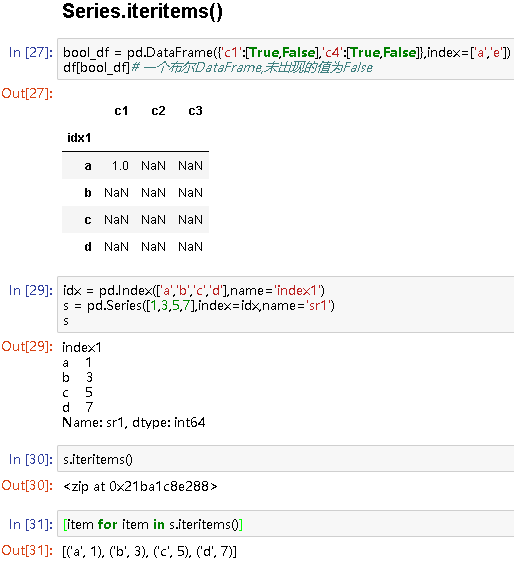
Series对象除了支持使用位置作为下标存取元素之外,还可以使用索引标签来存取元素。这个功能与字典类似,因此它也支持字典的一些方法,如Series.iteritems()。
举例:
bool_df = pd.DataFrame({'c1':[True,False],'c4':[True,False]},index=['a','e'])
df[bool_df]# 一个布尔DataFrame,未出现的值为False
# c1 c2 c3
idx1
a 1.0 NaN NaN
b NaN NaN NaN
c NaN NaN NaN
d NaN NaN NaN
idx = pd.Index(['a','b','c','d'],name='index1')
s = pd.Series([1,3,5,7],index=idx,name='sr1')
s
# index1
a 1
b 3
c 5
d 7
Name: sr1, dtype: int64
s.iteritems()
# <zip at 0x21ba1c8e288>
[item for item in s.iteritems()]
# [('a', 1), ('b', 3), ('c', 5), ('d', 7)]
(3)对于Series的赋值与删除
- 对于单个索引或者切片索引,要求右侧数值的长度与左侧相等
- 为不存在的
label赋值会创建出一个新行(必须用字典的形式,不能用属性赋值的形式) - 关键字
del用于删除行(必须用字典的形式,不能用属性赋值的形式)
举例:
s = pd.Series(np.arange(1,4),index=['a','b','c']) s # a 1 b 2 c 3 dtype: int32 s.a = -1 # 直接赋值 s # a -1 b 2 c 3 dtype: int32 s[0:2] = -11,-22 # 元组赋值 s # a -11 b -22 c 3 dtype: int32 s['d'] = 4 # 创建一个新的行 s # a -11 b -22 c 3 d 4 dtype: int64 del s['d'] s # a -11 b -22 c 3 dtype: int64

3.DataFrame
(1)[]
对于DataFrame对象,可以通过[]来选取数据。下标可以为下列几种下标对象:
-
一个属性(属性名为某个
column label)/字典索引(键为column label):返回对应的列对应的Series不可以使用单个整数来索引
-
一个整数切片/一个
row label切片:返回对应的行组成的DataFrame。注意:label切片同时包含了起始label和终止label -
一个一维
label array-like:返回对应的列组成的DataFrame -
一个布尔数组:返回数组中
True对应的行组成的DataFrame。 -
一个布尔
DataFrame:将该布尔DataFrame中的False对应的元素设置为NaN(布尔DataFrame中没有出现的值为False)
举例:
df = pd.DataFrame({'c1':[1,2,3,4],'c2':[5,6,7,8],'c3':[9,10,11,12]},index=idx)
df
# c1 c2 c3
idx1
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12
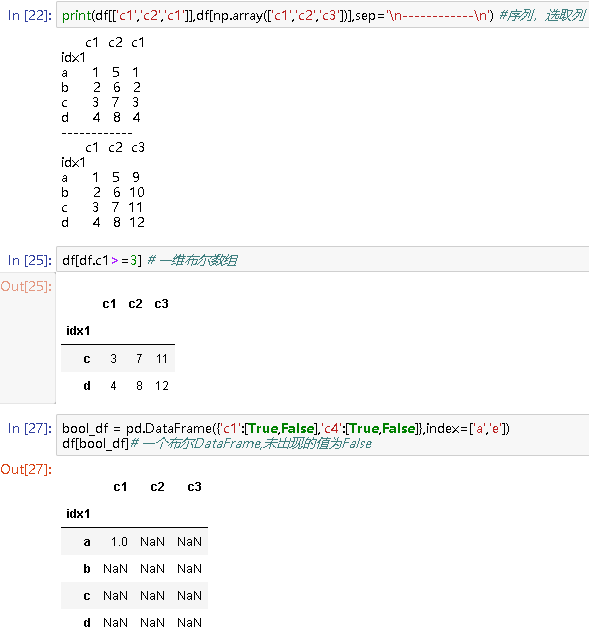
print(df.c1,df['c2'],sep='\n------------\n') # 单个值,选取列
# idx1
a 1
b 2
c 3
d 4
Name: c1, dtype: int64
------------
idx1
a 5
b 6
c 7
d 8
Name: c2, dtype: int64
print(df[0:2],df['a':'c'],sep='\n------------\n') # 切片,选取行
# c1 c2 c3
idx1
a 1 5 9
b 2 6 10
------------
c1 c2 c3
idx1
a 1 5 9
b 2 6 10
c 3 7 11
print(df[['c1','c2','c1']],df[np.array(['c1','c2','c3'])],sep='\n------------\n') #序列,选取列
# c1 c2 c1
idx1
a 1 5 1
b 2 6 2
c 3 7 3
d 4 8 4
------------
c1 c2 c3
idx1
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12
df[df.c1>=3] # 一维布尔数组
# c1 c2 c3
idx1
c 3 7 11
d 4 8 12
bool_df = pd.DataFrame({'c1':[True,False],'c4':[True,False]},index=['a','e'])
df[bool_df]# 一个布尔DataFrame,未出现的值为False
#
c1 c2 c3
idx1
a 1.0 NaN NaN
b NaN NaN NaN
c NaN NaN NaN
d NaN NaN NaN

(2)对于DataFrame的赋值与列删除
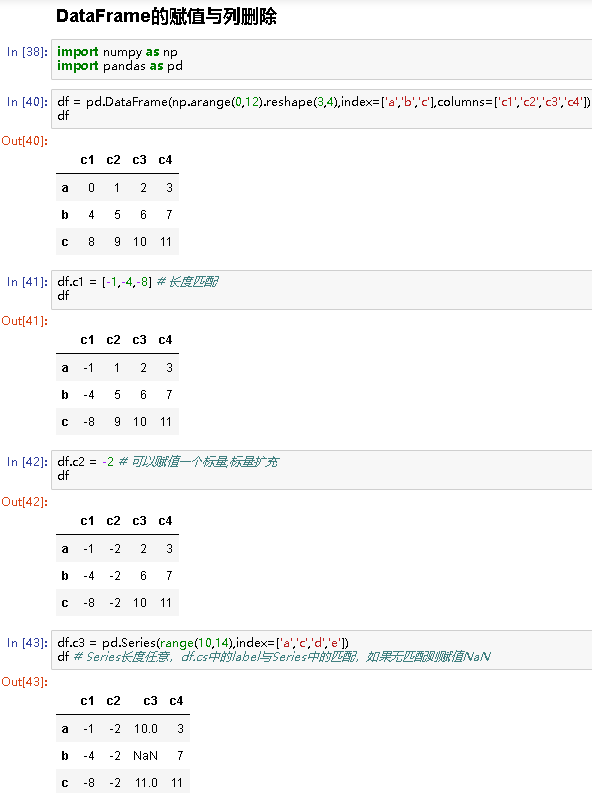
- 将列表或者数组赋值给某个列时,其长度必须跟
DataFrame的行数匹配。 - 将标量赋值给某个列时,会将标量扩充
- 将
Series赋值给某个列时,会精确匹配DataFrame的索引。如果DataFrame中某个label在Series中找不到,则赋值NaN(空位都将被填上缺失值) - 为不存在的列赋值会创建出一个新列(必须用字典的形式,不能用属性赋值的形式)
- 关键字
del用于删除列(必须用字典的形式,不能用属性赋值的形式)
举例:
import numpy as np import pandas as pd df = pd.DataFrame(np.arange(0,12).reshape(3,4),index=['a','b','c'],columns=['c1','c2','c3','c4']) df # c1 c2 c3 c4 a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 df.c1 = [-1,-4,-8] # 长度匹配 df # c1 c2 c3 c4 a -1 1 2 3 b -4 5 6 7 c -8 9 10 11 df.c2 = -2 # 可以赋值一个标量,标量扩充 df #c1 c2 c3 c4 a -1 -2 2 3 b -4 -2 6 7 c -8 -2 10 11 df.c3 = pd.Series(range(10,14),index=['a','c','d','e']) df # Series长度任意,df.cs中的label与Series中的匹配,如果无匹配则赋值NaN # c1 c2 c3 c4 a -1 -2 10.0 3 b -4 -2 NaN 7 c -8 -2 11.0 11 df['c5'] = [-1,-2,-3] # 创建一个新列 df # c1 c2 c3 c4 c5 a -1 -2 10.0 3 -1 b -4 -2 NaN 7 -2 c -8 -2 11.0 11 -3 del df['c5'] df # c1 c2 c3 c4 a -1 -2 10.0 3 b -4 -2 NaN 7 c -8 -2 11.0 11

4.注意事项
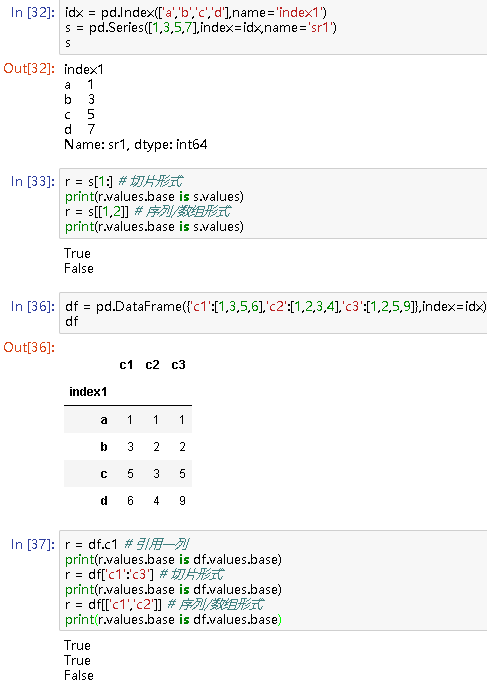
(1)对于Series/DataFrame切片方式的索引,返回的结果与原始对象共享基础数据。对于采用其他方式的索引,返回的结果并不与元素对象共享基础数据。
idx = pd.Index(['a','b','c','d'],name='index1')
s = pd.Series([1,3,5,7],index=idx,name='sr1')
s
# index1
a 1
b 3
c 5
d 7
Name: sr1, dtype: int64
r = s[1:] # 切片形式
print(r.values.base is s.values)
r = s[[1,2]] # 序列/数组形式
print(r.values.base is s.values)
# True
False
df = pd.DataFrame({'c1':[1,3,5,6],'c2':[1,2,3,4],'c3':[1,2,5,9]},index=idx)
df
# c1 c2 c3
index1
a 1 1 1
b 3 2 2
c 5 3 5
d 6 4 9
r = df.c1 # 引用一列
print(r.values.base is df.values.base)
r = df['c1':'c3'] # 切片形式
print(r.values.base is df.values.base)
r = df[['c1','c2']] # 序列/数组形式
print(r.values.base is df.values.base)
# True
True
False
(2)如果Series/DataFrame的索引有重复label,则数据的选取行为将有所不同:
- 如果索引对应多个
label,则Series返回一个Sereis,DataFrame返回一个DataFrame - 如果索引对应单个
label,则Series返回一个标量值,DataFrame返回一个Series
你可以通过Index.is_unique属性得知索引是否有重复的。
- 对于
[]、字典索引、属性索引或者.loc/.ix存取器,结论如上所述 - 对于
.at存取器:如果索引对应单个label,索引结果正常。如果索引对应多个label,则Series返回一个一维ndarray;DataFrame则抛出异常。
举例:
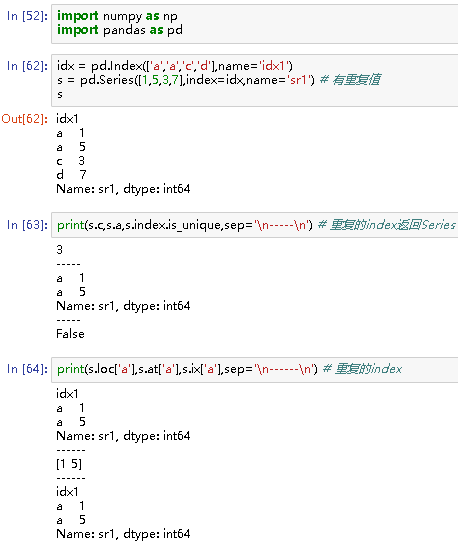
import numpy as np
import pandas as pd
idx = pd.Index(['a','a','c','d'],name='idx1')
s = pd.Series([1,5,3,7],index=idx,name='sr1') # 有重复值
s
# idx1
a 1
a 5
c 3
d 7
Name: sr1, dtype: int64
print(s.c,s.a,s.index.is_unique,sep='\n-----\n') # 重复的index返回Series
# 3
-----
a 1
a 5
Name: sr1, dtype: int64
-----
False
print(s.loc['a'],s.at['a'],s.ix['a'],sep='\n------\n') # 重复的index
# idx1
a 1
a 5
Name: sr1, dtype: int64
------
[1 5]
------
idx1
a 1
a 5
Name: sr1, dtype: int64
idx = pd.Index(['a','b','c','d'],name='idx1')
df = pd.DataFrame({'c1':[1,3,2,4],'c2':[11,14,13,12]},index=idx)
# df.columns = pd.Index(['c1','c1'],name='idx2')
df
# c1 c2
idx1
a 1 11
b 3 14
c 2 13
d 4 12
df.columns = pd.Index(['c1','c1'],name='idx2')
df
#
idx2 c1 c1
idx1
a 1 11
b 3 14
c 2 13
d 4 12
df.index
# Index(['a', 'b', 'c', 'd'], dtype='object', name='idx1')
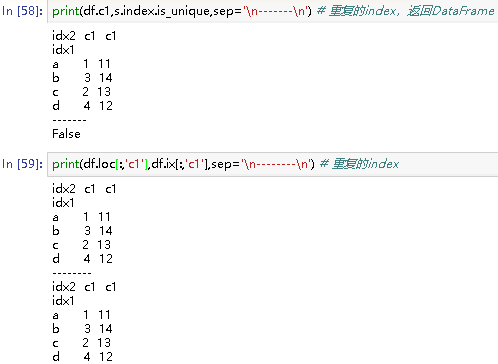
print(df.c1,s.index.is_unique,sep='\n-------\n') # 重复的index,返回DataFrame
# idx2 c1 c1
idx1
a 1 11
b 3 14
c 2 13
d 4 12
-------
False
print(df.loc[:,'c1'],df.ix[:,'c1'],sep='\n--------\n') # 重复的index
# idx2 c1 c1
idx1
a 1 11
b 3 14
c 2 13
d 4 12
--------
idx2 c1 c1
idx1
a 1 11
b 3 14
c 2 13
d 4 12

(3)对于Series/DataFrame,它们可以使用ndarray的接口。因此可以通过ndarray 的索引规则来索引它们。
df=pd.DataFrame(...) df[:,0] #使用了 ndarray 的索引方式
二、loc/iloc/ix 存取器
1.loc
(1)Series
对于Series,.loc[]的下标对象可以为:
- 单个
label,此时返回对应的值 label的array-like、label slice以及布尔array-like:返回对应值组成的Series
举例:
import numpy as np import pandas as pd idx = pd.Index(['a','b','c','d'],name='idx1') s = pd.Series([0,3,5,7],index=idx,name='ser1') s # idx1 a 0 b 3 c 5 d 7 Name: ser1, dtype: int64 print(s.loc['a'],s.loc['a':'c'],s.loc[['a','c']],s.loc[[True,True,False,False]],sep='\n-------------\n') #单个Label,切片label,label列表 # 0 ------------- idx1 a 0 b 3 c 5 Name: ser1, dtype: int64 ------------- idx1 a 0 c 5 Name: ser1, dtype: int64 ------------- idx1 a 0 b 3 Name: ser1, dtype: int64

(2)DataFrame
对于DataFrame,.loc[]的下标对象是一个元组,其中两个元素分别与DataFrame的两个轴对应。如果下标不是元组,则该下标对应的是第0轴,第一轴为默认值:。
- 每个轴的下标都支持单个
label、label array-like、label slice、布尔array-like。 - 若获取的是某一列或者某一行,则返回的是
Series;若返回的是多行或者多列,则返回的是DataFrame;如果返回的是某个值,则是普通的标量。
举例:
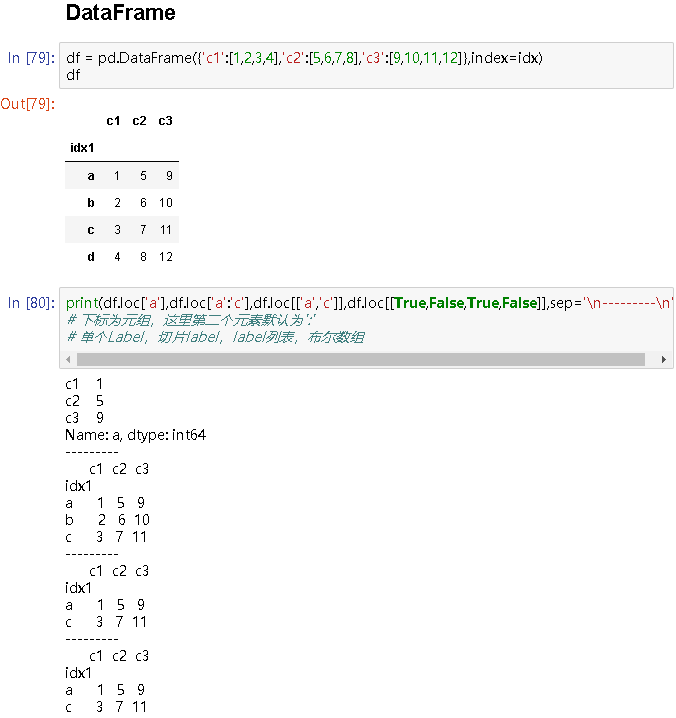
df = pd.DataFrame({'c1':[1,2,3,4],'c2':[5,6,7,8],'c3':[9,10,11,12]},index=idx)
df
# c1 c2 c3
idx1
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12
print(df.loc['a'],df.loc['a':'c'],df.loc[['a','c']],df.loc[[True,False,True,False]],sep='\n---------\n')
# 下标为元组,这里第二个元素默认为':'
# 单个Label,切片label,label列表,布尔数组
# c1 1
c2 5
c3 9
Name: a, dtype: int64
---------
c1 c2 c3
idx1
a 1 5 9
b 2 6 10
c 3 7 11
---------
c1 c2 c3
idx1
a 1 5 9
c 3 7 11
---------
c1 c2 c3
idx1
a 1 5 9
c 3 7 11
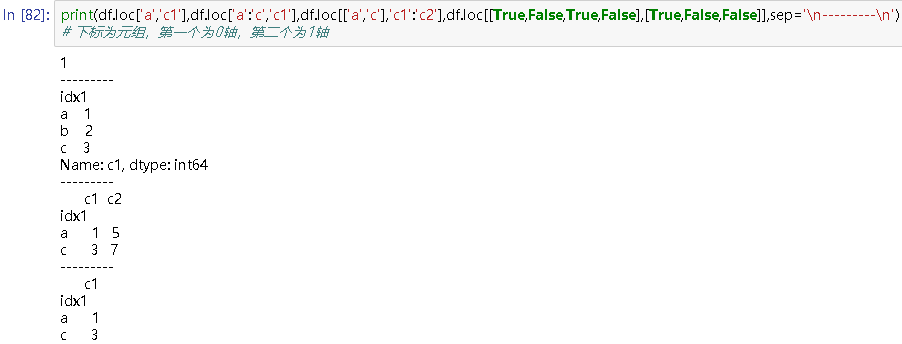
print(df.loc['a','c1'],df.loc['a':'c','c1'],df.loc[['a','c'],'c1':'c2'],df.loc[[True,False,True,False],[True,False,False]],sep='\n---------\n')
# 下标为元组,第一个为0轴,第二个为1轴
# 1
---------
idx1
a 1
b 2
c 3
Name: c1, dtype: int64
---------
c1 c2
idx1
a 1 5
c 3 7
---------
c1
idx1
a 1
c 3
2.iloc
.iloc[]和.loc[]类似,但是.iloc[]使用整数下标,而不是使用label。注意整数切片不包括最后一个值。
(1)Serise
import numpy as np import pandas as pd idx = pd.Index(['a','b','c','d'],name='idx1') s = pd.Series([0,3,5,7],index=idx,name='ser1') s # idx1 a 0 b 3 c 5 d 7 Name: ser1, dtype: int64 print(s.iloc[0],s.iloc[0:1],s.iloc[[0,1,2]],s.iloc[[True,False,True,False]],sep='\n-----\n') # iloc使用整数下标而不是label # 0 ----- idx1 a 0 Name: ser1, dtype: int64 ----- idx1 a 0 b 3 c 5 Name: ser1, dtype: int64 ----- idx1 a 0 c 5 Name: ser1, dtype: int64

(2)DataFrame
df = pd.DataFrame({'c1':[1,2,3,4],'c2':[5,6,7,8],'c3':[9,10,11,12]},index=idx)
df
# c1 c2 c3
idx1
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12
print(df.iloc[0],df.iloc[0:2],df.iloc[[0,2]],df.iloc[[True,False,True,False]],sep='\n--------\n')
# 下标为元组,这里第二个元素默认为':',# iloc使用整数下标而不是label
# c1 1
c2 5
c3 9
Name: a, dtype: int64
--------
c1 c2 c3
idx1
a 1 5 9
b 2 6 10
--------
c1 c2 c3
idx1
a 1 5 9
c 3 7 11
--------
c1 c2 c3
idx1
a 1 5 9
c 3 7 11
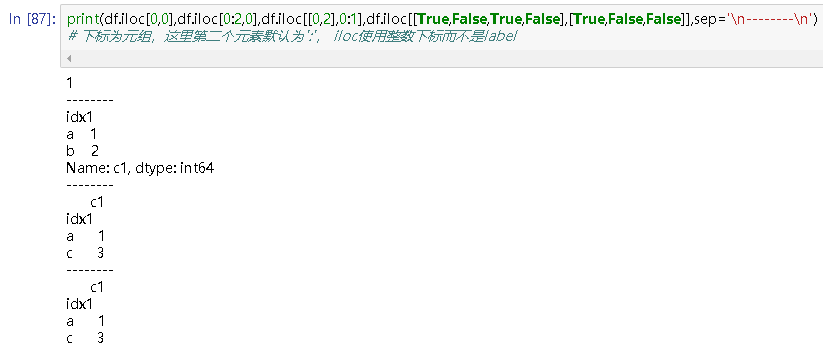
print(df.iloc[0,0],df.iloc[0:2,0],df.iloc[[0,2],0:1],df.iloc[[True,False,True,False],[True,False,False]],sep='\n--------\n')
# 下标为元组,这里第二个元素默认为':', iloc使用整数下标而不是label
# 1
--------
idx1
a 1
b 2
Name: c1, dtype: int64
--------
c1
idx1
a 1
c 3
--------
c1
idx1
a 1
c 3

3.ix
.ix[]存取器综合了.iloc/.loc:它可以混合使用label和位置下标。注意:如果有整数索引,则应该使用.loc/.iloc从而避免混淆
(1)Series
import numpy as np import pandas as pd idx = pd.Index(['a','b','c','d'],name='idx1') s = pd.Series([0,3,5,7],index=idx,name='ser1') s # idx1 a 0 b 3 c 5 d 7 Name: ser1, dtype: int64 print(s.ix[0],s.ix['a':'b'],s.ix[[0,1,2]],s.ix[[True,False,True,False]],sep='\n------\n') # ix混合使用整数下标和label # 0 ------ idx1 a 0 b 3 Name: ser1, dtype: int64 ------ idx1 a 0 b 3 c 5 Name: ser1, dtype: int64 ------ idx1 a 0 c 5 Name: ser1, dtype: int64

(2)DataFrame
df = pd.DataFrame({'c1':[1,2,3,4],'c2':[5,6,7,8],'c3':[9,10,11,12]},index=idx)
df
# c1 c2 c3
idx1
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12
print(df.ix['a'],df.ix['a':'c'],df.ix[[0,2]],df.ix[[True,False,True,False]],sep='\n---------\n')
# 下标为元组,这里第二个元素默认为'':,ix默认使用整数下标和label
# c1 1
c2 5
c3 9
Name: a, dtype: int64
---------
c1 c2 c3
idx1
a 1 5 9
b 2 6 10
c 3 7 11
---------
c1 c2 c3
idx1
a 1 5 9
c 3 7 11
---------
c1 c2 c3
idx1
a 1 5 9
c 3 7 11
print(df.ix[0,'c1'],df.ix['a':'b',0],df.ix[['a','c']],df.ix[[True,False,True,False],[True,False,False]],sep='\n---------\n')
# 下标为元组,第一个为0周,第二个为1轴,ix混合使用整数下标和label
# 1
---------
idx1
a 1
b 2
Name: c1, dtype: int64
---------
c1 c2 c3
idx1
a 1 5 9
c 3 7 11
---------
c1
idx1
a 1
c 3


4.注意
(1)Index对象不能使用loc/iloc/ix存取器
(2)对于.loc/.iloc/.ix:
- 如果某轴的索引为
array-like或者布尔array-like,则返回的结果与原来的对象不再共享基础数据; - 如果轴的索引全部都是
slice或者单个整数、单个label,则返回的结果与原来的对象共享基础数据。
idx = pd.Index(['a','b','c','d'],name='idx1')
df = pd.DataFrame({'c1':[1,2,3,4],'c2':[5,6,7,8],'c3':[9,10,11,12]},index=idx)
df
# c1 c2 c3
idx1
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12
r1 = df.ix[0,0] # 都是整数
r2 = df.loc['a',:] # 一个切片
r3 = df.iloc[:,0] # 一个切片
r4 = df.ix[: , :] # 两个切片
r5 = df.ix[0,[0,1]] # 一个列表
r6 = df.loc[: , ['c1','c2']] # 一个列表
r7 = df.iloc[[0,1],[0,1]] # 两个列表
(type(r1),# 都是整数
r2.values.base is df.values.base, # 一个切片
r3.values.base is df.values.base, # 一个切片
r4.values.base is df.values.base, # 一个切片
r5.values.base is df.values.base, # 一个切片
r6.values.base is df.values.base, # 一个切片
r7.values.base is df.values.base, # 一个切片
)
# (numpy.int64, True, True, True, False, False, False)

三、at/iat 存取器
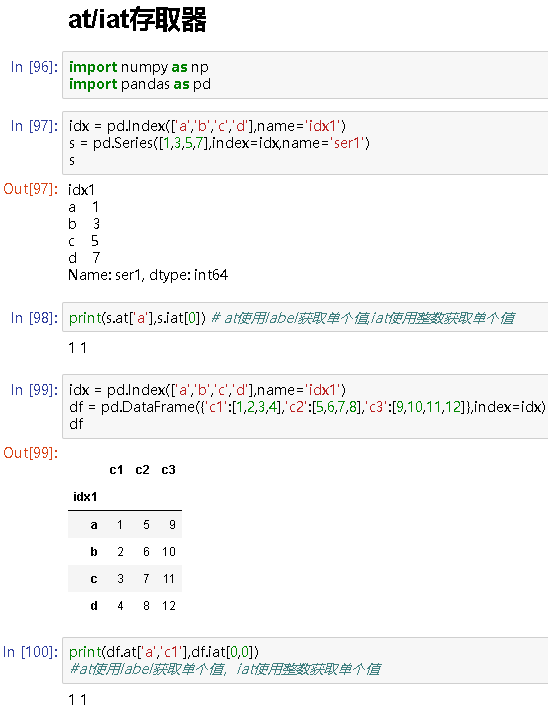
1..at和.iat分别使用label和整数下标获取单个值。它类似于.loc/.iloc,但是.at/.iat的速度更快
- 每个索引只能是单个
label或者单个整数
举例:
import numpy as np
import pandas as pd
idx = pd.Index(['a','b','c','d'],name='idx1')
s = pd.Series([1,3,5,7],index=idx,name='ser1')
s
# idx1
a 1
b 3
c 5
d 7
Name: ser1, dtype: int64
print(s.at['a'],s.iat[0]) # at使用label获取单个值,iat使用整数获取单个值
# 1 1
idx = pd.Index(['a','b','c','d'],name='idx1')
df = pd.DataFrame({'c1':[1,2,3,4],'c2':[5,6,7,8],'c3':[9,10,11,12]},index=idx)
df
# c1 c2 c3
idx1
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12
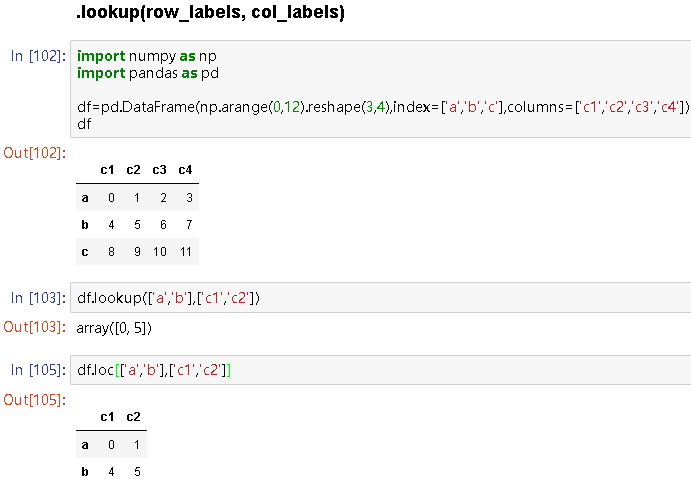
2.对于DataFrame,.lookup(row_labels, col_labels)类似于:.loc[row_labels, col_labels],但是.lookup返回的是一维ndarray。
- 要求
row_labels和col_labels长度相同。(row_labels[0],col_labels[0]决定了结果中第一个元素的位置,...(row_labels[i],col_labels[i]决定了结果中第i+1个元素的位置,
举例:
import numpy as np import pandas as pd df=pd.DataFrame(np.arange(0,12).reshape(3,4),index=['a','b','c'],columns=['c1','c2','c3','c4']) df # c1 c2 c3 c4 a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 df.lookup(['a','b'],['c1','c2']) # array([0, 5]) df.loc[['a','b'],['c1','c2']] # c1 c2 a 0 1 b 4 5
3.DataFrame.get_value(index, col, takeable=False)等价于.loc[index, col],它返回单个值。而Series.get_value(label, takeable=False)等价于.loc[label],它也返回单个值
举例:
import numpy as np
import pandas as pd
idx = pd.Index(['a','b','c','d'],name='idx1')
s = pd.Series([0,1,2,3],index=idx,name='ser1')
s
# idx1
a 0
b 1
c 2
d 3
Name: ser1, dtype: int64
s.get_value('a') # 返回单个值
# 0
idx = pd.Index(['a','b','c','d'],name='idx1')
df = pd.DataFrame({'c1':[1,2,3,4],'c2':[5,6,7,8],'c3':[9,10,11,12]},index=idx)
df
# c1 c2 c3
idx1
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12
df.get_value('a','c2') # 返回单个值
# 5

4..get(key[, default])方法与字典的get()方法的用法相同。对于DataFrame,key为col_label
举例:
import numpy as np
import pandas as pd
idx = pd.Index(['a','b','c','d'],name='idx1')
s = pd.Series([0,1,2,3],index=idx,name='ser1')
s
# idx1
a 0
b 1
c 2
d 3
Name: ser1, dtype: int64
s.get('a'),s.get('e',-1)
# (0, -1)
idx = pd.Index(['a','b','c','d'],name='idx1')
df = pd.DataFrame({'c1':[1,2,3,4],'c2':[5,6,7,8],'c3':[9,10,11,12]},index=idx)
df
# c1 c2 c3
idx1
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12
df.get('c1'),df.get('e',-1)
# (idx1
a 1
b 2
c 3
d 4
Name: c1, dtype: int64, -1)

5..head([n=5])和.tail([n=5])返回头部/尾部n行数据
四、query方法
1.对于DataFrame,当需要根据一定的条件对行进行过滤时,通常可以先创建一个布尔数组,然后使用该数组获取True对应的行。另一个方案就是采用query(expr, inplace=False, **kwargs)方法:
expr是个运算表达式字符串,如'label1 >3 and label2<5'- 表达式中的变量名表示对应的列,可以使用
not/and/or等关键字进行向量布尔运算。该方法会筛选出那些满足条件的行。 - 如果希望在表达式中使用
Python变量,则在变量名之前使用@ inplace是个布尔值,如果为True,则原地修改。否则返回一份拷贝。
举例:
import numpy as np
import pandas as pd
idx = pd.Index(['a','b','c','d'],name='idx1')
df = pd.DataFrame({'c1':[1,2,3,4],'c2':[5,6,7,8],'c3':[9,10,11,12]},index=idx)
df
# c1 c2 c3
idx1
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12
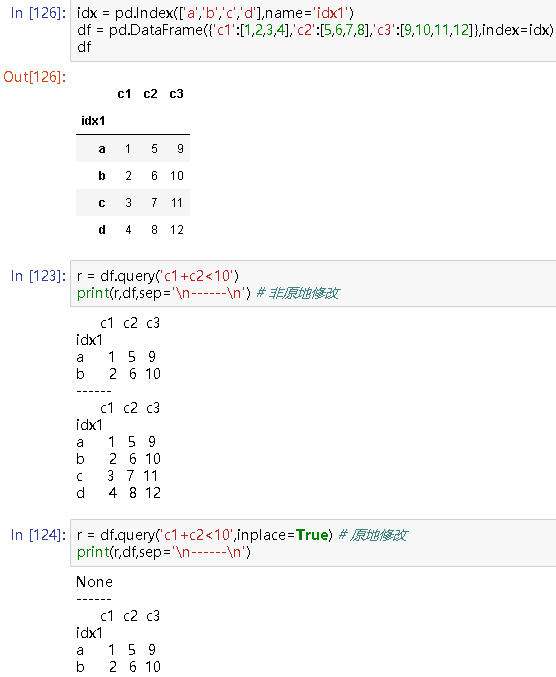
r = df.query('c1+c2<10')
print(r,df,sep='\n------\n') # 非原地修改
# c1 c2 c3
idx1
a 1 5 9
b 2 6 10
------
c1 c2 c3
idx1
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12
r = df.query('c1+c2<10',inplace=True) # 原地修改
print(r,df,sep='\n------\n')
# None
------
c1 c2 c3
idx1
a 1 5 9
b 2 6 10
c1 = 3
df.query('c1==@c1') # 使用python变量
# c1 c2 c3
idx1
c 3 7 11

五、多级索引
1.对于.loc/.ix/[],其下标可以指定多级索引中,每级索引上的标签。
- 多级索引轴对应的下标是一个下标元组,该元组中每个元素与索引中每级索引对应
- 如果下标不是元组,则将其转换成长度为1的元组
- 如果元组的长度比索引的层数少,则在其后面补充
slice(None)
举例:
import numpy as np
import pandas as pd
levels = [['a','b'],['c','d']]
labels = [[0,1,0,1],[0,0,1,1]]
idx = pd.MultiIndex(levels=levels,labels=labels,names=['lv1','lv2'])
s = pd.Series([1,2,3,4],index=idx,name='ser1')
s
# lv1 lv2
a c 1
b c 2
a d 3
b d 4
Name: ser1, dtype: int64
s.ix[(0,0)],s.loc[('a','c')] # 下标索引为元组
# (1, 1)
df = pd.DataFrame({'c1':[1,2,3,4],'c2':[5,6,7,8],'c3':[9,10,11,12]},index=idx)
df
# c1 c2 c3
lv1 lv2
a c 1 5 9
b c 2 6 10
a d 3 7 11
b d 4 8 12
print(df.loc['a',['c1','c2']],df.loc[('a',slice(None)),['c1','c2']],sep='\n----------\n')
# 二者等价
# c1 c2
lv2
c 1 5
d 3 7
----------
c1 c2
lv1 lv2
a c 1 5
d 3 7
df.loc[(slice(None),'c'),['c1','c2']] # 0轴的level为:
# c1 c2
lv1 lv2
a c 1 5
b c 2 6
print(s['a'],s[:,'c'],s['a','c'],sep='\n-------------------------\n')#使用[]索引
# lv2
c 1
d 3
Name: ser1, dtype: int64
-------------------------
lv1
a 1
b 2
Name: ser1, dtype: int64
-------------------------
1



六、整数 label
1.label不一定是字符串,也有可能是整数(如RangeIndex/Int64Index等),尤其是当label是自动生成的时候。
当你的label是整数时,面向整数的下标索引总是面向label的,而不是面向position的。因此推荐使用.loc来基于label索引,使用.iloc来基于position索引。
举例:
import numpy as np
import pandas as pd
s1 = pd.Series([11,12,15,17]) # 自动生成index
s2 = pd.Series([21,22,25,27],index=[1,3,5,7]) # 整数index
s3 = pd.Series([31,32,35,37],index=['a','b','c','d'])#字符串index
print(s1,s2,s3,sep='\n------------------------\n')
0 11
1 12
2 15
3 17
dtype: int64
------------------------
1 21
3 22
5 25
7 27
dtype: int64
------------------------
a 31
b 32
c 35
d 37
dtype: int64
\n------------------------\n
print(s1.index,type(s1.index),
s2.index,type(s2.index),
s3.index,type(s3.index),sep='\n------------------------\n')
RangeIndex(start=0, stop=4, step=1)
------------------------
<class 'pandas.core.indexes.range.RangeIndex'>
------------------------
Int64Index([1, 3, 5, 7], dtype='int64')
------------------------
<class 'pandas.core.indexes.numeric.Int64Index'>
------------------------
Index(['a', 'b', 'c', 'd'], dtype='object')
------------------------
<class 'pandas.core.indexes.base.Index'>
# 面向position
print(s2[7], # 面向label
s3[0]) # 面向position
27 31
#面向position
print(s2.loc[7],#面向label
s2.iloc[-1],#面向position
s3.loc['d'],#面向label
s3.iloc[-1] #面向position
)
27 27 37 37



 浙公网安备 33010602011771号
浙公网安备 33010602011771号