
8.7 超参数调优
在机器学习中非常重要的任务就是模型选择,或者使用数据来找到具体问题的最佳的模型和参数,这个过程也叫做调试(Tuning)。
调试可以在独立的估计器中完成(如逻辑斯蒂回归),也可以在包含多样算法、特征工程和其他步骤的工作流中完成。用户应该一次性调优整个工作流,而不是独立的调整PipeLine中的每个组成部分。
MLlib支持交叉验证(CrossValidator)和训练验证分割(TrainValidationSplit)两个模型选择工具。
- 估计器:待调试的算法或管线。
- 一系列参数表(ParamMaps):可选参数,也叫做“参数网格”搜索空间。
- 评估器:评估模型拟合程度的准则或方法。
模型选择工具工作原理如下:
- 将输入数据划分为训练数据和测试数据。
- 对于每个(训练,测试)对,遍历一组ParamMaps。用每一个ParamMap参数来拟合估计器,得到训练后的模型,再使用评估器来评估模型表现。
- 选择性能表现最优模型对应参数表。
交叉验证CrossValidator将数据集切分成k折叠数据集合,并被分别用于训练和测试。
- 例如,k=3时,CrossValidator会生成3个(训练数据,测试数据)对,每一个数据对的训练数据占2/3,测试数据占1/3。 为了评估一个ParamMap,CrossValidator 会计算这3个不同的(训练,测试)数据集对在Estimator拟合出的模型上的平均评估指标。
在找出最好的ParamMap后,CrossValidator 会使用这个ParamMap和整个的数据集来重新拟合Estimator。
- 也就是说通过交叉验证找到最佳的ParamMap,利用此ParamMap在整个训练集上可以训练(fit)出一个泛化能力强,误差相对小的的最佳模型。
交叉验证的代价比较高昂,为此Spark也为超参数调优提供了训练-验证切分TrainValidationSplit。TrainValidationSplit创建单一的(训练,测试)数据集对。它使用trainRatio参数将数据集切分成两部分。
- 例如,当设置trainRatio=0.75时,TrainValidationSplit将会将数据切分75%作为数据集,25%作为验证集,来生成训练、测试集对,并最终使用最好的ParamMap和完整的数据集来拟合评估器。
- 相对于CrossValidator对每一个参数进行k次评估,TrainValidationSplit只对每个参数组合评估1次。因此它的评估代价没有这么高,但是当训练数据集不够大的时候其结果相对不够可信。
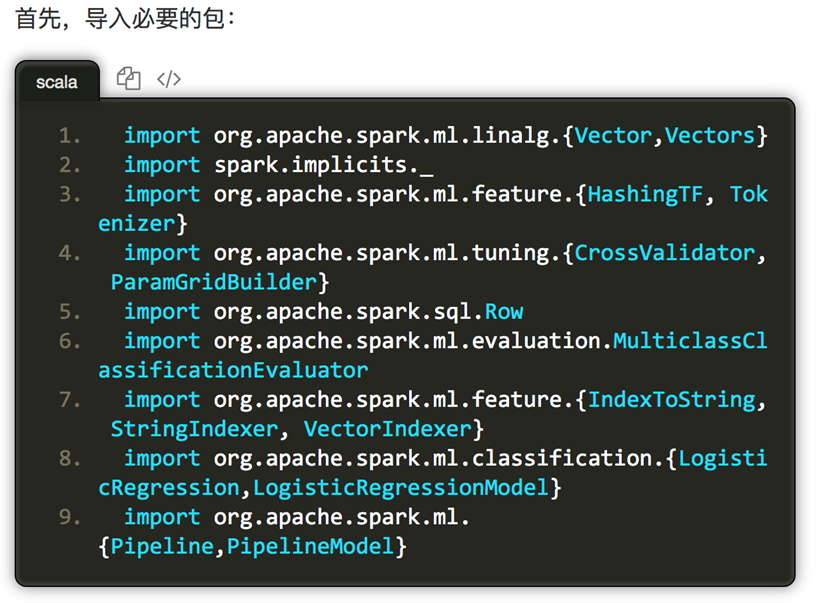
读取Irisi数据集,分别获取标签列和特征列,进行索引、重命名,并设置机器学习工作流。
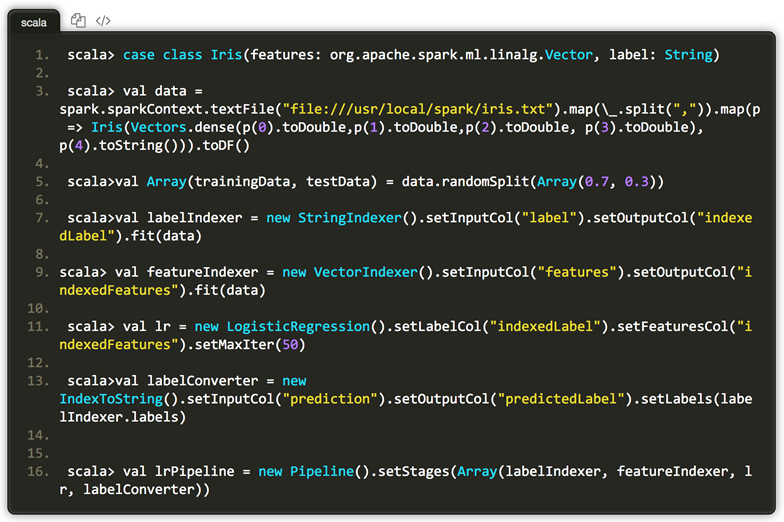
使用ParamGridBuilder方便构造参数网格。
其中regParam参数定义规范化项的权重;elasticNetParam是Elastic net 参数,取值介于0和1之间。elasticNetParam设置2个值,regParam设置3个值。最终将有(3 * 2) = 6个不同的模型将被训练。
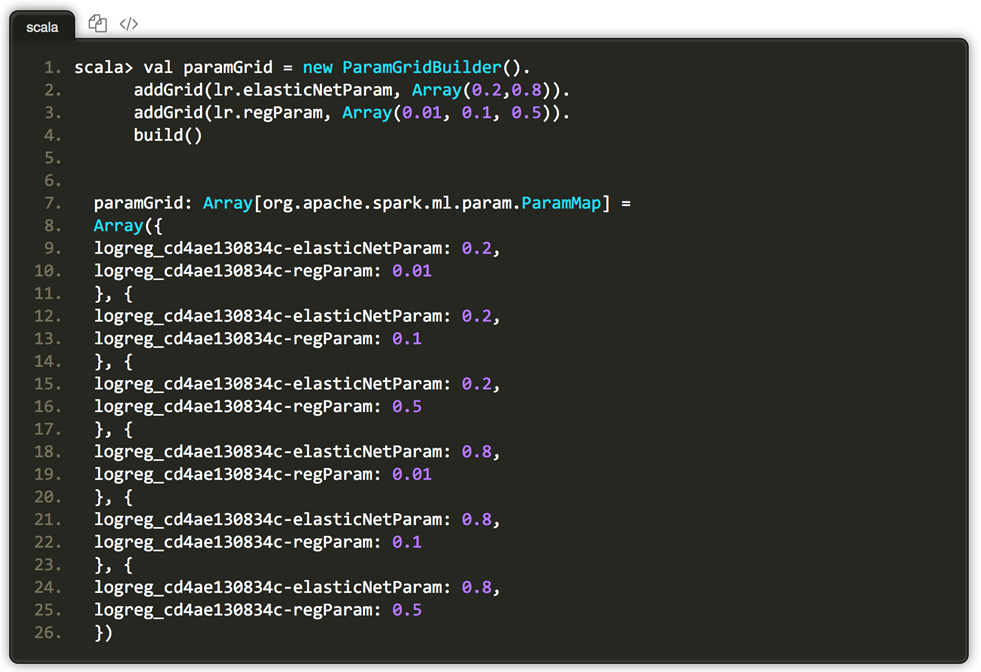
再接下来,构建针对整个机器学习工作流的交叉验证类,定义验证模型、参数网格,以及数据集的折叠数,并调用fit方法进行模型训练。
其中,对于回归问题评估器可选择RegressionEvaluator,二值数据可选择BinaryClassificationEvaluator,多分类问题可选择MulticlassClassificationEvaluator。评估器里默认的评估准则可通过setMetricName方法重写。

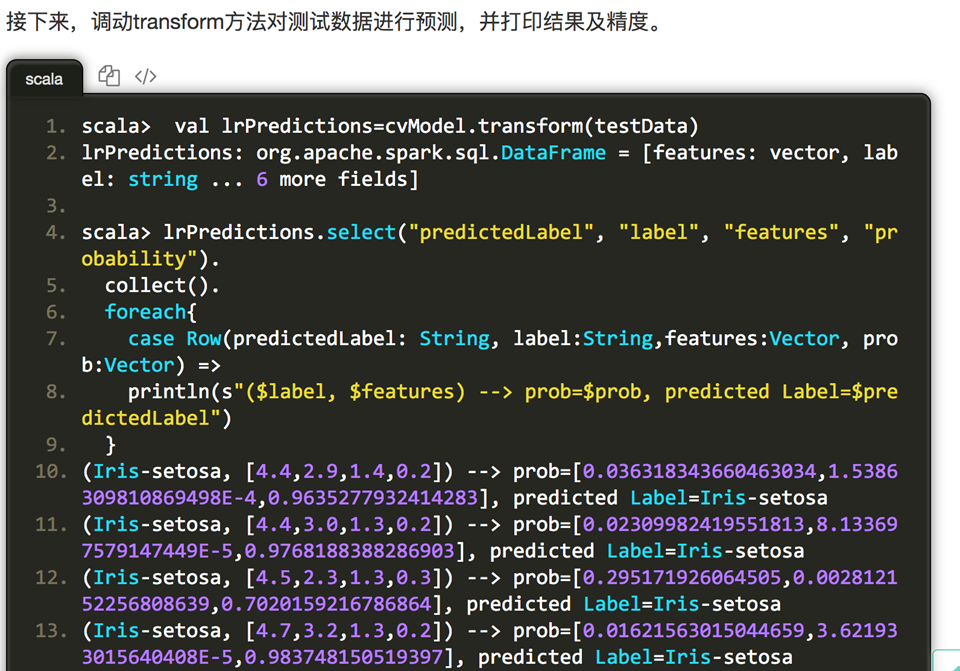
还可以获取最优的逻辑斯蒂回归模型,并查看其具体的参数.对于参数网格,其最优参数取值是regParam=0.01,elasticNetParam=0.2。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现