
6.1 Spark SQL
一、从shark到Spark SQL
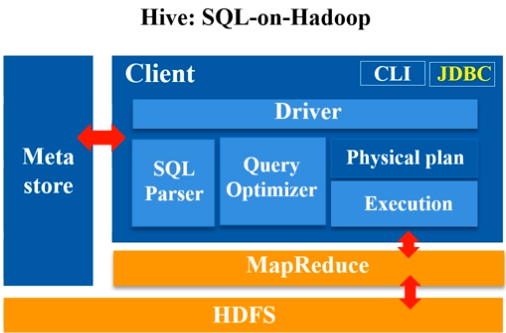
Hive能够把SQL程序转换成map-reduce程序
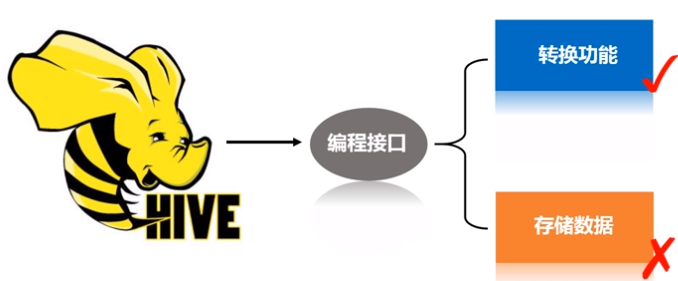
可以把Hadoop中的Hive看作是一个接口,主要起到了转换的功能,并没有实际存储数据。

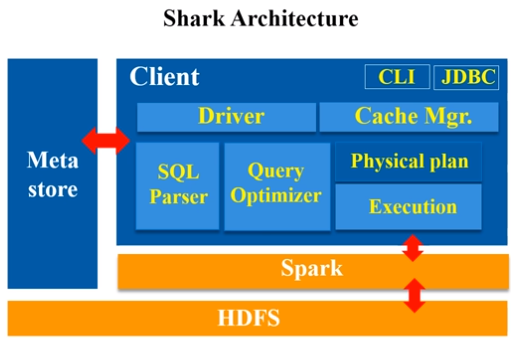
Shark即Hive on Spark,为了实现与Hive兼容,Shark在HiveQL方面重用了Hive中HiveQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MapReduce作业替换成了Spark作业,通过Hive的HiveQL解析,把HiveQL翻译成Spark上的RDD操作(shark相当于是hive的引进版,它把hive里的各种模块,基本上一五一十地照搬过来,就做了一个最底层的修改,hive是从最底层转成MapReduce程序,而到了shark,它的其他模块都没变,就把最底层翻译成spark应用程序。)
 、
、
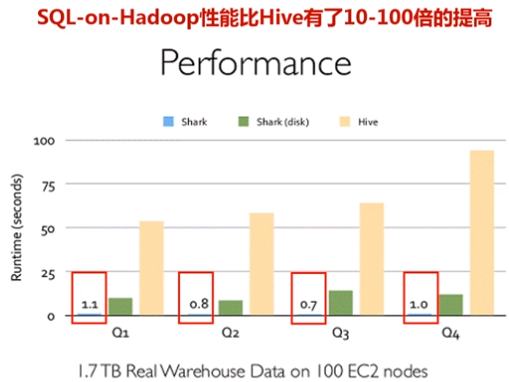
Shark的出现,使得SQL-on-Hadoop的性能比Hive有了10-100倍的提高
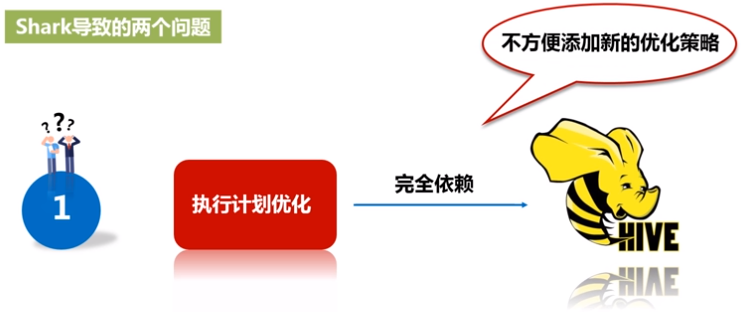
因为shark是基于hive修改的,会带来两个问题:
1)执行计划优化完全依赖于Hive,不方便添加新的优化策略;
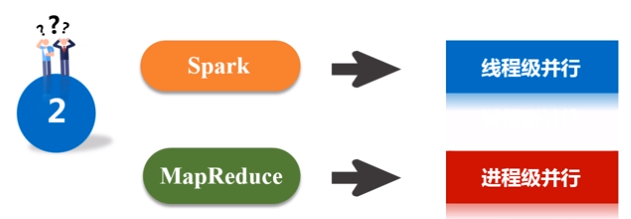
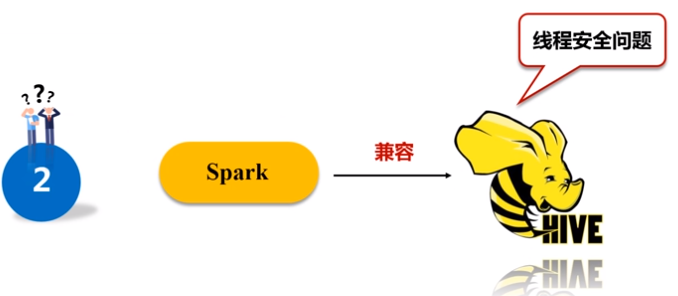
2)spark是线程级并行,MapReduce是进程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的打了补丁的Hive源码分支
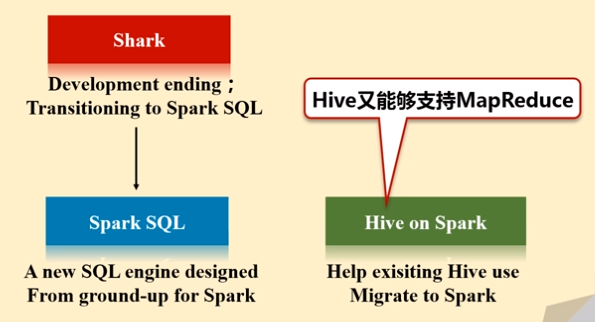
2014年6月1日Shark项目和SparkSQL项目的主持人Reynold Xin宣布:停止对Shark的开发,团队将所有资源放SparkSQL项目上,至此,Shark的发展画上了句话,但也因此发展出两个直线:SparkSQL和Hive on Spark
- Spark SQL作为Spark生态的一员继续发展,而不再受限于Hive,只是兼容Hive
- Hive on Spark是一个Hive的发展计划,该计划将Spark作为Hive的底层引擎之一,也就是说,Hive将不再受限于一个引擎,可以采用Map-Reduce、Tez、Spark等引擎
二、Spark SQL设计
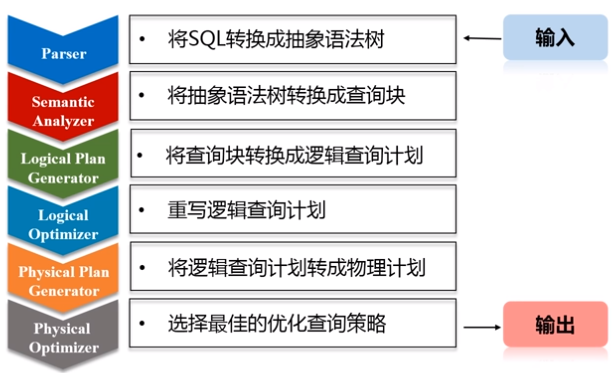
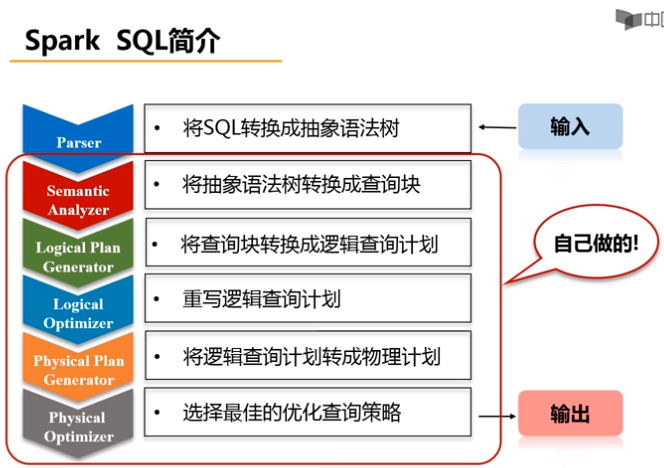
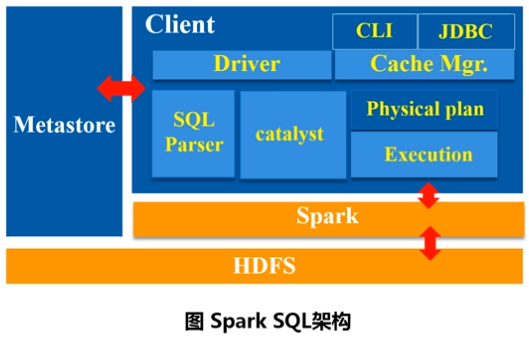
Spark SQL在Hive兼容层面仅依赖HiveQL解析、Hive元数据,也就是说,从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责。(Spark SQL除了沿用Parser(把SQL转换成抽象语法树)这一个模块外,其他模块全部自己定义。)


三、为什么推出Spark SQL

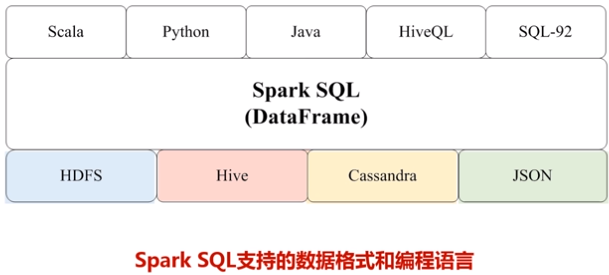
(1)关系型数据库中只存储了一部分的结构化数据,但是实际上现在要处理的相关数据类型不仅仅包括关系数据库,现在大数据时代90%的数据都是非结构化数据和半结构化数据,对于这种数据,不能用SQL语句分析。而spark SQL同时支持非结构化、半结构化、结构化数据分析。


(2)关系型数据库没有办法处理类似机器学习和图像处理的图结构数据
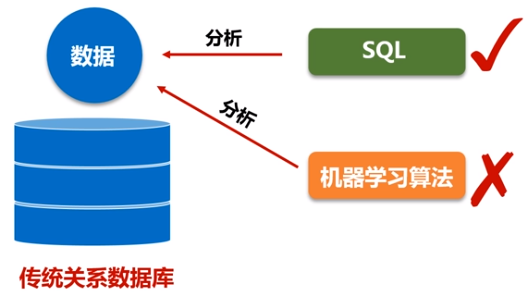
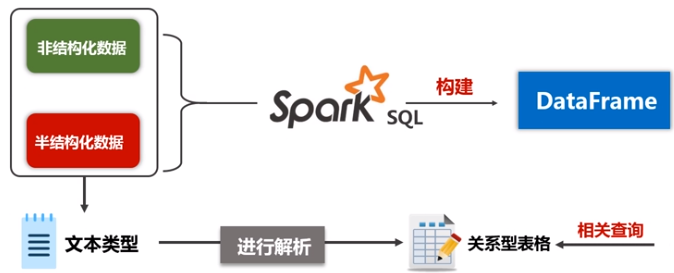
Spark SQL可以有效地把关系数据查询和复杂分析算法融合。

参考文献:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现