
Transformer模型---encoder
一、简介
论文:《Attention is all you need》
作者:Google团队(2017年发表在NIPS上)
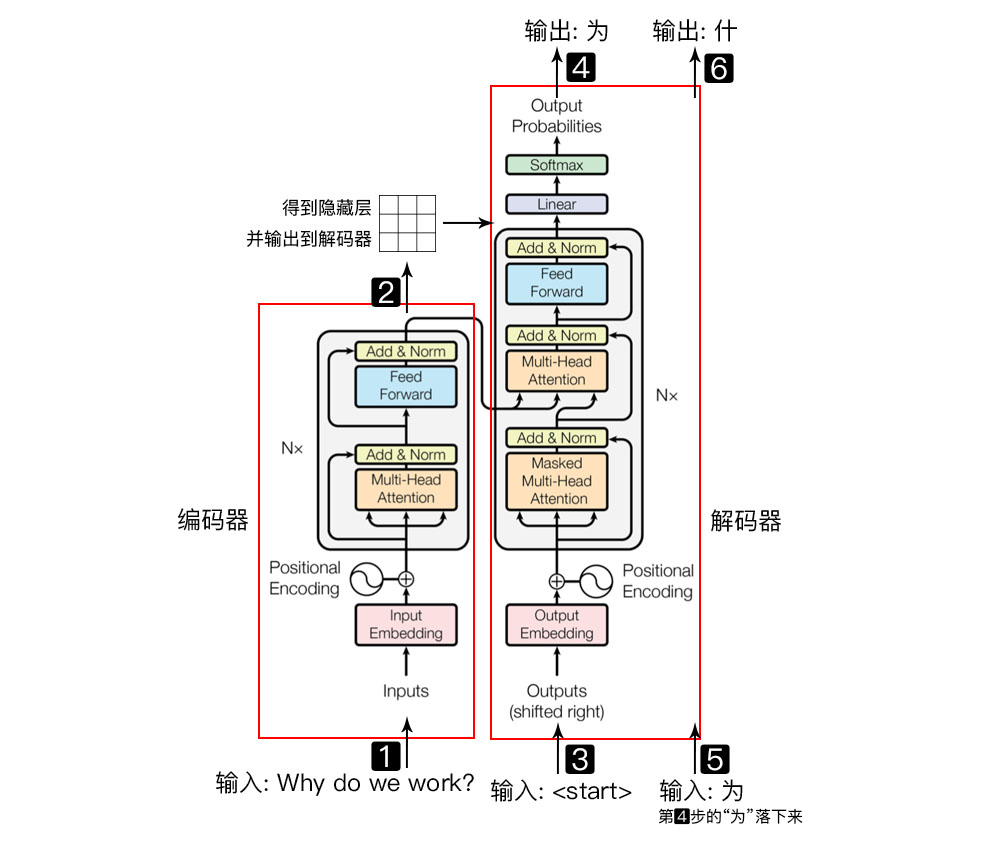
简介:Transformer 是一种新的、基于 attention 机制来实现的特征提取器,可用于代替 CNN 和 RNN 来提取序列的特征。 在该论文中 Transformer 用于 encoder - decoder 架构。事实上 Transformer 可以单独应用于 encoder 或者单独应用于 decoder 。
|
|
|
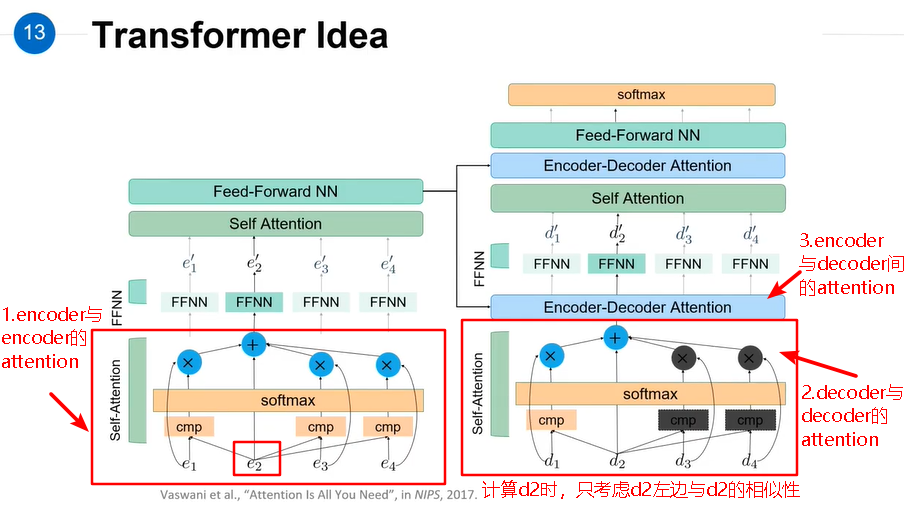 |
Transformer相比较LSTM等循环神经网络模型的优点:
- 可以直接捕获序列中的长距离依赖关系;
- 模型并行度高,使得训练时间大幅度降低。
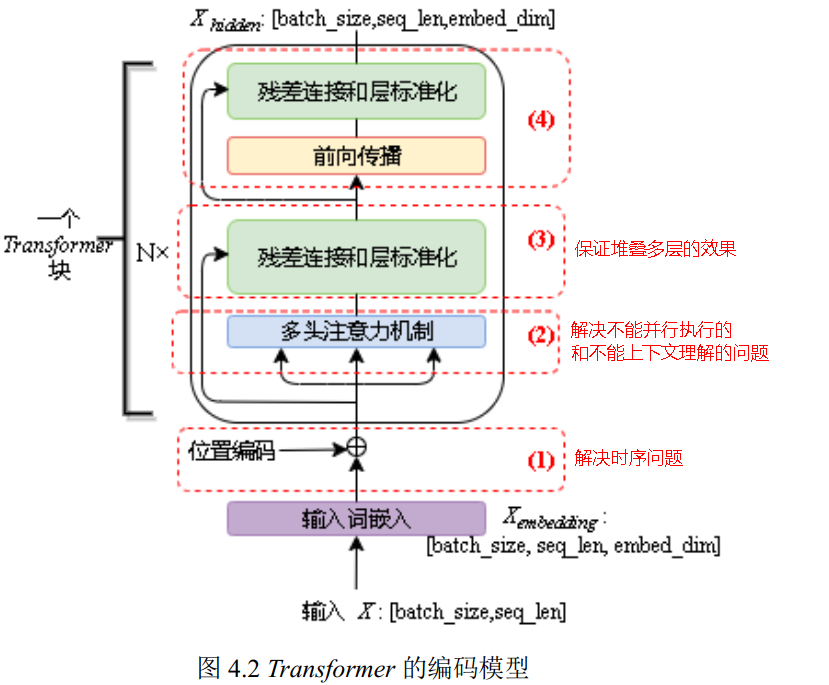
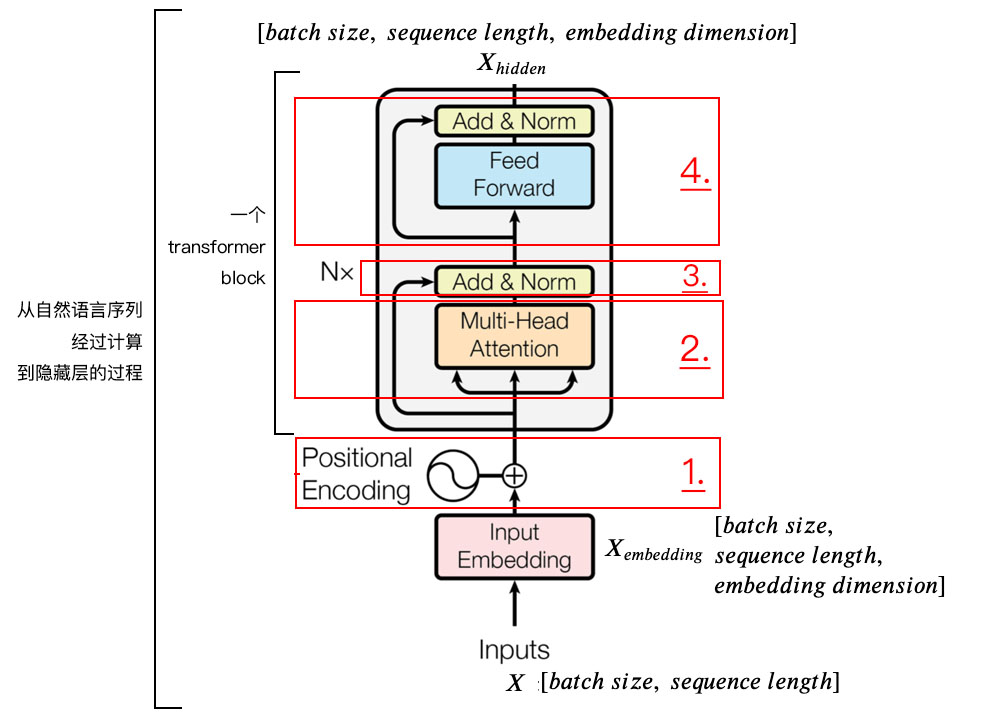
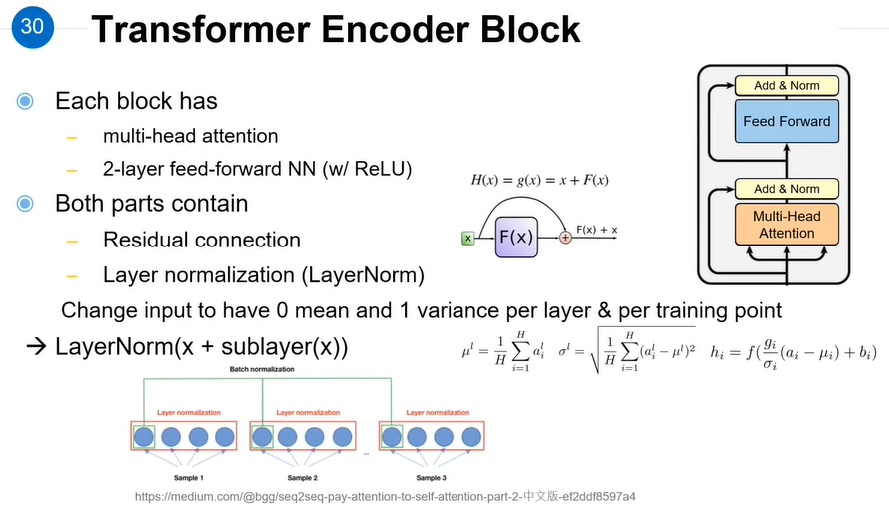
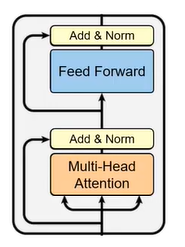
二、编码器
|
|
1) 字向量与位置编码 |
| 2) 自注意力机制 |
|
| 3) 残差连接与Layer Normalization |
|
| 4) , 其实就是两层线性映射并用激活函数激活, 比如说: |
|
| 5) 重复3): |
1.positional encoding
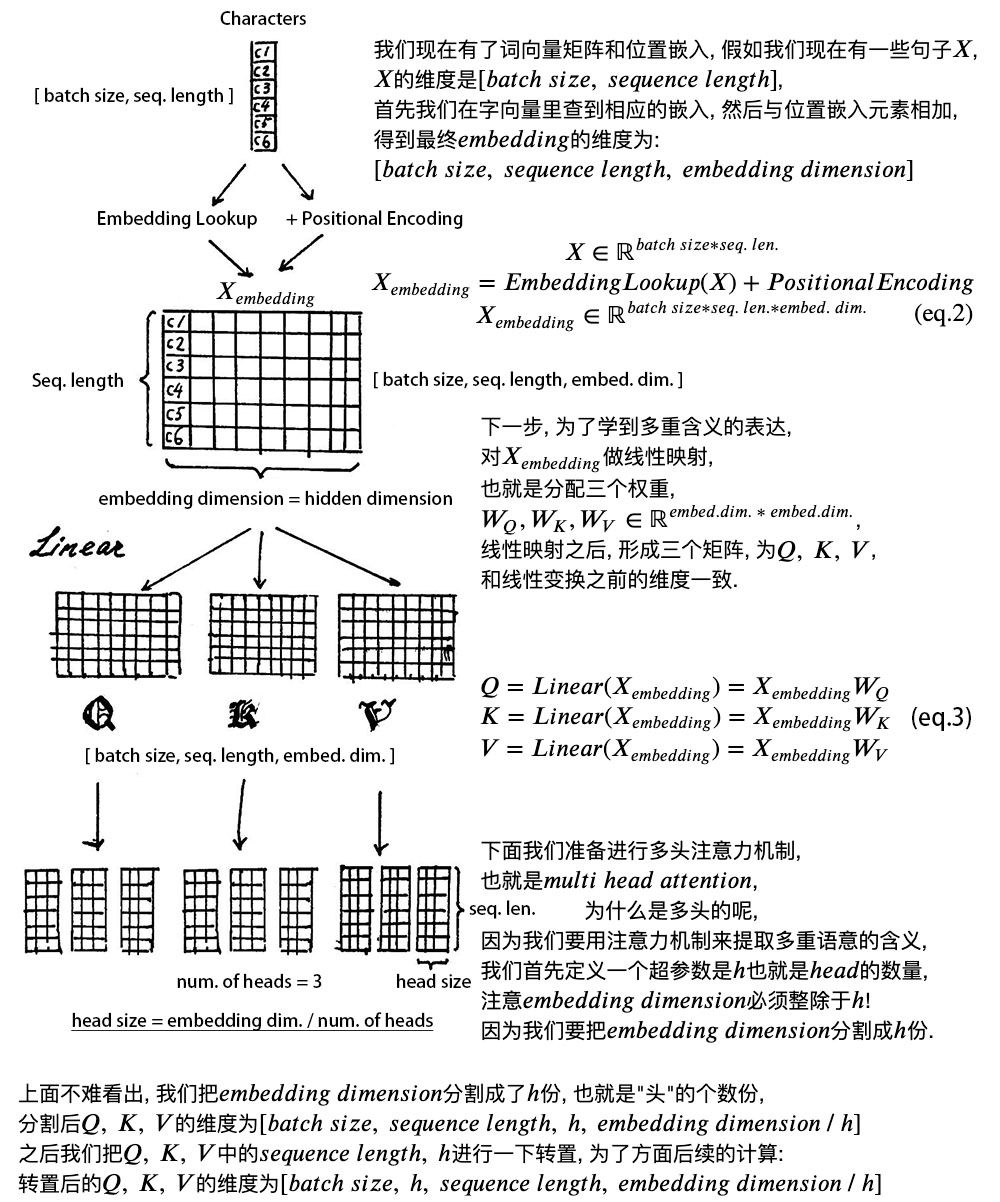
由于transformer模型没有循环神经网络的迭代操作,所以我们必须提供每个字的位置信息给transformer,才能识别出语言中的顺序关系。
|
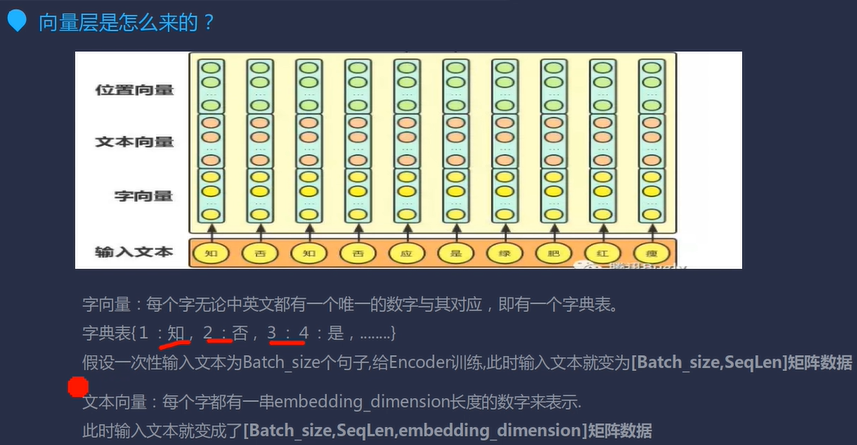
(1)字向量 每个字无论中英文都有一个唯一的数字与其对应,即有一个字典表。 字典表:{1:知,2:否,3:应,...}
|
|
|
(2)文本向量 假设一次性输入文本为batch_size个句子,给encoder训练,此时输入文本就变为[batch_size,seq_len]矩阵数据。 文本向量:每个字都有一串embed_dim长度的数字来表示。 |
|
|
(3)位置向量positional encoding
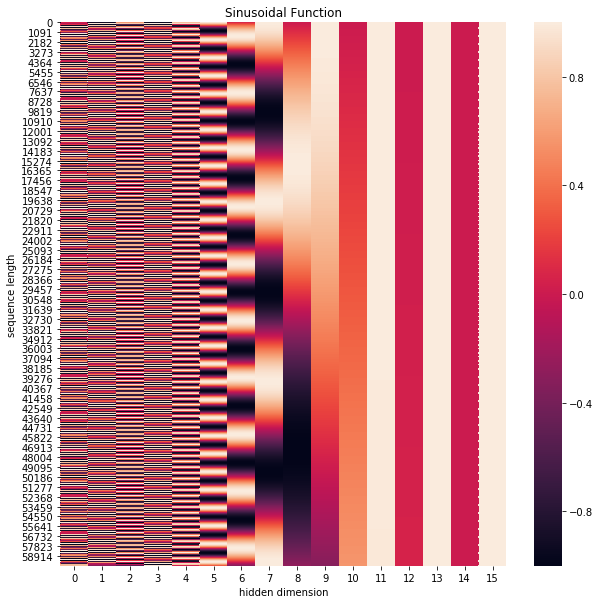
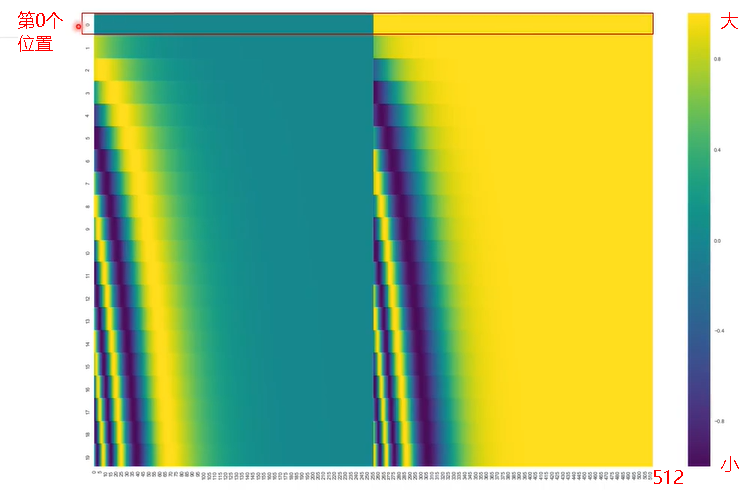
位置向量的维度为[max_seq_len,embed_dim],max_seq_len属于超参数, 指的是限定的最大单个句长。 下面画一下位置嵌入, 可见纵向观察, 随着embed_dim增大, 位置嵌入函数呈现不同的周期变化。
注意力矩阵的三维图如下:
论文中使用了和函数的线性变换来提供给模型位置信息:
上面有和一组公式, 也就是对应着embed_dim维度的一组奇数和偶数的序号的维度, 例如一组,一组, 分别用上面的和函数做处理,从而产生不同的周期性变化,而位置嵌入在embed_dim维度上随着维度序号增大,周期变化会越来越慢,而产生一种包含位置信息的纹理,就像Transformer论文原文第六页讲的,位置嵌入函数的周期从到变化,而每一个位置在embed_dim维度上都会得到不同周期的和函数的取值组合,从而产生独一的纹理位置信息,模型从而学到位置之间的依赖关系和自然语言的时序特性。 相对位置编码与绝对位置编码:
|
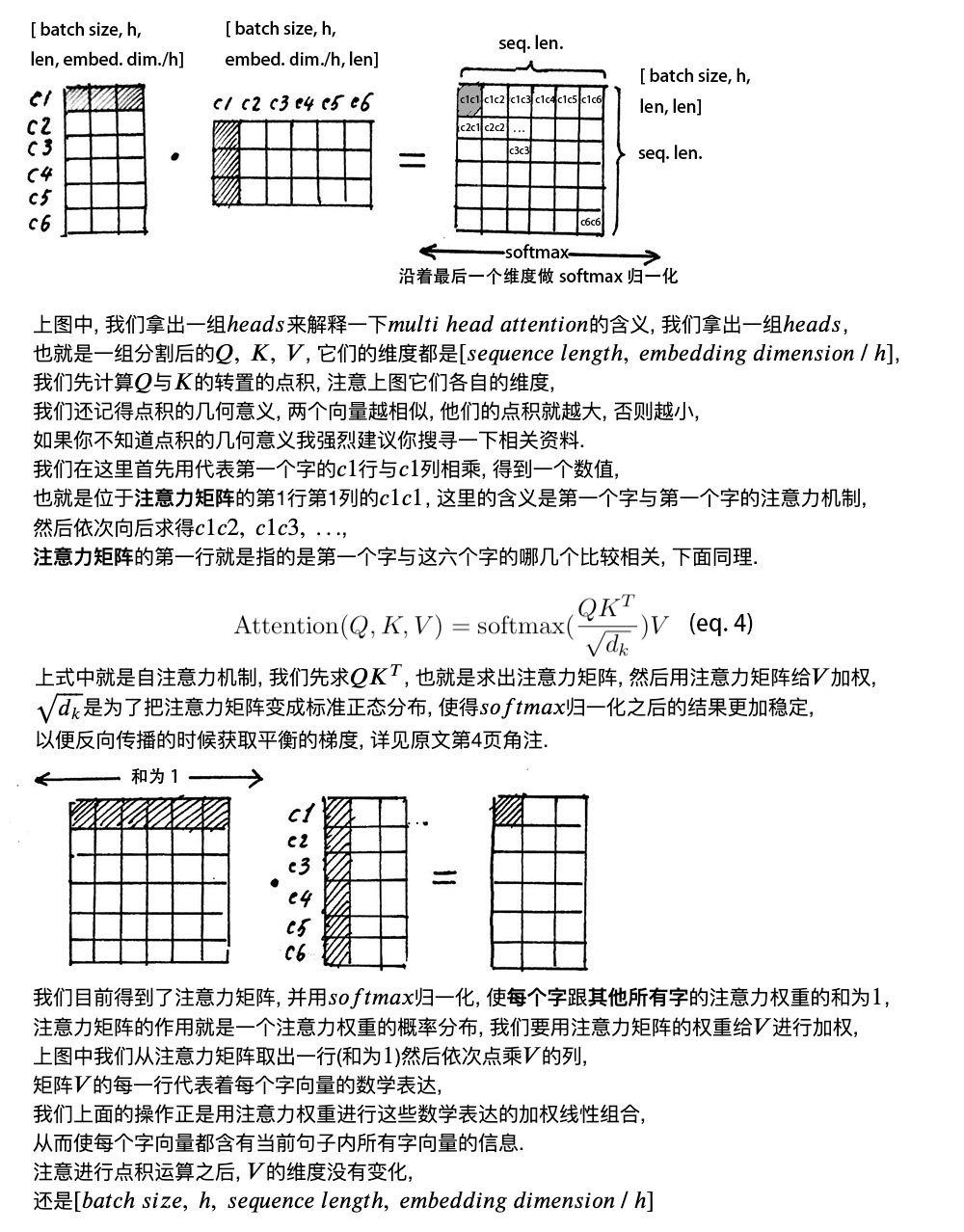
2. self-attention mechanism
(1)为什么用self-attention?

(2)什么是self-attention?
| 1.Encoder |
|
 |
|
| 2.Decoder |  |
|
|
|
| 3.Encoder-Decoder | 
|


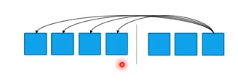
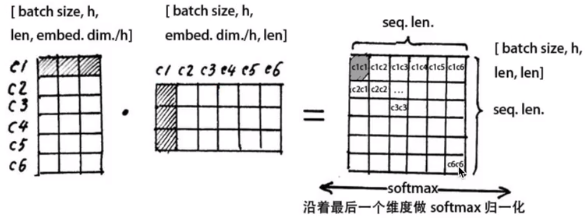
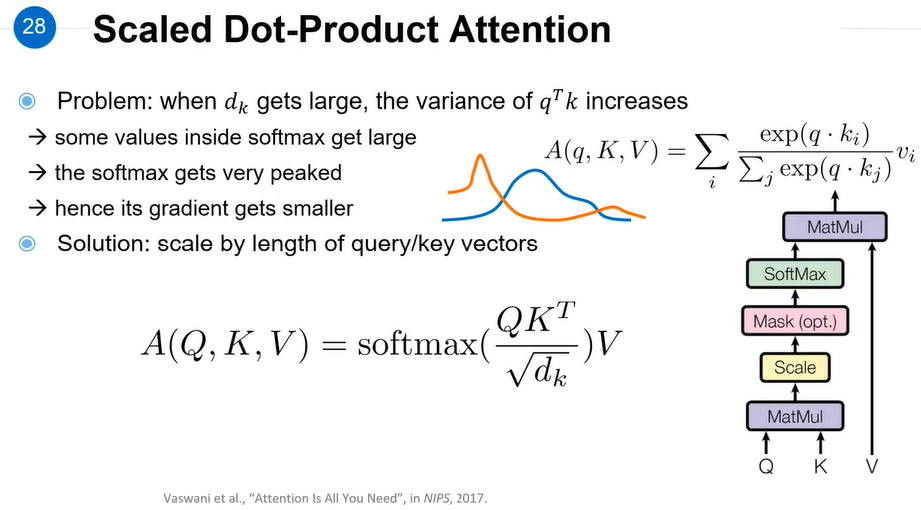
(3)怎么计算self-attention?
Attention Mask
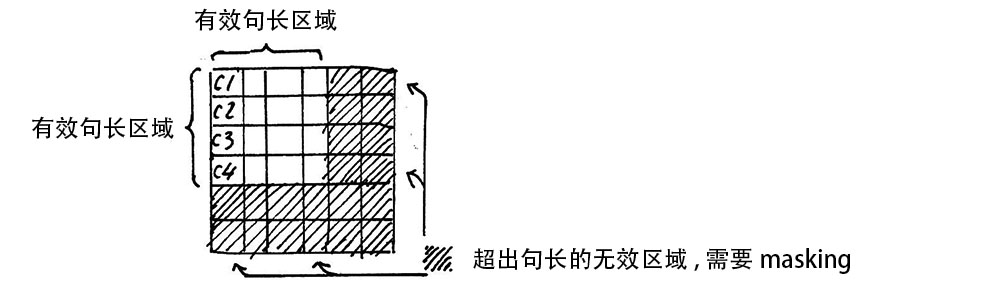
注意, 在上面self attention的计算过程中, 我们通常使用mini batch来计算, 也就是一次计算多句话, 也就是X的维度是[batch_size, seq_len], seq_len是句长, 而一个mini batch是由多个不等长的句子组成的, 我们就需要按照这个mini batch中最大的句长对剩余的句子进行补齐长度, 我们一般用0来进行填充, 这个过程叫做padding。
但这时在进行softmax的时候就会产生问题, 回顾softmax函数, 是1, 是有值的, 这样的话softmax中被padding的部分就参与了运算, 就等于是让无效的部分参与了运算, 会产生很大隐患, 这时就需要做一个mask让这些无效区域不参与运算, 我们一般给无效区域加一个很大的负数的偏置, 也就是:
经过上式的masking我们使无效区域经过softmax计算之后还几乎为0, 这样就避免了无效区域参与计算。
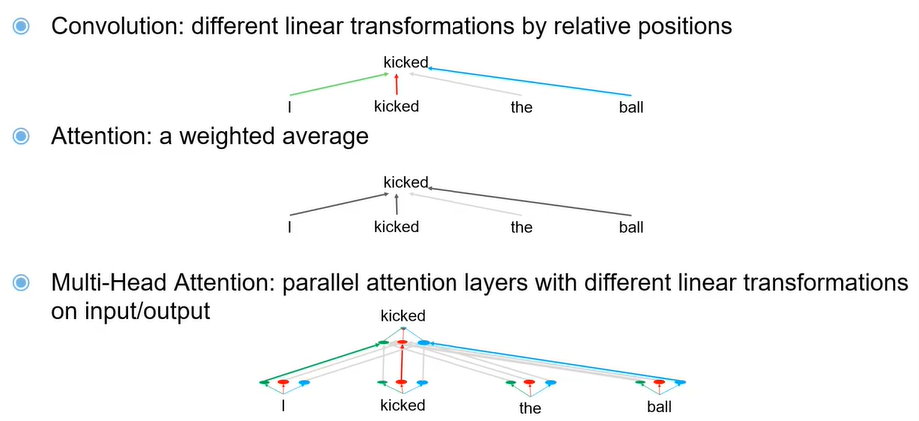
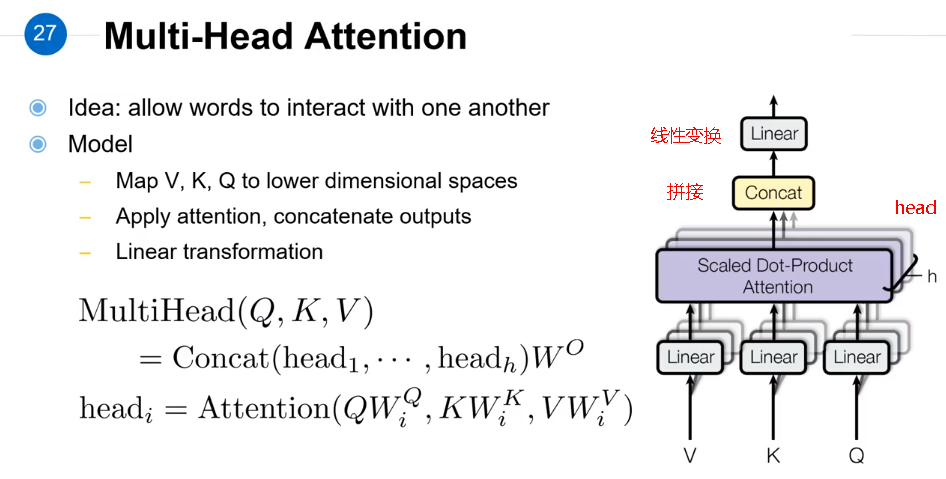
(4)多头自注意力机制
综合CNN和self-attention,考虑不同类型的关系。
3. 残差连接和层标准化
|
(1)残差连接residual connection 我们在上一步得到了经过注意力矩阵加权之后的, 也就是, 我们对它进行一下转置, 使其和的维度一致, 也就是[batch_size, seq_len, embed_dim], 然后把他们加起来做残差连接, 直接进行元素相加, 因为他们的维度一致: |
|
|
(2)层标准化layer normalization 的作用是把神经网络中隐藏层归一为标准正态分布, 也就是独立同分布, 以起到加快训练速度, 加速收敛的作用: |
4. 训练tips

5.总结

参考文献:
【1】大师级的a_journey_into_math_of_ml / 04_transformer_tutorial_2nd_part·浓缩咖啡/浓咖啡/ a_journey_into_math_of_ml
【2】The Illustrated Transformer(可视化讲解)
【3】The Annotated Transformer(代码讲解)
【5】台大《应用深度学习》国语课程(2020) by 陈蕴侬
【6】带注释的变压器


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现