
29.聚类---性能度量
一、性能度量
聚类的性能度量也称作聚类的有效性指标。
聚类的性能度量分两类:
- 聚类结果与某个参考模型进行比较,称作外部指标;
- 直接考察聚类结果而不利用任何参考模型,称作内部指标。
1. 外部指标
对于数据集,假定通过聚类给出的簇划分为,参考模型给出的簇划分为,其中和不一定相等。
令分别表示的簇标记向量。定义:
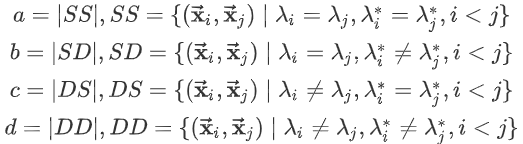
其中|·|表示集合的元素的个数,各集合的意义为:
- :包含了同时隶属于的样本对;
- :包含了隶属于,但是不隶属于的样本对;
- :包含了不隶属于,但是隶属于的样本对;
- :包含了同时不隶属于的样本对;
由于每个样本对,仅能出现在一个集合中,因此有
下面性能度量的结果都在[0,1]之间,这些值越大,说明聚类的性能越好。
1.1 Jaccard系数
Jaccard系数Jaccard Coefficient:
它刻画了所有的同类的样本对(要么在C中属于同类,要么在C*中属于同类)中,同时隶属于的样本对的比例。
1.2 FM指数
FM指数Fowlkes and Mallows Index:
它刻画的是:
- 在中同类的样本对中,同时隶属于的样本对的比例为
- 在中同类的样本对中,同时隶属于的样本对的比例为
- FMI就是和的几何平均。
1.3 Rand指数
Rand指数Rand Index:
它刻画的是:
- 同时隶属于的同类样本对(这种样本对属于同一个簇的概率最大)与既不隶属于、又不隶属于的非同类样本对(这种样本对不是同一个簇的概率最大)之和,占所有样本对的比例。
- 这个比例其实就是聚类的可靠程度的度量。
1.4 ARI指数
使用RI有关问题:对于随机聚类,RI指数不保证接近0(可能还很大)。
ARI指数就通过利用随机聚类来解决这个问题。
定义一致性矩阵为:

其中:
- 为属于簇的样本的数量,为属于簇的样本的数量。
- 为同时属于簇和簇的样本的数量。
则根据定义有:,其中表示组合数,数字2是因为需要提取两个样本组成样本对。
定义ARI指数Adjusted Rand Index:

- 随机挑选一对样本,一共有种情形。
- 这对样本隶属于中的同一个簇,一共有种可能。
- 这对样本隶属于中的同一个簇,一共有种可能。
- 这对样本隶属于中的同一个簇、且属于中的同一个簇,一共有种可能。
- 则在随机划分的情况下,同时隶属于的样本对的期望为:
2. 内部指标
对于数据集,假定通过聚类给出的簇划分为
定义:

其中,表示两点之间的距离;表示簇的中心点,表示簇的中心点,表示簇的中心点之间的距离。
2.1 DB指数
DB指数Davies-Bouldin Index:
其物理意义为:
- 给定两个簇,每个簇样本距离均值之和比上两个簇的中心点之间的距离作为度量。该度量越小越好。
- 给定一个簇k,遍历其他的簇,寻找该度量的最大值。
- 对所有的簇,取其最大度量的均值。
DBI越小越好,
- 如果每个簇样本距离均值越小(即簇内样本距离都很近),则DBI越小。
- 如果簇间中心点的距离越大(即簇间样本距离相互都很远),则DBI越小。
2.2 Dunn指数
Dunn指数Dunn Index:
其物理意义为:任意两个簇之间最近的距离的最小值,除以任意一个簇内距离最远的两个点的距离的最大值。
DI越大越好,
- 如果任意两个簇之间最近的距离的最小值越大(即簇间样本距离相互都很远),则DI越大。
- 如果任意一个簇内距离最远的两个点的距离的最大值越小(即簇内样本距离都很近),则DI越大。
3. 距离度量
3.1 闵可夫斯基距离Minkowski distance
给定样本,,则闵可夫斯基距离定义为:
- 当时,闵可夫斯基距离就是欧式距离Euclidean distance:
- 当时,闵可夫斯基距离就是曼哈顿距离Euclidean distance:
3.2 VDM距离 value Difference Metric
考虑非数值类属性(如属性取值为:中国,印度,美国,英国),令表示的样本数;表示且位于簇中的样本的数量。则在属性上的两个取值之间的VDM距离为:
该距离刻画的是:属性取值在各簇上的频率分布之间的差异。
3.3 混合距离
当样本的属性为数值属性与非数值属性混合时,可以将闵可夫斯基距离与VDM距离混合使用。
假设属性为数值属性,属性为非数值属性。则:
3.4 加权距离
当样本空间中不同属性的重要性不同时,可以采用加权距离。以加权闵可夫斯基距离为例:
这里的距离度量满足三角不等式:
【注意】余弦距离不是一个严格定义的距离,其满足正定性,对称性,但是不满足三角不等式。余弦相似度在高维的情况下依然保持“相同时为1,正交时为0,相反时为-1”的性质。欧式距离的数值受维度的影响,范围不固定,并且含义也比较模糊。欧式距离体现数值上的绝对差异,而余弦距离体现方向上的相对差异。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现
2018-11-22 神经网络的调参顺序
2018-11-22 3.keras实现-->高级的深度学习最佳实践
2018-11-22 在Keras模型中one-hot编码,Embedding层,使用预训练的词向量/处理图片