
5.4 RDD编程---综合案例
undefined
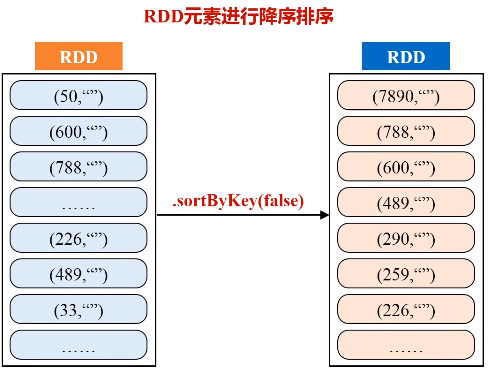
一、求top值
任务描述:求出多个文件中数值的最大、最小值



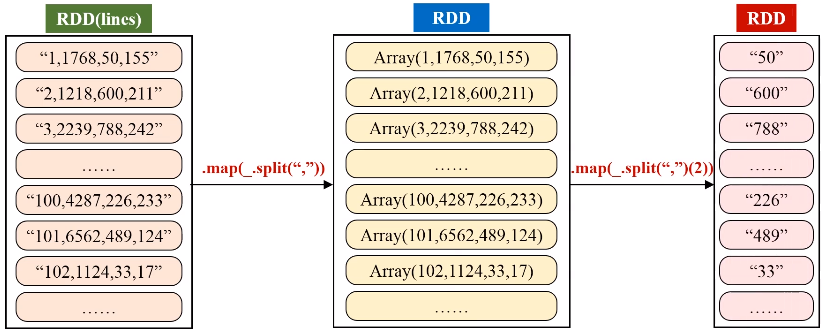
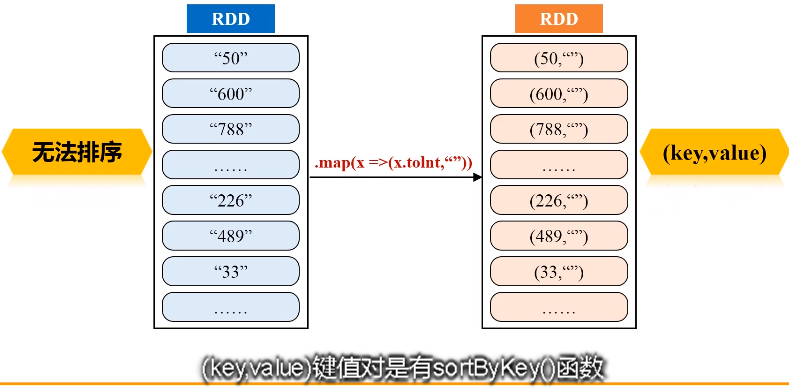
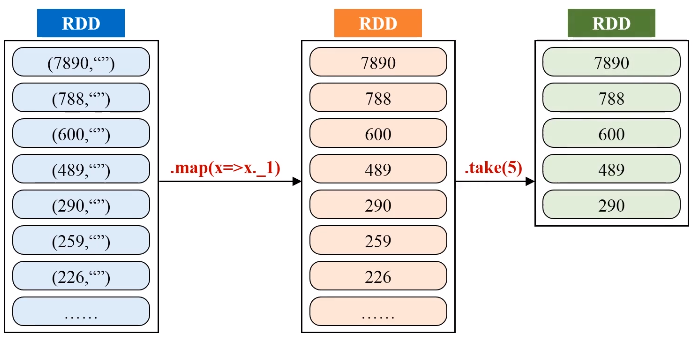

二、求最大最小值
任务描述:求出多个文件中数值的最大、最小值

解题思路:通过一个人造的key,让所有的值都成为“key”的value-list,然后对value-list进行遍历,用两个变量求出最大最小值。
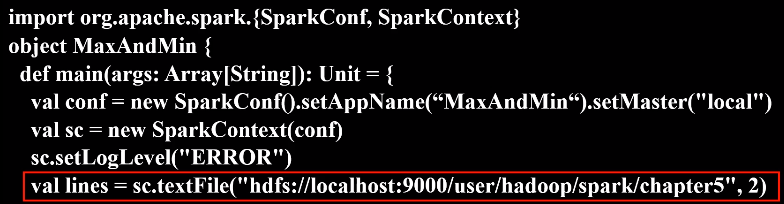


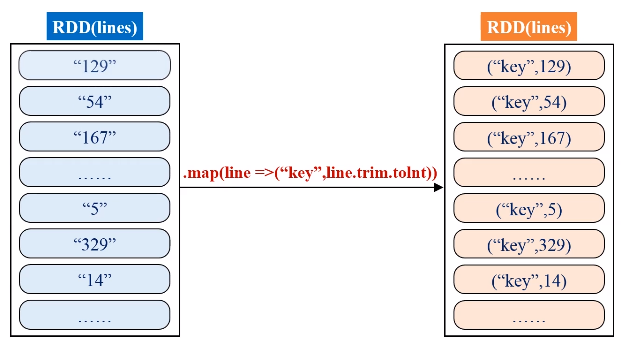
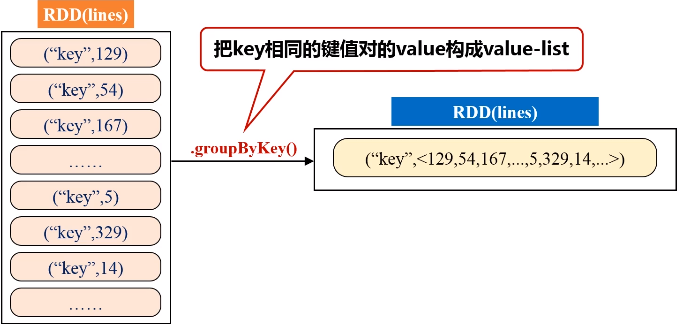
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | import org.apache.spark.{SparkConf, SparkContext}object MaxAndMin { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(“MaxAndMin“).setMaster("local") val sc = new SparkContext(conf) sc.setLogLevel("ERROR") val lines = sc.textFile("hdfs://localhost:9000/user/hadoop/spark/chapter5", 2) val result = lines.filter(_.trim().length>0).map(line => ("key",line.trim.toInt)).groupByKey().map(x => { var min = Integer.MAX_VALUE var max = Integer.MIN_VALUE for(num <- x._2){ if(num>max){ max = num } if(num<min){ min = num } } (max,min) }).collect.foreach(x => { println("max\t"+x._1) println("min\t"+x._2) }) } } |
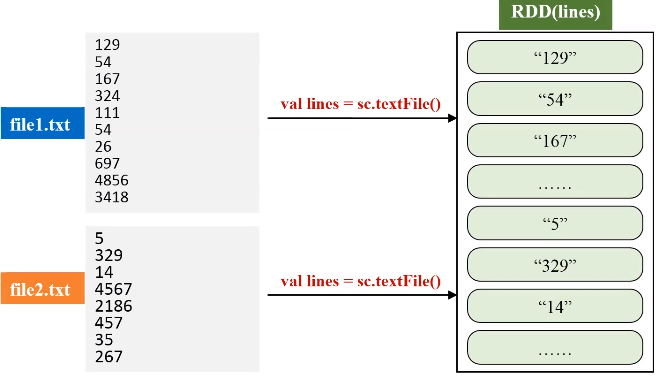
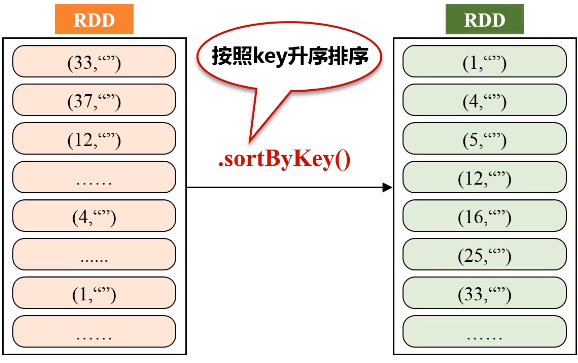
三、文件排序
任务描述:有多个输入文件,每个文件中的每一行内容均为一个整数。要求读取所有文件中的整数,进行排序后,输出到一个新的文件中,输出的内容个数为每行两个整数,第一个整数为第二个整数的排序位次,第二个整数为原待排序的整数。
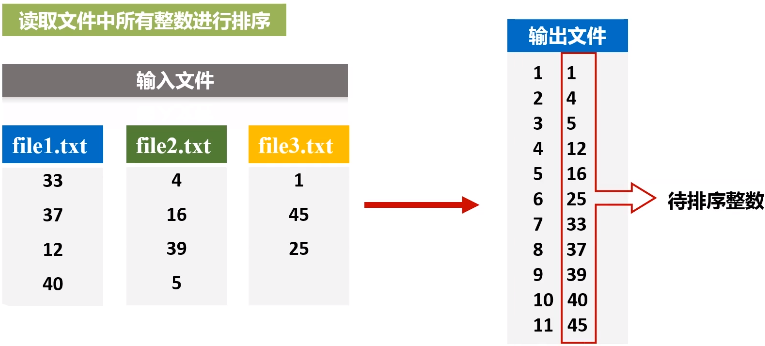
由于输入文件有多个,产生不同的分区,为了生成序号,使用HashPartitioner将中间的RDD归约到一起


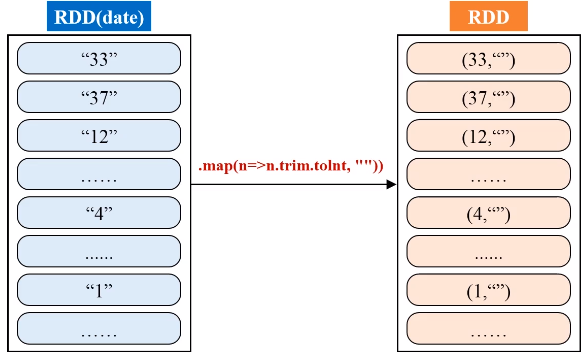


代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import org.apache.spark.SparkContextimport org.apache.spark.SparkContext._import org.apache.spark.SparkConfimport org.apache.spark.HashPartitionerobject FileSort { def main(args: Array[String]) { val conf = new SparkConf().setAppName("FileSort") val sc = new SparkContext(conf) val dataFile = "file:///usr/local/spark/mycode/rdd/data" val lines = sc.textFile(dataFile,3) var index = 0 val result = lines.filter(_.trim().length>0).map(n=>(n.trim.toInt,"")).partitionBy(new HashPartitioner(1)).sortByKey().map(t => { index += 1 (index,t._1) }) result.saveAsTextFile("file:///usrl/local/spark/mycode/rdd/examples/result") }} |
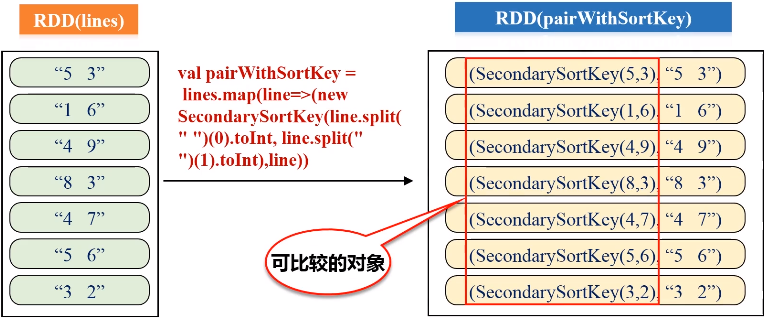
四、二次排序
任务要求:对于一个给定的文件(数据如file1.txt所示),请对数据进行排序,首先根据第1列数据降序排序,如果第1列数据相等,则根据第2列数据降序排序。

二次排序,具体的实现步骤:
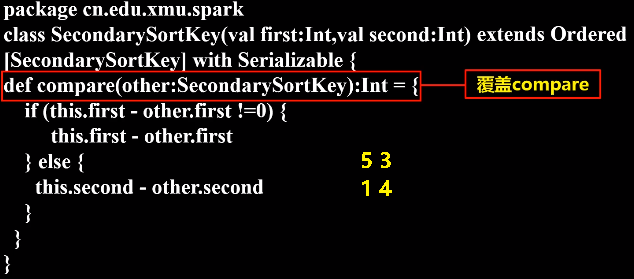
- 按照Ordered(继承排序的功能)和Serializable(继承可序列化的功能)接口实现自定义排序的key;
- 将要进行二次排序的文件加载进来生成<key,value>类型的RDD;
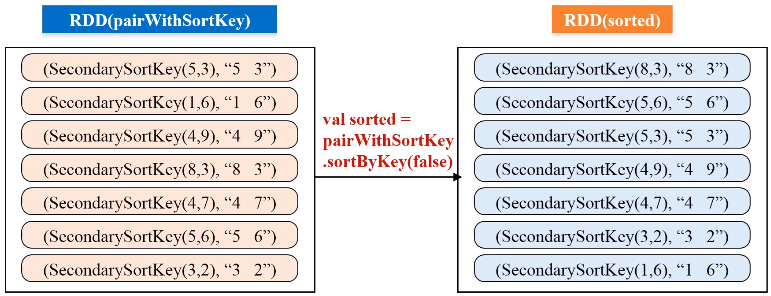
- 使用sortByKey基于自定义的Key进行二次排序;
- 去除掉排序的Key,只保留排序的结果
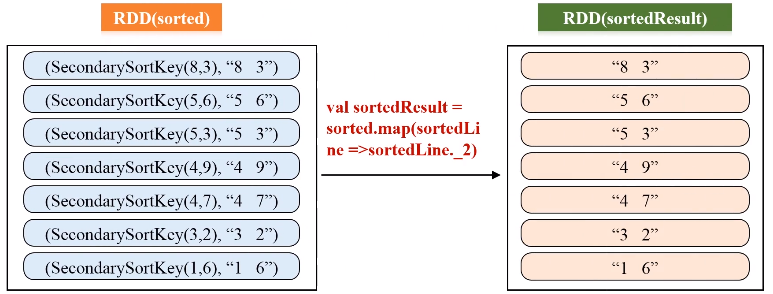
SecondarySortKey.scala代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | package sparkDemoclass SecondarySortKey(val first:Int,val second:Int) extends Ordered [SecondarySortKey] with Serializable {def compare(other:SecondarySortKey):Int = { if (this.first - other.first !=0) { this.first - other.first } else { this.second - other.second } }}package cn.edu.xmu.sparkimport org.apache.spark.SparkConfimport org.apache.spark.SparkContextobject SecondarySortApp { def main(args:Array[String]){ val conf = new SparkConf().setAppName("SecondarySortApp").setMaster("local") val sc = new SparkContext(conf) val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/examples/file1.txt", 1) val pairWithSortKey = lines.map(line=>(new SecondarySortKey(line.split(" ")(0).toInt, line.split(" ")(1).toInt),line)) val sorted = pairWithSortKey.sortByKey(false) val sortedResult = sorted.map(sortedLine =>sortedLine._2) sortedResult.collect().foreach (println) }} |
五、连接操作
任务描述:在推荐领域有一个著名的开放测试集,下载链接,该测试集包含三个文件,分别是ratings.dat、sers.dat、movies.dat,具体介绍可阅读:README.txt。请编程实现:通过连接ratings.dat和movies.dat两个文件得到平均得分超过4.0的电影列表,采用的数据集是:ml-1m
文件1:movies.dat(MovieID::Title::Genres)

文件2:ratings.dat(UserID::MovieID::Rating::Timestamp)

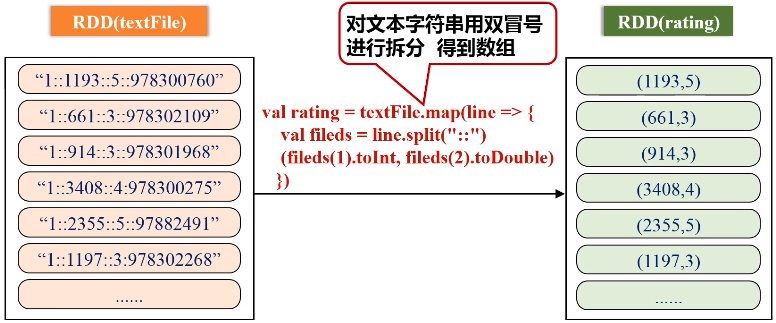
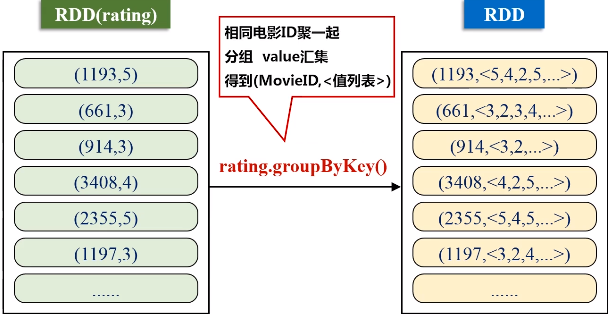
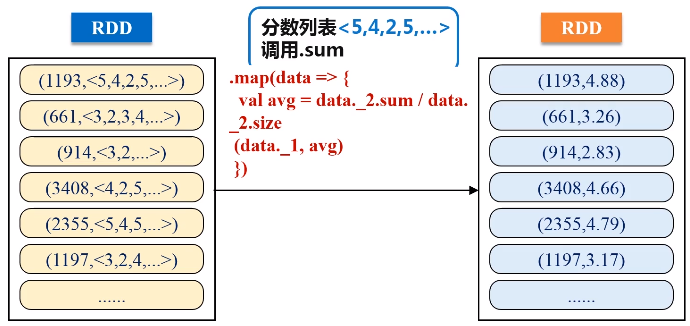
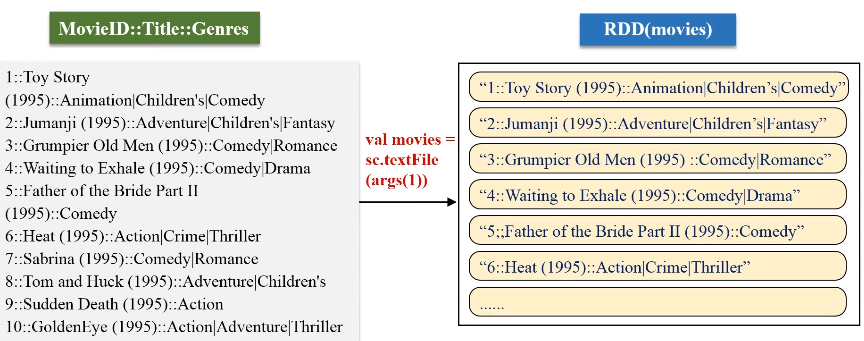
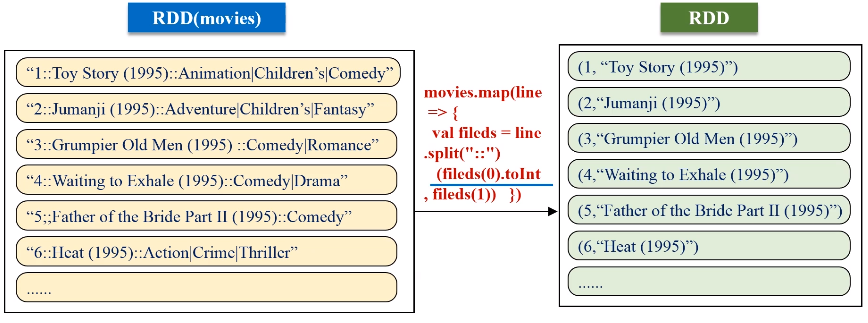
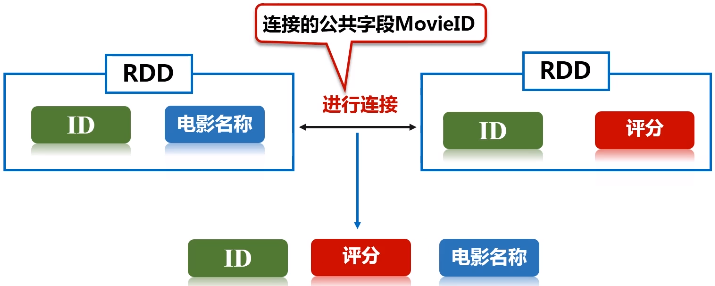
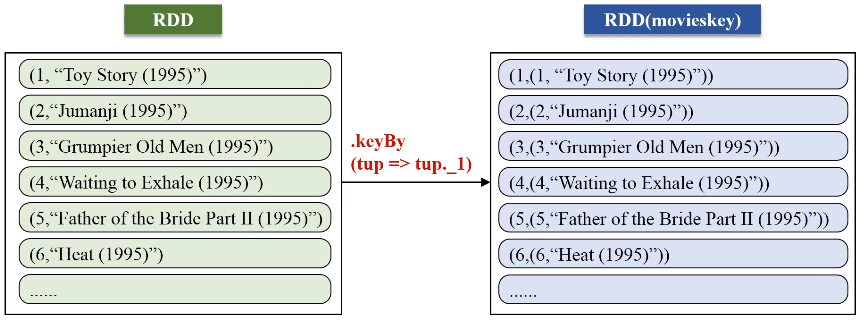

keyBy的key保持不变,value是把原来一整串的元素的值,整个作为新的RDD元素的一个value。
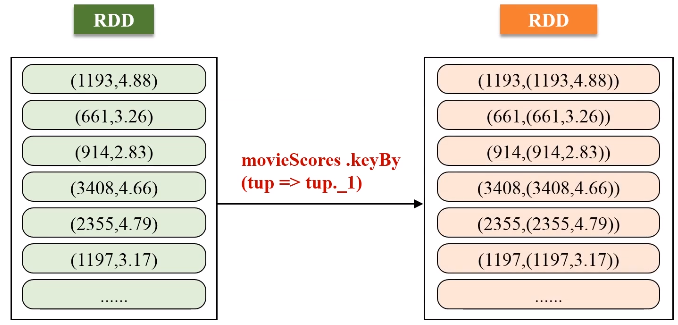

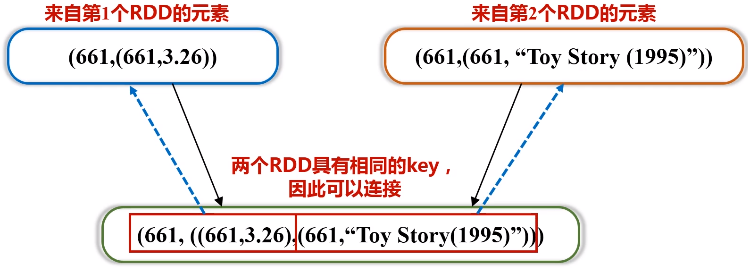
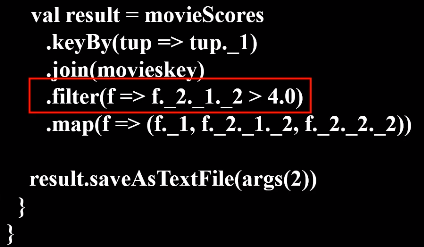
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | import org.apache.spark._ import SparkContext._ object SparkJoin { def main(args: Array[String]) { if (args.length != 3 ){ println("usage is WordCount <rating> <movie> <output>") return } val conf = new SparkConf().setAppName("SparkJoin").setMaster("local") val sc = new SparkContext(conf) // Read rating from HDFS file val textFile = sc.textFile(args(0)) //extract (movieid, rating) val rating = textFile.map(line => { val fileds = line.split("::") (fileds(1).toInt, fileds(2).toDouble) }) //get (movieid,ave_rating) val movieScores = rating .groupByKey() .map(data => { val avg = data._2.sum / data._2.size (data._1, avg) }) // Read movie from HDFS file val movies = sc.textFile(args(1)) val movieskey = movies.map(line => { val fileds = line.split("::") (fileds(0).toInt, fileds(1)) //(MovieID,MovieName) }).keyBy(tup => tup._1) // by join, we get <movie, averageRating, movieName> val result = movieScores .keyBy(tup => tup._1) .join(movieskey) .filter(f => f._2._1._2 > 4.0) .map(f => (f._1, f._2._1._2, f._2._2._2)) result.saveAsTextFile(args(2)) } } |
参考文献:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现
2018-11-09 【序列模型】第三课--序列模型和注意力机制
2018-11-09 【序列模型】第二课--自然语言处理与词嵌入