5.2 RDD编程---键值对RDD
一、键值对RDD的创建
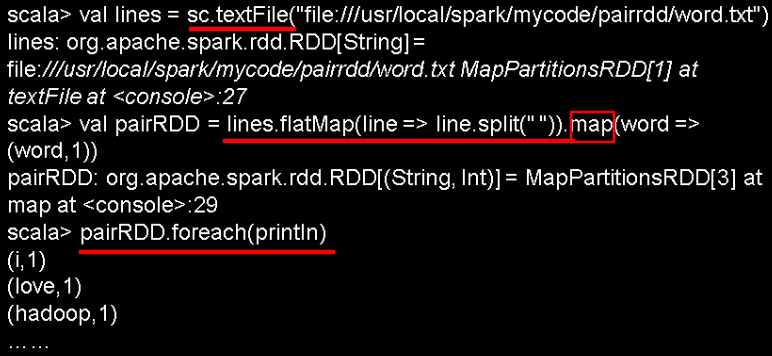
1.从文件中加载
2.通过并行集合(数组)创建RDD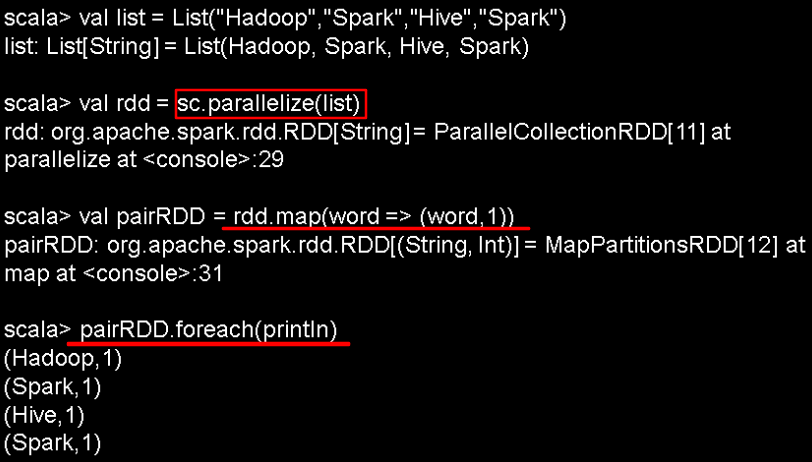
二、常用的键值对RDD转换操作
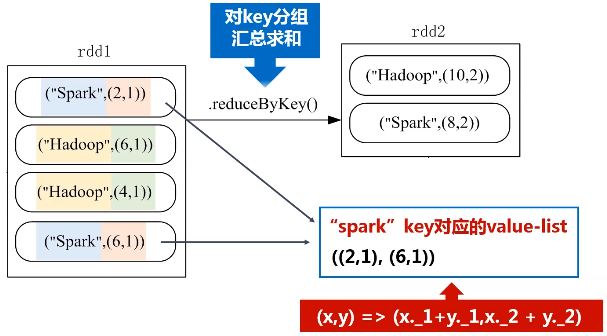
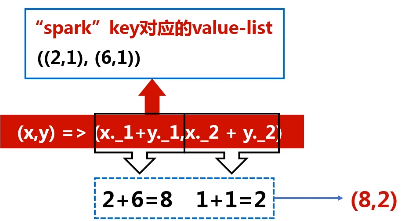
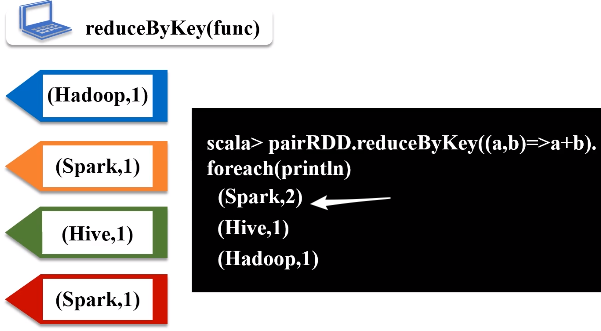
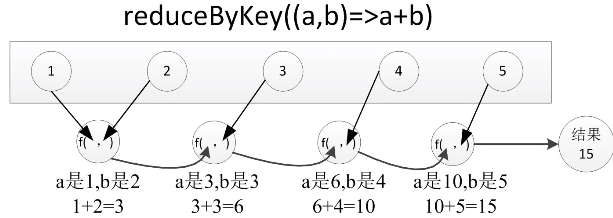
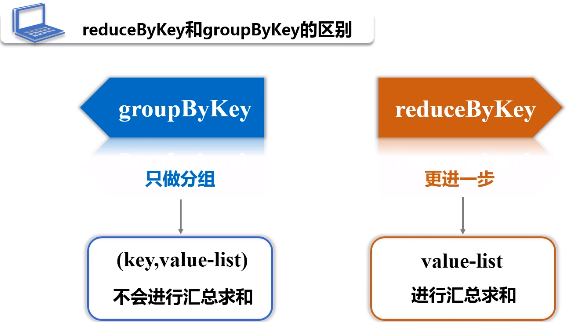
1.reduceByKey(func)
功能:使用func函数合并具有相同键的值
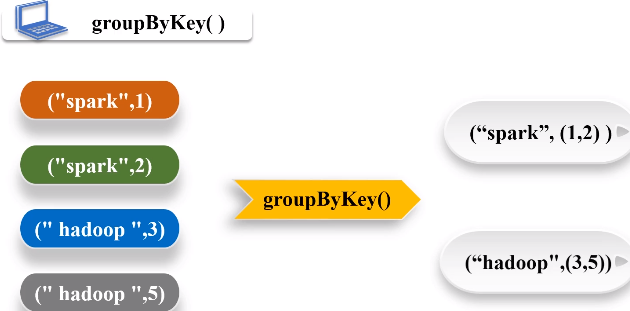
2.groupByKey()
功能:对具有相同键的值进行分组



3.keys

4.values

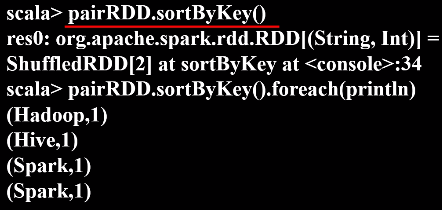
5.sortByKey()
默认按升序排序,括号里写false为降序排序

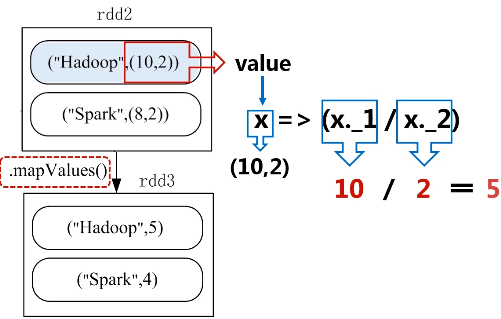
6.mapValues(func)
功能:对键值对RDD中的每个value都应用一个函数,key不会发生变化。

7.join
功能:把几个RDD当中元素key相同的进行连接


8.combineByKey
combineByKey(createCombiner,mergeValue,mergeCombiners,partitioner,mapSideCombine)
createCombiner:在第一次遇到Key时创建组合器函数,将RDD数据集中的V类型值转换C类型值(V => C)
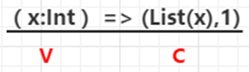
mergeValue:合并值函数,再次遇到相同的Key时,将createCombiner的C类型值与这次传入的V类型值合并成一个C类型值(C,V)=>C

mergeCombiners:合并组合器函数,将C类型值两两合并成一个C类型值
partitioner:使用已有的或自定义的分区函数,默认是HashPartitioner mapSideCombine:是否在map端进行Combine操作,默认为true
注意:前三个函数的参数类型要对应;第一次遇到Key时调用createCombiner,再次遇到相同的Key时调用mergeValue合并值
例:编程实现自定义Spark合并方案。给定一些销售数据,数据采用键值对的形式<公司,收入>,求出每个公司的总收入和平均收入,保存在本地文件
提示:可直接用sc.parallelize在内存中生成数据,在求每个公司总收入时,先分三个分区进行求和,然后再把三个分区进行合并。只需要编写RDD combineByKey函数的前三个参数的实现。
三、综合实例
题目:给定一组键值对("spark",2),("hadoop",6),("hadoop",4),("spark",6),键值对的key表示图书名称,value表示某天图书销量,请计算每个键对应的平均值,也就是计算每种图书的每天平均销量。