4.Spark环境搭建和使用方法
一、安装Spark
spark和Hadoop可以部署在一起,相互协作,由Hadoop的HDFS、HBase等组件复制数据的存储和管理,由Spark负责数据的计算。
Linux:CentOS Linux release 7.6.1810(Core)(cat /etc/centos-release 查看linux版本)
JDK:1.8.0_171(java -version)
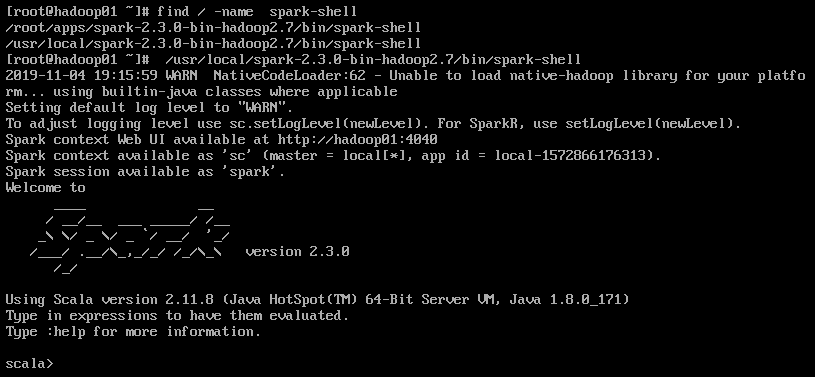
Spark:2.3.0(先在命令行中查找spark-shell所在的位置,命令为find / -name spark-shell,然后运行spark-shell,就能看到spark的版本号了)
二、在spark-shell中运行代码
1.四种模式
(1)local


![]()
(2)独立集群

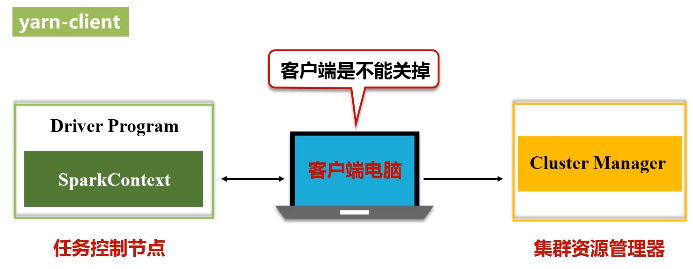
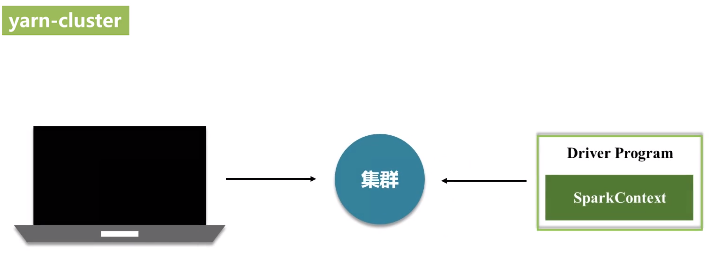
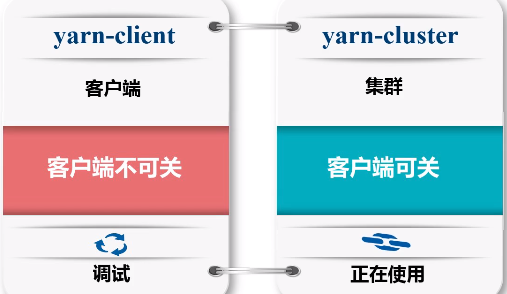
(3)yarn


(4)MESOS

举例:


启动spark shell成功后在输出信息的末尾可以看到"scala >"的命令提示符
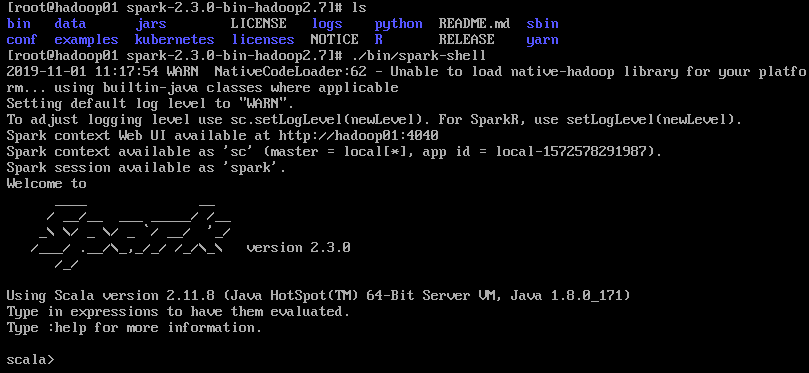

三、编写Spark独立应用程序

第一步:

第二步:

(1)sbt
步骤一:安装sbt



步骤2:用sbt打包
需要在应用程序的目录下构建simple.sbt文件(只要扩展名是.sbt都可以),在sbt中给出依赖说明,说明中包括当前应用的名称,版本号,scala版本,依赖的groupID



![]()
在正式打包编译之前,需要检查一下目录结构,必须要满足下面的目录结构,才允许打包,编译。



打包成功,会出现success信息

(2)Maven
步骤一:安装Maven


在写本地文件的时候一定是file:///


步骤二:建一个新的目录叫sparkapp2,在该目录下建立src/main/scala,增加SimpleApp.scala代码
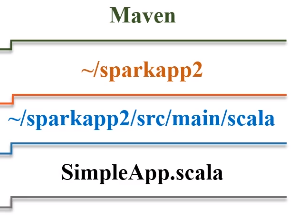
在“~/sparkapp2”目录中新建pom.xml文件


四、Spark集群环境搭建
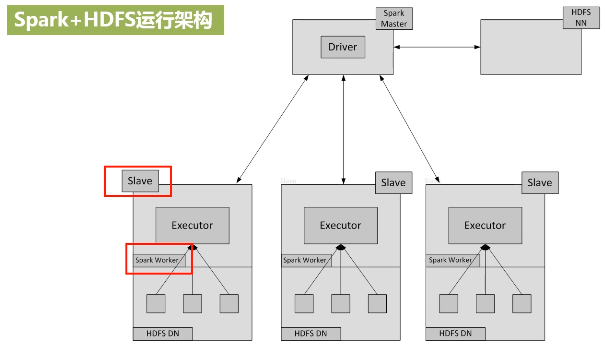
在实验室用三台机器搭建spark集群,一台作为主节点master,两台作为辅节点slave,将三台设备配置在同一个局域网内。 底层的Hadoop也要用集群进行配置,数据分布式保存,计算也要分布式运算

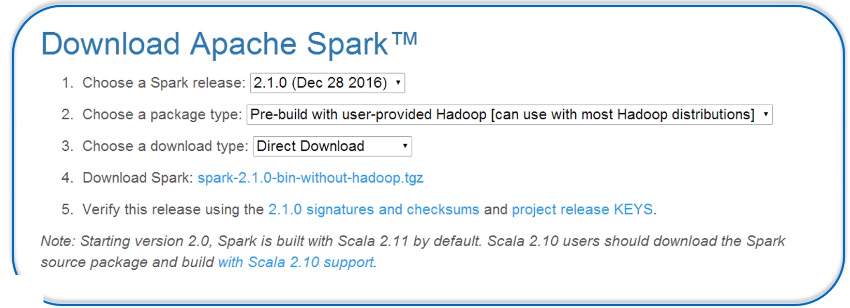
(1)在master节点上访问Spark官网下载Spark安装包

在master节点主机的终端中执行如下命令:
![]()
在.bashrc添加如下配置
![]()
运行source命令,使配置立即生效
![]()
(2)在master节点上配置slaves文件,该文件包含了所有从节点的相关信息,slaves文件是在Spark安装目录下面的conf子目录下,在conf子目录下有一个slave.template模块文件,把这个模板文件复制,重命名为Slaves文件。打开这个文件,把刚才两个从节点主机名称放到这个slave文件中保存一下,

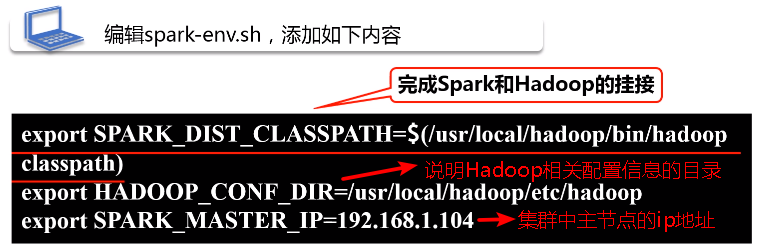
(3)配置spark-env.sh文件

将spark-env.template拷贝到spark-env.sh,在这个文件中,需要添加三行配置信息。
(4)将Master主机上的/usr/local/spark文件夹复制到各个节点上

在两个从节点上分别执行下面的操作,

(5)启动集群
启动Hadoop集群,然后启动Master节点,

然后再在master节点上,运行start-slaves.sh这个脚本文件,去启动另外两个从节点,

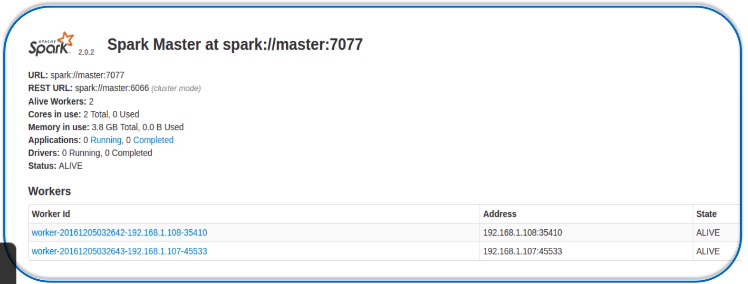
在master主机上打开浏览器,访问http://master:8080,就会显示下图集群信息
(6)关闭集群
先关闭spark(都是在master节点上执行,不用到slave节点关闭),再关闭Hadoop

五、在集群上运行Spark应用程序
1.启动Hadoop集群、Master节点和所有slaves节点

2.在集群汇总运行应用程序JAR包
安装目录是/usr/local/spark/,在这个目录下油锅spark-submit命令,用这个命令去提交刚才的应用程序,


![]()
3.在集群中运行spark-shell
在交互式命令下,运行程序。下面写法表示spark-shell一进入交互式环境,就连接到独立集群资源管理器上面,通过它来调度指挥资源。

在spark交互式环境中,系统会自动生成一个名词为sc的SparkContext对象


用户在独立集群管理Web界面查看应用的运行情况:在浏览器中输入http://master:8080/,就可以查看当前的运行状态。
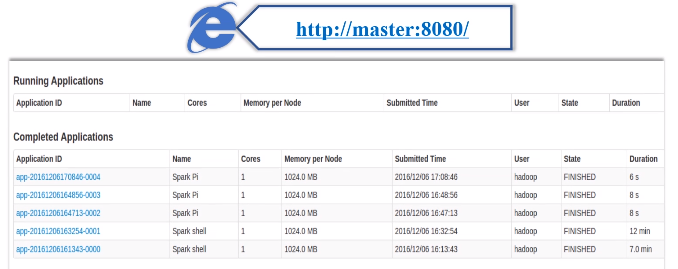
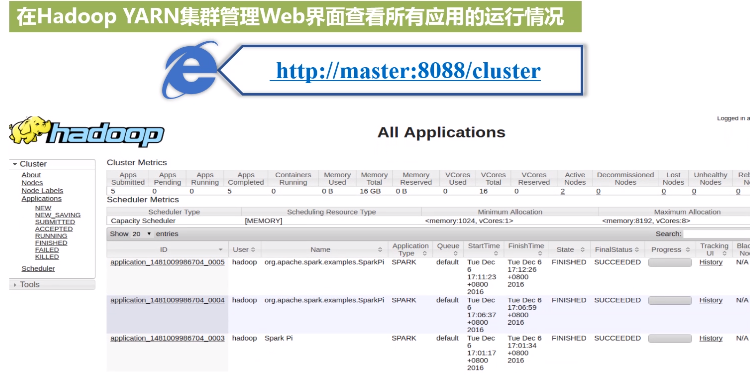
4.向Hadoop YARN集群管理器提交应用
在当前master节点的安装目录下去运行命令,

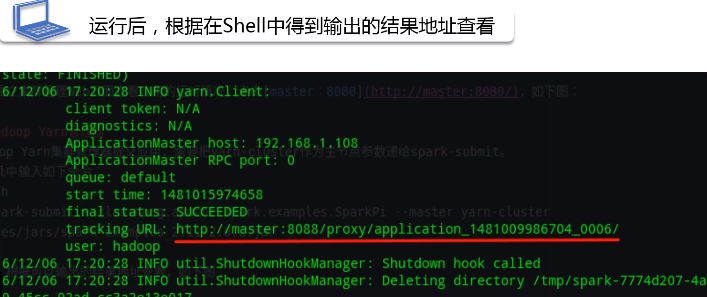
运行后,根据在shell中得到输出的结果地址进行查看
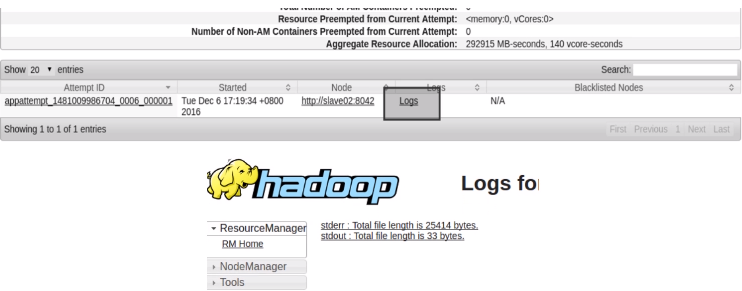
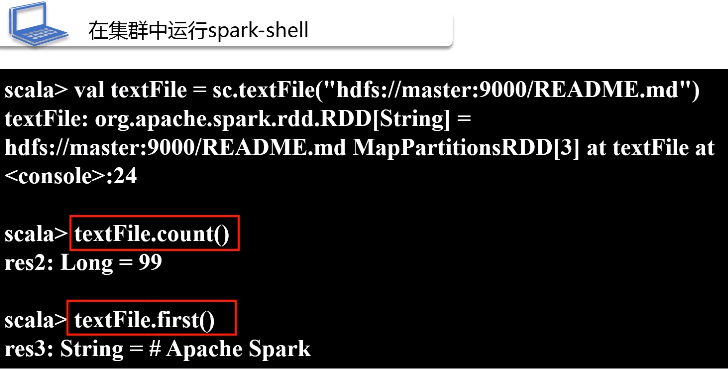
5.用spark-shell连接到YARN集群管理器上
在客户端启动一个spark-shell,是在客户端的交互式环境下执行,不可能是cluster模式,肯定是一个client模式。

参考文献:
