
循环神经网络
分类:
深度学习算法
一、RNN
1.展开图
(1)假设为时刻系统的外部驱动信号,则动态系统的状态为
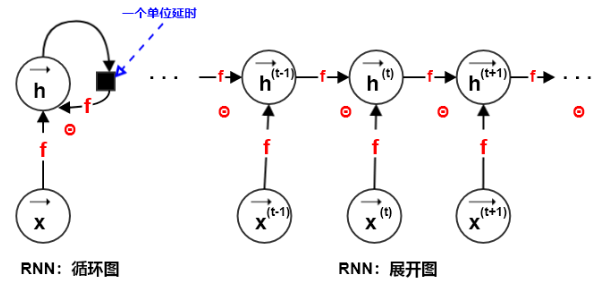
(2)当训练RNN根据过去预测未来时,网络通常要讲作为过去序列信息的一个有损的representation,因为它使用一个固定长度的向量来表达任意长的序列
根据不同的训练准则,representation可能会有选择地保留过去序列的某些部分,如attention机制。
(3)网络的初始状态的设置有两种方式:
- 固定为全0,模型的反向传播不需要考虑,因为全0导致对应参数的梯度贡献也为0。
- 使用上一个样本的最后一个状态:,这种场景通常是样本之间存在连续的关系(如:样本分别代表一篇小说中的每个句子),并且样本之间没有发生混洗的情况。此时,后一个样本的初始状态和前一个样本的最后状态可以认为保持连续性。
(4)展开图的两个主要优点:
- 无论输入序列的长度如何,学得的模型始终具有相同的输入大小。因为模型在每个时间步上,其模型的输入都是相同大小的。
- 每个时间步上都使用相同的转移函数,因此需要学得的参数也就在每个时间步上共享。
这些优点直接导致了:
- 学习在所有时间步、所有序列长度上操作的单个函数f成为可能;
- 允许单个函数f泛化到没有见过的序列长度;
- 学习模型所需的训练样本远少于非参数共享的模型(如前馈神经网络)
2.网络模式
根据输入序列的长度,RNN网络模式可以划分为:输入序列长度为0、输入序列长度为1、输入序列为。
2.1 零长度输入序列
2.2 单长度输入序列
2.3 多长度输入序列
3.输出序列长度
二、训练算法
1.BPTT算法
2.Teacher forcing算法
三、长期依赖
1.长期依赖
2.多时间尺度
3.渗漏单元
4.梯度截断
5.引导信息流的正则化


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现