
tf.nn.embedding_lookup()
分类:
TensorFlow
1 2 3 4 5 6 7 8 | tf.nn.embedding_lookup( params, ids, partition_strategy='mod', name=None, validate_indices=True, max_norm=None) |
功能:选取一个张量里面索引对应的行的向量
TensorFlow链接:https://tensorflow.google.cn/api_docs/python/tf/nn/embedding_lookup?hl=en
参数:
- params:张量或数组;
- id:对应的索引
- partition_strategy:partition_strategy是用于当len(params) > 1,params的元素分割不能整分的话,则前(max_id + 1) % len(params)多分一个id.
- 当partition_strategy = 'mod'的时候,13个ids划分为5个分区:[[0, 5, 10], [1, 6, 11], [2, 7, 12], [3, 8], [4, 9]],也就是是按照数据列进行映射,然后再进行look_up操作。默认是mod
- 当partition_strategy = 'div'的时候,13个ids划分为5个分区:[[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10], [11, 12]],也就是是按照数据先后进行排序标序,然后再进行look_up操作。
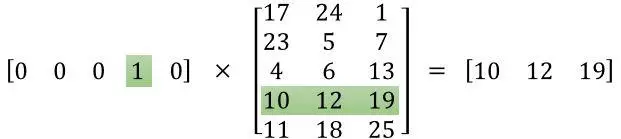 (图来自https://www.jianshu.com/p/abea0d9d2436)
(图来自https://www.jianshu.com/p/abea0d9d2436)
举例:
1 2 3 4 5 6 7 8 9 10 | import numpy as npA = tf.convert_to_tensor(np.array([[[1],[2]],[[3],[4]],[[5],[6]]]))B = tf.nn.embedding_lookup(A, [[0,1],[1,0],[0,0]])with tf.Session() as sess: sess.run(tf.global_variables_initializer()) print('A',sess.run(A)) print('A shape',A.shape) print('B',sess.run(B)) print('B shape',B.shape) |
结果:
A [[[1] [2]] [[3] [4]] [[5] [6]]]A shape (3, 2, 1)B [[[[1] [2]] [[3] [4]]] [[[3] [4]] [[1] [2]]] [[[1] [2]] [[1] [2]]]]B shape (3, 2, 2, 1) |
参考文献:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现