
3(2).特征选择---包装法
分类:
特征工程
1. 前向搜索
每次增量地从剩余未选中的特征选出一个加入特征集中,待达到阈值或者 时,从所有的
中选出错误率最小的。过程如下:
- 初始化特征集
为空。
- 扫描
从
到
- 如果第
(即
)。
- 在只使用
- 从上步中得到的
个
- 如果
- 那么输出整个搜索过程中最好的 ;若没达到,则转到 2,继续扫描。
2. 后向搜索
既然有增量加,那么也会有增量减,后者称为后向搜索。先将 设置为
,然后每次删除一个特征,并评价,直到达到阈值或者为空,然后选择最佳的
。
这两种算法都可以工作,但是计算复杂度比较大。时间复杂度为
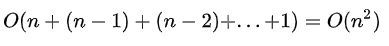
3. 递归特征消除法
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。使用feature_selection库的RFE类来选择特征的代码如下:
1 2 3 4 5 6 7 | from sklearn.feature_selection import RFEfrom sklearn.linear_model import LogisticRegression#递归特征消除法,返回特征选择后的数据#参数estimator为基模型#参数n_features_to_select为选择的特征个数RFE(estimator=LogisticRegression(), n_features_to_select=2).fit_transform(iris.data, iris.target) |

举例:使用一个基模型来进行多轮训练,经过多轮训练后,保留指定的特征数。
#首先导入数据到data变量中import pandasdata=pandas.read_csv('路径.csv')#接着,我们使用RFE类,在estimator中,#把我们的基模型设置为线性回归模型LinearRegression,#然后在把我们要选择的特征数设置为2,#接着就可以使用这个rfe对象,把自变量和因变量传入fit_transform方法,#即可得到我们需要的特征值from sklearn.feature_selection import RFEfrom sklearn.linear_model import LinearRegressionfeature =data[['月份','季度','广告推广费','注册并投资人数']]rfe =RFE( estimator=LinearRegression(), n_features_to_select=2)sFeature = rfe.fit_transform( feature, data['销售金额'])#同理,我们要想知道这两个自变量的名字,#使用get_support方法,即可得到对应的列名rfe.get_support() |
分类:
特征工程


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现