
22(7).模型融合---CatBoost
一、Catboost简介
二、Catboost的特点
一般来说,Gradient Boosting(GB)方法适用于异质化数据。即,若你的数据集全由图片数据构成或者全由视频数据构成之类的,我们称其为同质化数据,这时使用神经网络往往会有更好的表现。但对于异质化数据,比如说数据集中有user gender,user age,也有content data等等的情况,GB方法的表现往往更好。GB方法比神经网络的入门门槛更低,使用起来也更简单。
NN和GB方法可以结合起来使用,并常常有很好的表现。我们可以使用NN方法学习embedding feature,并且和其他一些特征结合起来,再过GBDT。
Catboost具有一些和其他类似的库不同的特征:
1.类别型特征
对于可取值的数量比独热最大量还要大的分类变量,CatBoost 使用了一个非常有效的编码方法,这种方法和均值编码类似,但可以降低过拟合情况。它的具体实现方法如下:
- 将输入样本集随机排序,并生成多组随机排列的情况。
- 将浮点型或属性值标记转化为整数。
- 将所有的分类特征值结果都根据以下公式,转化为数值结果。
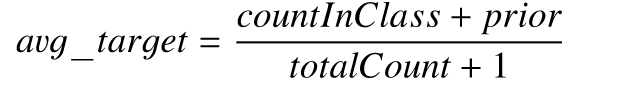
其中 CountInClass 表示在当前分类特征值中,有多少样本的标记值是「1」;Prior 是分子的初始值,根据初始参数确定。TotalCount 是在所有样本中(包含当前样本),和当前样本具有相同的分类特征值的样本数量。可以用下面的数学公式表示:
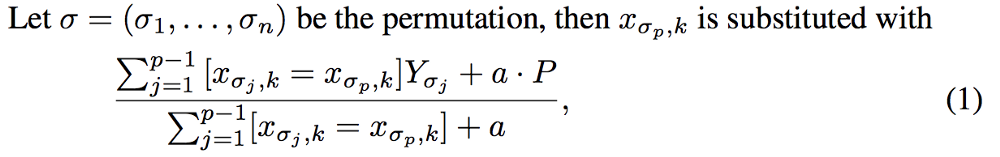
特征组合
其次,它用特殊的方式处理categorical features。首先他们会计算一些数据的statistics。计算某个category出现的频率,加上超参数,生成新的numerical features。这一策略要求同一标签数据不能排列在一起(即先全是0之后全是1这种方式),训练之前需要打乱数据集。第二,使用数据的不同排列(实际上是4个)。在每一轮建立树之前,先扔一轮骰子,决定使用哪个排列来生成树。第三,考虑使用categorical features的不同组合。例如颜色和种类组合起来,可以构成类似于blue dog这样的feature。当需要组合的categorical features变多时,catboost只考虑一部分combinations。在选择第一个节点时,只考虑选择一个feature,例如A。在生成第二个节点时,考虑A和任意一个categorical feature的组合,选择其中最好的。就这样使用贪心算法生成combinations。第四,除非向gender这种维数很小的情况,不建议自己生成one-hot vectors,最好交给算法来处理。
2.克服梯度偏差
catboost和其他算法计算leaf-value的方法不同。传统的boosting使用平均数,但这个估计是有偏的,会导致过拟合。而Catboost则采用另外的计算方法。


3.快速评分
Catboost使用对称树。XGboost一层一层地建立节点,lightGBM一个一个地建立节点,而Catboost总是使用完全二叉树。它的节点是镜像的。Catboost称对称树有利于避免overfit,增加可靠性,并且能大大加速预测等等。
CatBoost使用oblivious树作为基本预测器,这种树是平衡的,不太容易过拟合。oblivious树中,每个叶子节点的索引可以被编码为长度等于树深度的二进制向量。CatBoost首先将所有浮点特征、统计信息和独热编码特征进行二值化,然后使用二进制特征来计算模型预测值。

4.基于GPU实现快速学习
- 密集的数值特征
任何GBDT算法,对于密集的数值特征数据集来说,搜索最佳分割是建立决策树时的主要计算负担。CatBoost利用oblivious决策树作为基础模型,并将特征离散化到固定数量的箱子中以减少内存使用。就GPU内存使用而言,CatBoost至少与LightGBM一样有效。主要改进之处就是利用了一种不依赖于原子操作的直方图计算方法。
- 类别型特征
CatBoost使用完美哈希来存储类别特征的值,以减少内存使用。由于GPU内存的限制,在CPU RAM中存储按位压缩的完美哈希,以及要求的数据流、重叠计算和内存等操作。通过哈希来分组观察。在每个组中,我们需要计算一些统计量的前缀和。该统计量的计算使用分段扫描GPU图元实现。
- 多GPU支持
CatBoost中的GPU实现可支持多个GPU。分布式树学习可以通过数据或特征进行并行化。CatBoost采用多个学习数据集排列的计算方案,在训练期间计算分类特征的统计数据。
三、与xgboost、lightgbm的对比

参数对比:

数据集:
在这里,我使用了 2015 年航班延误的 Kaggle 数据集,其中同时包含分类变量和数值变量。这个数据集中一共有约 500 万条记录,因此很适合用来同时评估比较三种 boosting 算法的训练速度和准确度。我使用了 1% 的数据:5 万行记录。
以下是建模使用的特征:
月、日、星期:整型数据
航线或航班号:整型数据
出发、到达机场:数值数据
出发时间:浮点数据
到达延误情况:这个特征作为预测目标,并转为二值变量:航班是否延误超过 10 分钟
距离和飞行时间:浮点数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | import pandas as pd, numpy as np, timefrom sklearn.model_selection import train_test_splitdata = pd.read_csv("flight-delays/flights.csv")data = data.sample(frac = 0.1, random_state=10)#500->50data = data.sample(frac = 0.1, random_state=10)#50->5data.shape#(58191, 31)data = data[["MONTH","DAY","DAY_OF_WEEK","AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT", "ORIGIN_AIRPORT","AIR_TIME", "DEPARTURE_TIME","DISTANCE","ARRIVAL_DELAY"]]data.dropna(inplace=True)data["ARRIVAL_DELAY"] = (data["ARRIVAL_DELAY"]>10)*1#data.head()cols = ["AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT","ORIGIN_AIRPORT"]for item in cols: data[item] = data[item].astype("category").cat.codes +1train, test, y_train, y_test = train_test_split(data.drop(["ARRIVAL_DELAY"], axis=1), data["ARRIVAL_DELAY"], random_state=10, test_size=0.25) |
最终的数据集大概长这个样子:
1.xgboost
和 CatBoost 以及 LGBM 算法不同,XGBoost 本身无法处理分类变量,而是像随机森林一样,只接受数值数据。因此在将分类数据传入 XGBoost 之前,必须通过各种编码方式:例如标记编码、均值编码或独热编码对数据进行处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | import xgboost as xgbfrom sklearn.grid_search import GridSearchCVfrom sklearn import metricsdef auc(m, train, test): return (metrics.roc_auc_score(y_train,m.predict_proba(train)[:,1]), metrics.roc_auc_score(y_test,m.predict_proba(test)[:,1]))Parameter Tuningmodel = xgb.XGBClassifier()param_dist = {"max_depth": [10,30,50], "min_child_weight" : [1], "n_estimators": [200], "learning_rate": [0.16],}grid_search = GridSearchCV(model, param_grid=param_dist, cv = 3, verbose=10, n_jobs=-1)grid_search.fit(train, y_train)grid_search.best_estimator_model = xgb.XGBClassifier(max_depth=10, min_child_weight=1, n_estimators=200,\ n_jobs=-1 , verbose=1,learning_rate=0.16)train.shape,y_train.shape#((42855, 10), (42855,))model.fit(train,y_train)auc(model,train,test)#过拟合 (1.0, 0.6990888367179413) |
2.Light GBM
和 CatBoost 类似,LighGBM 也可以通过使用特征名称的输入来处理属性数据;它没有对数据进行独热编码,因此速度比独热编码快得多。LGBM 使用了一个特殊的算法来确定属性特征的分割值。注意,在建立适用于 LGBM 的数据集之前,需要将分类变量转化为整型变量;此算法不允许将字符串数据传给分类变量参数。
(1)不加categorical_feature 选项
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | import lightgbm as lgbfrom sklearn import metricsdef auc2(m, train, test): return (metrics.roc_auc_score(y_train,m.predict(train)), metrics.roc_auc_score(y_test,m.predict(test)))lg = lgb.LGBMClassifier(silent=False)param_dist = {"max_depth": [25,50, 75], "learning_rate" : [0.01,0.05,0.1], "num_leaves": [300,900,1200], "n_estimators": [200] }grid_search = GridSearchCV(lg, n_jobs=-1, param_grid=param_dist, cv = 3, scoring="roc_auc", verbose=5)grid_search.fit(train,y_train)grid_search.best_estimator_d_train = lgb.Dataset(train, label=y_train)params = {"max_depth": 50, "learning_rate" : 0.1, "num_leaves": 900, "n_estimators": 300}# Without Categorical Featuresmodel2 = lgb.train(params, d_train)auc2(model2, train, test)#(1.0, 0.6813950368358092) |
(2)加categorical_feature 选项
1 2 3 4 5 6 7 8 9 | #With Catgeorical Featurescate_features_name = ["MONTH","DAY","DAY_OF_WEEK","AIRLINE","DESTINATION_AIRPORT", "ORIGIN_AIRPORT"]d_train = lgb.Dataset(train, label=y_train)model2 = lgb.train(params, d_train, categorical_feature = cate_features_name)auc2(model2, train, test)#(1.0, 0.6781812538027399) |
3. CatBoost
在对 CatBoost 调参时,很难对分类特征赋予指标。因此,同时给出了不传递分类特征时的调参结果,并评估了两个模型:一个包含分类特征,另一个不包含。我单独调整了独热最大量,因为它并不会影响其他参数。
如果未在cat_features参数中传递任何内容,CatBoost会将所有列视为数值变量。注意,如果某一列数据中包含字符串值,CatBoost 算法就会抛出错误。另外,带有默认值的 int 型变量也会默认被当成数值数据处理。在 CatBoost 中,必须对变量进行声明,才可以让算法将其作为分类变量处理。
(1)不加Categorical features选项
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | import catboost as cbcat_features_index = [0,1,2,3,4,5,6]def auc(m, train, test): return (metrics.roc_auc_score(y_train,m.predict_proba(train)[:,1]), metrics.roc_auc_score(y_test,m.predict_proba(test)[:,1]))params = {'depth': [4, 7, 10], 'learning_rate' : [0.03, 0.1, 0.15], 'l2_leaf_reg': [1,4,9], 'iterations': [300]}cb = cb.CatBoostClassifier()cb_model = GridSearchCV(cb, params, scoring="roc_auc", cv = 3)cb_model.fit(train, y_train)# With Categorical featuresclf = cb.CatBoostClassifier(eval_metric="AUC", depth=10, iterations= 500, l2_leaf_reg= 9, learning_rate= 0.15)%timeit clf.fit(train,y_train)auc(clf, train, test)#(0.7994405189483305, 0.7097991233818941) |
(2)有Categorical features选项
1 2 3 4 5 6 | # With Categorical featuresclf = cb.CatBoostClassifier(eval_metric="AUC",one_hot_max_size=31, \ depth=10, iterations= 500, l2_leaf_reg= 9, learning_rate= 0.15)clf.fit(train,y_train, cat_features= cat_features_index)auc(clf, train, test)#(0.7937591249216596, 0.7167802198229718) |

请记住,CatBoost 在测试集上表现得最好,测试集的准确度最高(0.716)、过拟合程度最小(在训练集和测试集上的准确度很接近)以及最小的预测和调试时间。但这个表现仅仅在有分类特征,而且调节了独热最大量时才会出现。如果不利用 CatBoost 算法在这些特征上的优势,它的表现效果就会变成最差的:仅有 0.709 的准确度。因此我们认为,只有在数据中包含分类变量,同时我们适当地调节了这些变量时,CatBoost 才会表现很好。
第二个使用的是 XGBoost,它的表现也相当不错。即使不考虑数据集包含有转换成数值变量之后能使用的分类变量,它的准确率也和 CatBoost 非常接近了。但是,XGBoost 唯一的问题是:它太慢了。尤其是对它进行调参,非常令人崩溃。更好的选择是分别调参,而不是使用 GridSearchCV。
最后一个模型是 LightGBM,这里需要注意的一点是,在使用 CatBoost 特征时,LightGBM 在训练速度和准确度上的表现都非常差。我认为这是因为它在分类数据中使用了一些修正的均值编码方法,进而导致了过拟合(训练集准确率非常高:1.0,尤其是和测试集准确率相比之下)。但如果我们像使用 XGBoost 一样正常使用 LightGBM,它会比 XGBoost 更快地获得相似的准确度,如果不是更高的话(LGBM—0.681, XGBoost—0.699)。
最后必须指出,这些结论在这个特定的数据集下成立,在其他数据集中,它们可能正确,也可能并不正确。但在大多数情况下,XGBoost 都比另外两个算法慢。
四、优缺点
优点:
- 性能卓越:在性能方面可以匹敌任何先进的机器学习算法;
- 鲁棒性/强健性:它减少了对很多超参数调优的需求,并降低了过度拟合的机会,这也使得模型变得更加具有通用性;
- 易于使用:提供与scikit集成的Python接口,以及R和命令行界面;
- 实用:可以处理类别型、数值型特征;可扩展:支持自定义损失函数
参考文献:
【1】从结构到性能,一文概述XGBoost、Light GBM和CatBoost的同与不同
【2】CatBoost vs. Light GBM vs. XGBoost
【3】Catboost学习笔记
【5】github:https://github.com/catboost/catboost/tree/master/catboost/tutorials


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现