
计算文本相似度方法总结(一)
方法1:无监督,不使用额外的标注数据
-
average word vectors:简单的对句子中的所有词向量取平均,是一种简单有效的方法,
缺点:没有考虑到单词的顺序,只对15个字以内的短句子比较有效,丢掉了词与词间的相关意思,无法更精细的表达句子与句子之间的关系。
-
tfidf-weighting word vectors:指对句子中的所有词向量根据tfidf权重加权求和,是常用的一种计算sentence embedding的方法,在某些问题上表现很好,相比于简单的对所有词向量求平均,考虑到了tfidf权重,因此句子中更重要的词占得比重就更大。
缺点:没有考虑到单词的顺序
-
bag of words:这种方法对于短文本效果很差,对于长文本效果一般,通常在科研中用来做baseline。缺点:1.没有考虑到单词的顺序,2.忽略了单词的语义信息。
-
LDA:计算出一片文档或者句子的主题分布。也常常用于文本分类任务
-
以smooth inverse frequency[1](简称SIF)为权重,对所有词的word vector加权平均,最后从中减掉principal component,得到sentence embedding
[1] Sanjeev Arora, et al. 2017. A Simple but Tough-to-Beat Baseline for Sentence Embeddings
-
通过Word Mover’s Distance[2](简称WMD),直接度量句子之间的相似度
[2] Matt J. Kusner, et al. 2015. From Word Embeddings To Document Distances
-
LSI或LSA:LSI是处理相似度的,基于SVD分解,用于特征降维,LSI求解出来的相似度跟topic相关性很强,而句子结构等信息较少。顺便说下,句子中词的顺序是不会影响LSI相似度结果的。
方法2:有监督,需要额外的标注数据
-
分类任务,例如训练一个CNN的文本分类器[3],取最后一个hidden layer的输出作为sentence embedding,其实就是取分类器的前几层作为预训练的encoder
[3] Yoon Kim. 2014. Convolutional Neural Networks for Sentence Classification
-
sentence pair的等价性/等义性判定[4],这种方法的好处是不仅可以得到sentence embedding,还可以直接学习到距离度量函数里的参数
[4] Jonas Mueller, et al. 2016. Siamese Recurrent Architectures for Learning Sentence Similarity
方法3:DSSM-LSTM,2016年提出
用DSSM-LSTM计算任意一对短文本的语义相似性,能够捕捉上下文信息。
方法4:doc2vec(paragraph2vec, sentence embeddings),2014年提出
一种非监督式算法,可以获得 sentences/paragraphs/documents 的向量表达,是 word2vec 的拓展。学出来的向量可以通过计算距离来找 sentences/paragraphs/documents 之间的相似性,可以用于文本聚类,对于有标签的数据,还可以用监督学习的方法进行文本分类,例如经典的情感分析问题。
训练过程中新增了paragraph id,即训练语料中每个句子都有一个唯一的id。paragraph id 和普通的word一样,先是映射成一个向量,即paragraph vector。paragraph vector与word vector的维数虽一样,但是来自于两个不同的向量空间。在之后的计算里,paragraph vector与word vector累加或者连接起来,作为输出层softmax的输入。在一个句子或者文档的训练过程中,paragraph id保持不变,共享同一个paragraph vector,相当于每次在预测单词的概率时,都利用了整个句子的语义。
DM(Distributed Memory,分布式内存):DM试图在给定前面部分的词和paragraph向量来预测后面单独的单词,即使文本中的语境在变化,但paragraph向量不会变换,并且能保存词序信息。
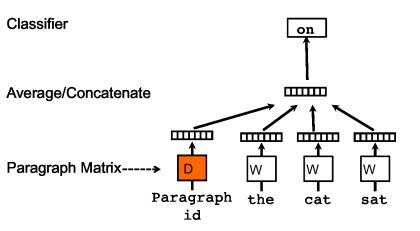
分布式词袋(DBOW):利用paragraph来预测段落中一组随机的词.

sentence2vec相对于word2vec的skip-gram模型,区别点为:在sentence2vec里,输入都是paragraph vector,输出是该paragraph中随机抽样的词。
参考文献:
【1】doc2vec原理及实践
【2】句子和文档的分布式表示


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现