
Tensorflow实现手写体分类(含dropout)
一、手写体分类
1. 数据集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | import tensorflow as tffrom tensorflow.examples.tutorials.mnist import input_dataimport osos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'os.environ["CUDA_VISIBLE_DEVICES"] = "0"config = tf.ConfigProto(allow_soft_placement = True)gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction = 0.33)config.gpu_options.allow_growth = Truemax_steps = 20 # 最大迭代次数learning_rate = 0.001 # 学习率dropout = 0.9 # dropout时随机保留神经元的比例data_dir = '.\MNIST_DATA' # 样本数据存储的路径log_dir = 'E:\MNIST_LOG' # 输出日志保存的路径# 获取数据集,并采用采用one_hot热编码mnist = input_data.read_data_sets(data_dir,one_hot = True)# mnist=input_data.read_data_sets('MNIST_data',one_hot=True)'''下载数据是直接调用了tensorflow提供的函数read_data_sets,输入两个参数,第一个是下载到数据存储的路径,第二个one_hot表示是否要将类别标签进行独热编码。它首先回去找制定目录下有没有这个数据文件,没有的话才去下载,有的话就直接读取。所以第一次执行这个命令,速度会比较慢。'''# sess = tf.InteractiveSession(config = config) |
下面的图是通过调用 tf.summary.image('input', image_shaped_input, 10)得到的,具体见2.初始化参数

2. 初始化参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | with tf.name_scope('input'): x = tf.placeholder(tf.float32, [None, 784], name='x-input') y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')# 保存图像信息with tf.name_scope('input_reshape'): image_shaped_input = tf.reshape(x, [-1, 28, 28, 1]) tf.summary.image('input', image_shaped_input, 10)# 初始化权重参数def weight_variable(shape): initial = tf.truncated_normal(shape, stddev = 0.1) return tf.Variable(initial)# 初始化偏执参数def bias_variable(shape): initial = tf.constant(0.1, shape = shape) return tf.Variable(initial)# 绘制参数变化def variable_summaries(var): with tf.name_scope('summaries'): # 计算参数的均值,并使用tf.summary.scaler记录 mean = tf.reduce_mean(var) tf.summary.scalar('mean', mean) # 计算参数的标准差 with tf.name_scope('stddev'): stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean))) # 使用tf.summary.scaler记录下标准差,最大值,最小值 tf.summary.scalar('stddev', stddev) tf.summary.scalar('max', tf.reduce_max(var)) tf.summary.scalar('min', tf.reduce_min(var)) # 用直方图记录参数的分布 tf.summary.histogram('histogram', var) |
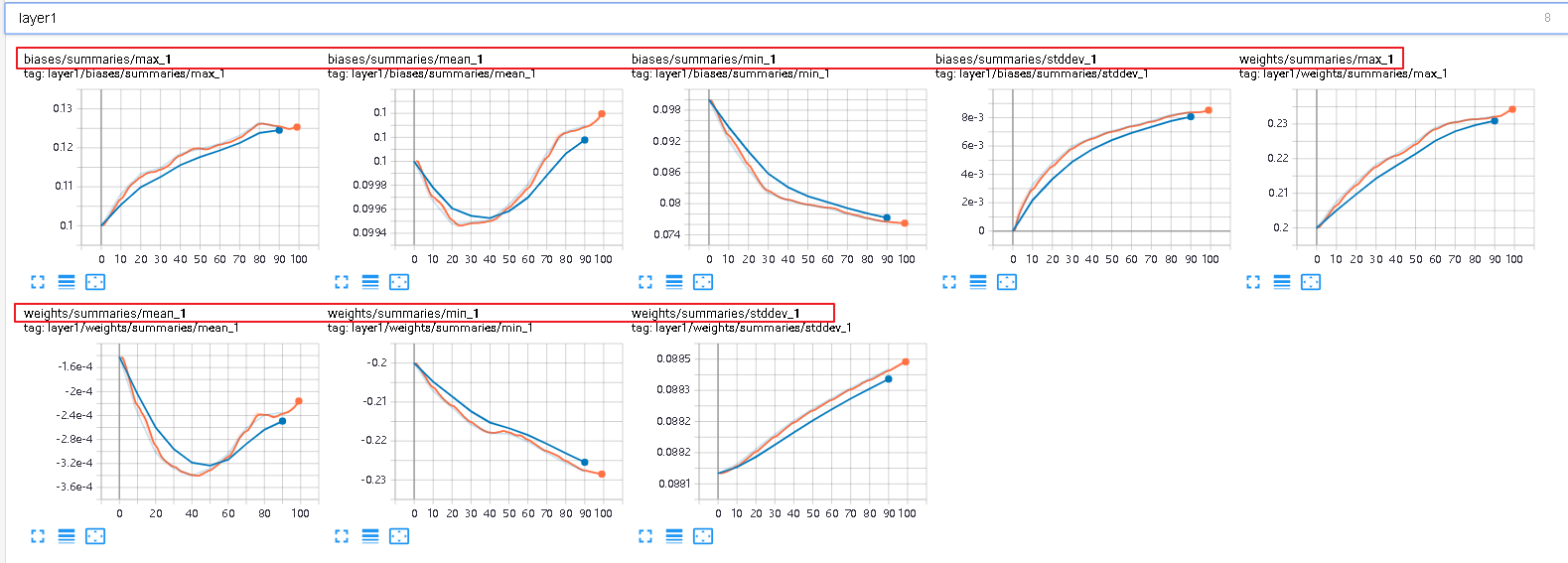
第一层的weight和biases的变化情况
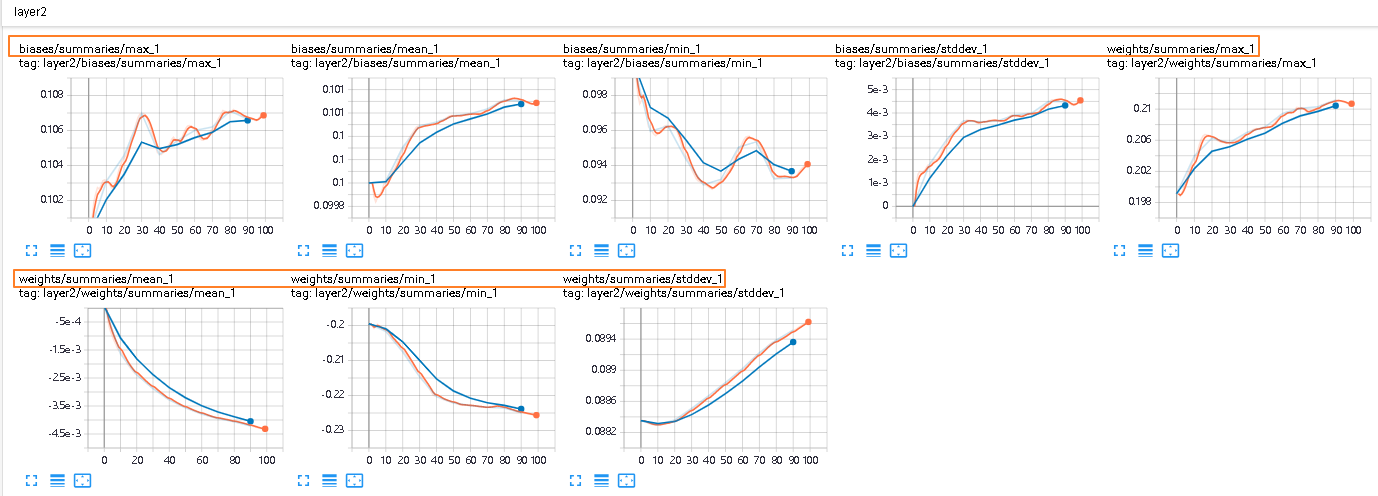
第二层的weight和biases的变化情况
3. 构建神经网络
下面是单层神经网络模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | # 构建神经网络def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu): # 设置命名空间 with tf.name_scope(layer_name): # 调用之前的方法初始化权重w,并且调用参数信息的记录方法,记录w的信息 with tf.name_scope('weights'): weights = weight_variable([input_dim, output_dim]) variable_summaries(weights) # 调用之前的方法初始化权重b,并且调用参数信息的记录方法,记录b的信息 with tf.name_scope('biases'): biases = bias_variable([output_dim]) variable_summaries(biases) # 执行wx+b的线性计算,并且用直方图记录下来 with tf.name_scope('linear_compute'): preactivate = tf.matmul(input_tensor, weights) + biases tf.summary.histogram('linear', preactivate) # 将线性输出经过激励函数,并将输出也用直方图记录下来 activations = act(preactivate, name='activation') tf.summary.histogram('activations', activations) # 返回激励层的最终输出 return activations |
下面要建双层神经网络,第一层加dropout
1 2 3 4 5 6 7 8 9 | hidden1 = nn_layer(x, 784, 500, 'layer1')# 创建dropout层with tf.name_scope('dropout'):keep_prob = tf.placeholder(tf.float32)tf.summary.scalar('dropout_keep_probability', keep_prob)dropped = tf.nn.dropout(hidden1, keep_prob)y = nn_layer(dropped, 500, 10, 'layer2', act=tf.identity) |
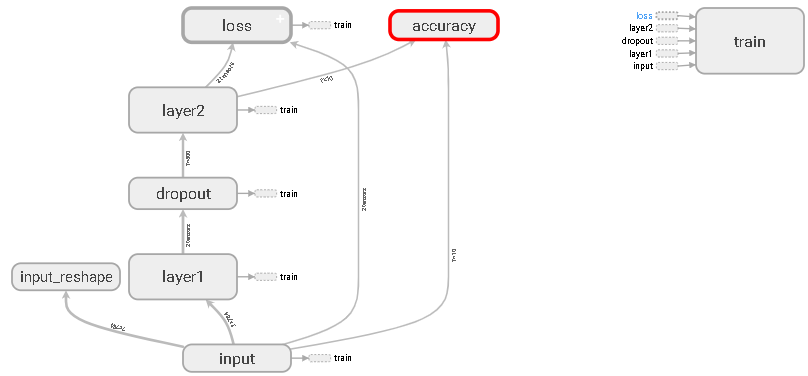
模型图如下:
dropout变化如下:

第一层和第二层的weights、bias、未激活前,激活后的值分布如下:

tf.summary.histogram接受任意大小和形状的张量,并将该张量压缩成一个由许多分箱组成的直方图数据结构,这些分箱有各种宽度和计数。例如,假设我们要将数字 [0.5, 1.1, 1.3, 2.2, 2.9, 2.99] 整理到不同的分箱中,我们可以创建三个分箱: * 一个分箱包含 0 到 1 之间的所有数字(会包含一个元素:0.5), * 一个分箱包含 1 到 2 之间的所有数字(会包含两个元素:1.1 和 1.3), * 一个分箱包含 2 到 3 之间的所有数字(会包含三个元素:2.2、2.9 和 2.99)。TensorFlow 使用类似的方法创建分箱,但与我们的示例不同,它不创建整数分箱。对于大型稀疏数据集,可能会导致数千个分箱。相反,这些分箱呈指数分布,许多分箱接近 0,有较少的分箱的数值较大。 然而,将指数分布的分箱可视化是非常艰难的。如果将高度用于为计数编码,那么即使元素数量相同,较宽的分箱所占的空间也越大。反过来推理,如果用面积为计数编码,则使高度无法比较。因此,直方图会将数据重新采样并分配到统一的分箱。很不幸,在某些情况下,这可能会造成假象。
直方图可视化工具中的每个切片显示单个直方图。切片是按步骤整理的;较早的切片(如,步骤 0)位于较“靠后”的位置,颜色也较深,而较晚的切片则靠近前景,颜色也较浅。右侧的 y 轴显示步骤编号。
举例:下图表示时间步骤76,对应的直方图的分箱位于0.0695附近,分箱中有712个元素

切换historm到覆盖模式
信息中心左侧有一个控件,可以将直方图模式从“偏移”切换到“覆盖”:在“偏移”模式下,可视化旋转 45 度,以便各个直方图切片不再按时间展开,而是全部绘制在相同的 y 轴上。
现在,每个切片都是图表上的一条单独线条,y 轴显示的是每个分箱内的项目数。颜色较深的线条表示较早的步,而颜色较浅的线条表示较晚的步。同样,可以将鼠标悬停在图表上以查看其他一些信息。

4. 损失函数+优化器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | # 创建损失函数with tf.name_scope('loss'): # 计算交叉熵损失(每个样本都会有一个损失) diff = tf.nn.softmax_cross_entropy_with_logits_v2(labels=y_, logits=y) with tf.name_scope('total'): # 计算所有样本交叉熵损失的均值 cross_entropy = tf.reduce_mean(diff) tf.summary.scalar('loss', cross_entropy) # 使用AdamOptimizer优化器训练模型,最小化交叉熵损失with tf.name_scope('train'): train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)# 计算准确率with tf.name_scope('accuracy'): with tf.name_scope('correct_prediction'): # 分别将预测和真实的标签中取出最大值的索引,弱相同则返回1(true),不同则返回0(false) correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) with tf.name_scope('accuracy'): # 求均值即为准确率 accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) tf.summary.scalar('accuracy', accuracy) |
5. 训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | sess = tf.Session()#summaries合并merged = tf.summary.merge_all()# 写到指定的磁盘路径中train_writer = tf.summary.FileWriter(log_dir + '/train', sess.graph)test_writer = tf.summary.FileWriter(log_dir + '/test',sess.graph)#运行初始化所有变量# global_variables_initializer().run()sess.run(tf.global_variables_initializer())def feed_dict(train): """Make a TensorFlow feed_dict: maps data onto Tensor placeholders.""" if train: xs, ys = mnist.train.next_batch(10) k = dropout else: xs, ys = mnist.test.images[:100], mnist.test.labels[:100] k = 1.0 return {x: xs, y_: ys, keep_prob: k}for i in range(100): if i % 10 == 0: #记录测试集的summary与accuracy summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False)) test_writer.add_summary(summary, i) print('Accuracy at step %s: %s' % (i, acc)) else: # 记录训练集的summary summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True)) train_writer.add_summary(summary, i)train_writer.close()test_writer.close() |
准确率:

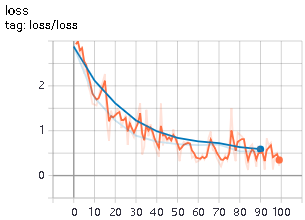
损失函数:
参考文献:
【1】莫烦Python


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现