
模型融合---LightGBM调参总结
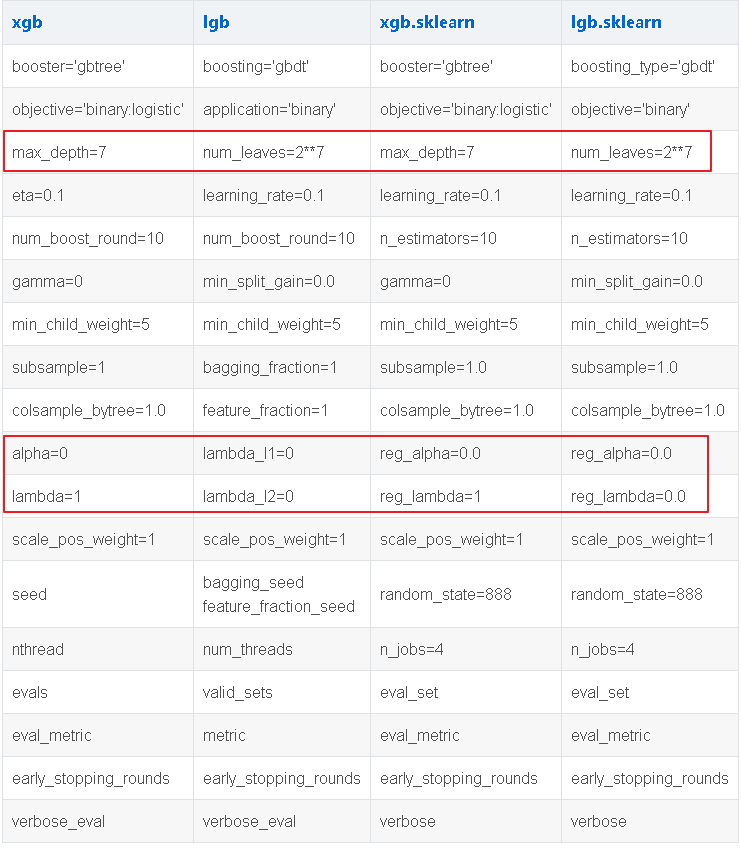
1. 参数速查

- 使用num_leaves,因为LightGBM使用的是leaf-wise的算法,因此在调节树的复杂程度时,使用的是num_leaves而不是max_depth。
- 大致换算关系:num_leaves = 2^(max_depth)。它的值的设置应该小于2^(max_depth),否则可能会导致过拟合。
- 对于非平衡数据集:可以param['is_unbalance']='true’
- Bagging参数:bagging_fraction+bagging_freq(必须同时设置)、feature_fraction。bagging_fraction可以使bagging的更快的运行出结果,feature_fraction设置在每次迭代中使用特征的比例。
- min_data_in_leaf:这也是一个比较重要的参数,调大它的值可以防止过拟合,它的值通常设置的比较大。
- max_bin:调小max_bin的值可以提高模型训练速度,调大它的值和调大num_leaves起到的效果类似。
2. 回归
3. 分类
先举个例子:
from sklearn.model_selection import train_test_split, StratifiedKFold
import lightgbm as lgb
# reg_alpha:L1正则,reg_lambda:L2正则
clf = lgb.LGBMClassifier(
boosting_type = 'gbdt', num_leaves = 64, reg_alpha = 5, reg_lambda = 5,
n_estimators = 4053, objective = 'binary',
subsample = 0.7, colsample_bytree = 0.7, subsample_freq = 1,
learning_rate = 0.05, random_state = 8012, n_jobs = -1)
clf.fit(train_data, labels, eval_set = [(train_data, labels)], verbose = 50)
test_result = clf.predict_proba(test_data)
test_data = all_data[all_data.label == -1].drop('label', axis = 1).reset_index(drop = True)
test_data['label'] = test_result[:, 1]
test_data['label'] = test_data.label.apply(lambda x:1 if x >= 0.36 else 0)
参考文献:
【1】LightGBM参数介绍

 浙公网安备 33010602011771号
浙公网安备 33010602011771号