
模型融合---GBDT调参总结
一、GBDT类库弱学习器参数


参数分为三类
第一类:Miscellaneous Parameters: Other parameters for overall functioning. 没啥用
第二类:Boosting Parameters: These affect the boosting operation in the model.
n_estimators 最大弱学习器的个数,太小欠拟合,太大过拟合
learning_rate 学习率,太大过拟合,一般很小0.1,和n_estimators一起调
subsample 子采样,防止过拟合,太小欠拟合。GBDT中是不放回采样
第三类:Tree-Specific Parameters: These affect each individual tree in the model.
max_features 最大特征数
max_depth 最大树深,太大过拟合
min_samples_split 内部节点再划分所需最小样本数,越大越防过拟合
min_weight_fraction_leaf 叶子节点最小的样本权重和。如果存在较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。越大越防过拟合
max_leaf_nodes:最大叶子节点数 ,太大过拟合
min_impurity_split:节点划分最小不纯度
presort:是否对数据进行预分类,以加快拟合中最佳分裂点的发现。默认False,适用于大数据集。小数据集使用True,可以加快训练。是否预排序,预排序可以加速查找最佳分裂点,对于稀疏数据不管用,Bool,auto:非稀疏数据则预排序,若稀疏数据则不预排序
接下来把调参的整个过程整理一下:
- 首先使用默认的参数,进行数据拟合;
- 从步长(learning rate)和迭代次数(n_estimators)入手;一般来说,开始选择一个较小的步长来网格搜索最好的迭代次数。这里,可以将步长初始值设置为0.1。对于迭代次数进行网格搜索;
- 接下来对决策树的参数进行寻优
- 首先我们对决策树最大深度max_depth和内部节点再划分所需最小样本数min_samples_split进行网格搜索。【min_samples_split暂时不能一起定下来,因为这个还和决策树其他的参数存在关联】
- 接着再对内部节点再划分所需最小样本数min_samples_split和叶子节点最少样本数min_samples_leaf一起调参;做到这里,min_samples_split要做两次网格寻优,一次是树的最大深度max_depth,一次是叶子节点最少样本数min_samples_leaf。 【具体观察min_samples_split的值是否落在边界上,如果是可以进一步寻优】
- 继续对最大特征数max_features进行网格搜索。做完这一步可以看看寻找出的最优参数组合给出的分类器的效果。
- 可以进一步考虑对子采样的比例进行网格搜索,得到subsample的寻优参数
- 回归到第2步调整设定的步长(learning rate)和迭代次数(n_estimators),注意两者的乘积保持不变,这里可以分析得到:通过减小步长可以提高泛化能力,但是步长设定过小,也会导致拟合效果反而变差,也就是说,步长不能设置的过小。
二、回归
数据集:已知用户的30个特征,预测用户的信用值

from sklearn.ensemble import GradientBoostingRegressor
from sklearn.grid_search import GridSearchCV
#用平均值填补缺失值
gbdt_train_label = train_data['信用分']
gbdt_train_data = train_data[columns_]
gbdt_test_data = test_data[columns_]
gbdt_train_data = gbdt_train_data.fillna(gbdt_train_data.mean())
gbdt_test_data = gbdt_test_data.fillna(gbdt_test_data.mean())
#填补6个月平均占比总费用为其他列的平均值
all_rows = list(gbdt_train_data.index)
inf_rows = list(gbdt_train_data.loc[gbdt_train_data['6个月平均占比总费用'] == float('inf')].index)
inf_mean = gbdt_train_data.ix[list(filter(lambda x: x not in inf_rows,all_rows))].mean()
gbdt_train_data['6个月平均占比总费用'][gbdt_train_data['6个月平均占比总费用'] == float('inf')] = inf_mean['6个月平均占比总费用']
1. 找树的数量最佳值
#找树的数量最佳值
param_gbdt = {'n_estimators':list(range(100,600,50))}
gbdt_search = GridSearchCV(estimator=GradientBoostingRegressor(learning_rate=0.1,min_samples_split=300,min_samples_leaf=20,
max_depth=8,max_features='sqrt',subsample=0.8,random_state=75),
param_grid=param_gbdt,scoring='neg_mean_squared_error',iid=False,cv=3)
gbdt_search.fit(gbdt_train_data,gbdt_train_label)
print(gbdt_search.grid_scores_)
print(gbdt_search.best_params_)
print(gbdt_search.best_score_)

2. 找树的深度最佳值
#找树的深度最佳值
param_gbdt1 = {'max_depth':[6,7,8,9,10]}
gbdt_search1 = GridSearchCV(estimator=GradientBoostingRegressor(learning_rate=0.1,n_estimators = 200,min_samples_split=300,
min_samples_leaf=20,max_features='sqrt',subsample=0.8,random_state=75),
param_grid=param_gbdt1,scoring='neg_mean_squared_error',iid=False,cv=5)
gbdt_search1.fit(gbdt_train_data,gbdt_train_label)
print(gbdt_search1.grid_scores_)
print(gbdt_search1.best_params_)
print(gbdt_search1.best_score_)

3. 找min_samples_split,min_samples_leaf最佳值
#找min_samples_split,min_samples_leaf最佳值
param_gbdt2 = {'min_samples_split':[500,700,900,1100],
'min_samples_leaf':[30,50,70,90]}
gbdt_search2 = GridSearchCV(estimator=GradientBoostingRegressor(learning_rate=0.1,n_estimators = 100,max_depth=6,
max_features='sqrt',subsample=0.8,random_state=75),n_jobs=3,
param_grid=param_gbdt2,scoring='neg_mean_squared_error',iid=False,cv=5)
gbdt_search2.fit(gbdt_train_data,gbdt_train_label)
print(gbdt_search2.grid_scores_)
print(gbdt_search2.best_params_)
print(gbdt_search2.best_score_)

4. 粗调完成,得到了上述参数的最佳大致范围,接下来,可以进行细调,就是在上述最佳参数附近范围进行搜索,这里就只对n_estimators和学习率进行调整
param_gbdt3 = {'learning_rate':[0.06,0.08,0.1],
'n_estimators':[100,150,200,250]}
gbdt_search3 = GridSearchCV(estimator=GradientBoostingRegressor(min_samples_split=700,min_samples_leaf=70,
max_depth=9,max_features='sqrt',subsample=0.8,random_state=75),n_jobs=3,
param_grid=param_gbdt3,scoring='neg_mean_squared_error',iid=False,cv=5)
gbdt_search3.fit(gbdt_train_data,gbdt_train_label)
print(gbdt_search3.grid_scores_)
print(gbdt_search3.best_params_)
print(gbdt_search3.best_score_)

可以看到,最佳学习率为 0.06,提升树数量为250 ;此时r2提升到0.7907 。
三、分类
前提:假设数据已经处理完毕,现在开始训练。
modelfit函数包含训练,测试,交叉验证,输出accuracy和AUC,画出重要特征的功能
def modelfit(alg, dtrain, dtest, predictors, performCV=True, printFeatureImportance=True, cv_folds=5):
'''
alg是分类器,dtrain是训练集(包括label),dtes是测试集,predictors是除了label和ID的其他特征,performCV指是否要交叉验证
'''
#训练训练集
alg.fit(dtrain[predictors], dtrain['Disbursed']) #predictors是除了待预测的其他特征,Distursed是目标特征
#预测测试集
dtrain_predictions = alg.predict(dtrain[predictors])
dtrain_predprob = alg.predict_proba(dtrain[predictors])[:,1]
#交叉验证
if performCV:
cv_score = cross_validation.cross_val_score(alg, dtrain[predictors], dtrain['Disbursed'], cv=cv_folds, scoring='roc_auc')
#输出模型的accuracy、AUC
print("\nModel Report")
print("Accuracy : %.4g" % metrics.accuracy_score(dtrain['Disbursed'].values, dtrain_predictions))
print("AUC Score (Train): %f" % metrics.roc_auc_score(dtrain['Disbursed'], dtrain_predprob))
if performCV:#如果选了要交叉验证,就输出交叉验证的平均值,标准差,最小值,最大值
print("CV Score : Mean - %.7g | Std - %.7g | Min - %.7g | Max - %.7g" % (np.mean(cv_score),np.std(cv_score),np.min(cv_score),np.max(cv_score)))
#画出重要特征图像
if printFeatureImportance:
feat_imp = pd.Series(alg.feature_importances_, predictors).sort_values(ascending=False)
feat_imp.plot(kind='bar', title='Feature Importances')
plt.ylabel('Feature Importance Score')
接着就要创建一个基线模型(baseline model)。这里我们用AUC来作为衡量标准,所以用常数的话AUC就是0.5。一般来说用默认参数设置的GBM模型就是一个很好的基线模型,我们来看看这个模型的输出和特征重要性:
#Choose all predictors except target & IDcols
predictors = [x for x in train.columns if x not in [target, IDcol]]
gbm0 = GradientBoostingClassifier(random_state=10)
modelfit(gbm0, train, test, predictors,printOOB=False)
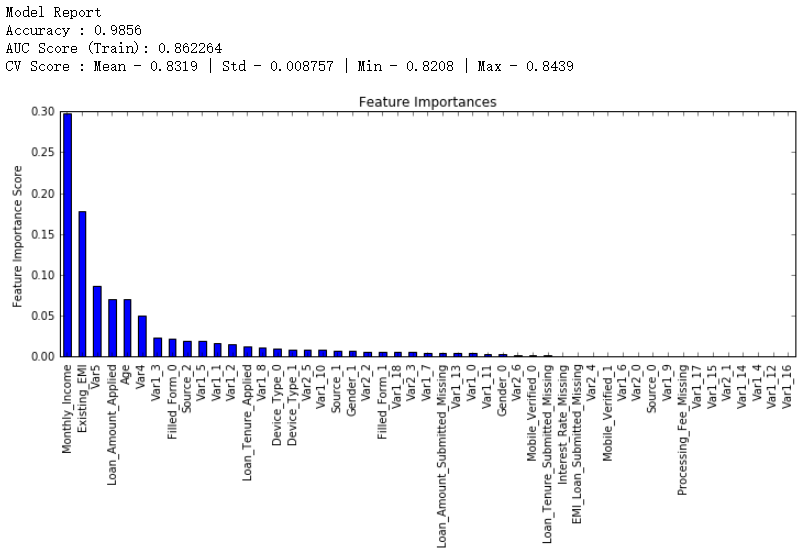
从图上看出,CV的平均值是0.8319,后面调整的模型会做得比这个更好
GBDT主要有两种类型的参数:
Tree-specific parameters:
- min_samples_split
- min_samples_leaf
- max_depth
- min_leaf_nodes
- max_features
- loss function
Boosting specific paramters:
- n_estimators
- learning_rate
- subsample
参数调节的一般方法:树参数和boosting参数。learning rate没有什么特别的调节方法,因为只要我们训练的树足够多learning rate总是小值来得好。
虽然随着决定树的增多GBM并不会明显得过度拟合,高learing rate还是会导致这个问题,但如果我们一味地减小learning rate、增多树,计算就会非常昂贵而且需要运行很长时间。了解了这些问题,我们决定采取以下方法调参:
(1)选择一个相对来说稍微高一点的learning rate。一般默认的值是0.1,不过针对不同的问题,0.05到0.2之间都可以
(2)决定当前learning rate下最优的决定树数量。它的值应该在40-70之间。记得选择一个你的电脑还能快速运行的值,因为之后这些树会用来做很多测试和调参。
(3)接着调节树参数来调整learning rate和树的数量。我们可以选择不同的参数来定义一个决定树,后面会有这方面的例子
(4)降低learning rate,同时会增加相应的决定树数量使得模型更加稳健
1. 固定 learning rate和需要估测的决定树数量
为了决定boosting参数,我们得先设定一些参数的初始值,可以像下面这样:
- min_ samples_ split=500: 这个值应该在总样本数的0.5-1%之间,由于我们研究的是不均等分类问题,我们可以取这个区间里一个比较小的数,500。
- min_ samples_ leaf=50: 可以凭感觉选一个合适的数,只要不会造成过度拟合。同样因为不均等分类的原因,这里我们选择一个比较小的值。
- max_ depth=8: 根据观察数和自变量数,这个值应该在5-8之间。这里我们的数据有87000行,49列,所以我们先选深度为8。
- max_ features=’sqrt’: 经验上一般都选择平方根。
- subsample=0.8: 开始的时候一般就用0.8
注意我们目前定的都是初始值,最终这些参数的值应该是多少还要靠调参决定。现在我们可以根据learning rate的默认值0.1来找到所需要的最佳的决定树数量,可以利用网格搜索(grid search)实现,以10个数递增,从20测到80。
#Choose all predictors except target & IDcols
predictors = [x for x in train.columns if x not in [target, IDcol]]
param_test1 = {'n_estimators':range(20,81,10)}
gsearch1 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, min_samples_split=500,
min_samples_leaf=50,max_depth=8,max_features='sqrt', subsample=0.8,random_state=10),
param_grid = param_test1, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch1.fit(train[predictors],train[target])

gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_

可以看出对于0.1的learning rate, 60个树是最佳的,而且60也是一个合理的决定树数量,所以我们就直接用60。但在一些情况下上面这段代码给出的结果可能不是我们想要的,比如:
- 如果给出的输出是20,可能就要降低我们的learning rate到0.05,然后再搜索一遍。
- 如果输出值太高,比如100,因为调节其他参数需要很长时间,这时候可以把learniing rate稍微调高一点。
2. 调节树参数
树参数可以按照这些步骤调节:
- 调节max_depth和
num_samples_split 调节min_samples_leaf- 调节max_features
需要注意一下调参顺序,对结果影响最大的参数应该优先调节,就像max_depth和num_samples_split。
重要提示:接着我会做比较久的网格搜索(grid search),可能会花上15-30分钟。你在自己尝试的时候应该根据电脑情况适当调整需要测试的值。
max_depth可以相隔两个数从5测到15,而min_samples_split可以按相隔200从200测到1000。这些完全凭经验和直觉,如果先测更大的范围再用迭代去缩小范围也是可行的。
#Grid seach on subsample and max_features
param_test2 = {'max_depth':range(5,16,2), 'min_samples_split':range(200,1001,200)}
gsearch2 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, n_estimators=60,
max_features='sqrt', subsample=0.8, random_state=10),
param_grid = param_test2, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch2.fit(train[predictors],train[target])

gsearch2.grid_scores_, gsearch2.best_params_, gsearch2.best_score_

从结果可以看出,我们从30种组合中找出最佳的max_depth是9,而最佳的min_smaples_split是1000。1000是我们设定的范围里的最大值,有可能真正的最佳值比1000还要大,所以我们还要继续增加min_smaples_split。树深就用9。接着就来调节min_samples_leaf,可以测30,40,50,60,70这五个值,同时我们也试着调大min_samples_split的值。
#Grid seach on subsample and max_features
param_test3 = {'min_samples_split':range(1000,2100,200), 'min_samples_leaf':range(30,71,10)}
gsearch3 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, n_estimators=60,max_depth=9,
max_features='sqrt', subsample=0.8, random_state=10),
param_grid = param_test3, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch3.fit(train[predictors],train[target])

gsearch3.grid_scores_, gsearch3.best_params_, gsearch3.best_score_

这样min_samples_split的最佳值是1200,而min_samples_leaf的最佳值是60。注意现在CV值增加到了0.8396。现在我们就根据这个结果来重新建模,并再次评估特征的重要性。
modelfit(gsearch3.best_estimator_, train, test, predictors)
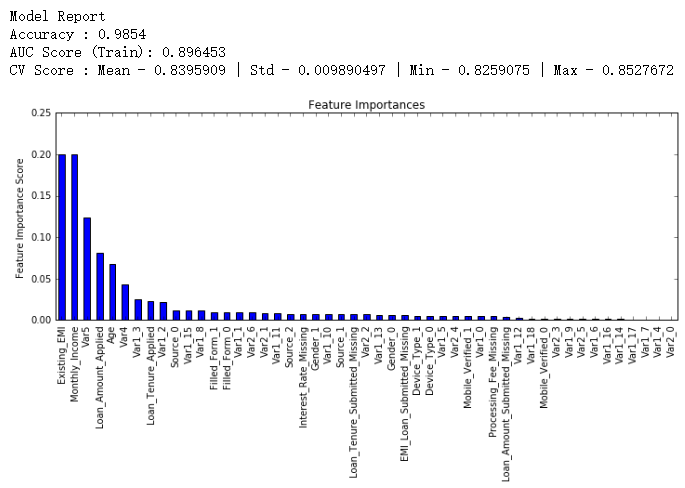
比较之前的基线模型结果可以看出,现在我们的模型用了更多的特征,并且基线模型里少数特征的重要性评估值过高,分布偏斜明显,现在分布得更加均匀了。
接下来就剩下最后的树参数max_features了,可以每隔两个数从7测到19。
#Grid seach on subsample and max_features
param_test4 = {'max_features':range(7,20,2)}
gsearch4 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, n_estimators=60,max_depth=9,
min_samples_split=1200, min_samples_leaf=60, subsample=0.8, random_state=10),
param_grid = param_test4, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch4.fit(train[predictors],train[target])

gsearch4.grid_scores_, gsearch4.best_params_, gsearch4.best_score_

最佳的结果是7,正好就是我们设定的初始值(平方根)。当然你可能还想测测小于7的值,鼓励这么做。而按照我们的设定,现在的树参数是这样的:
min_samples_split: 1200min_samples_leaf: 60max_depth: 9max_features: 7
3. 调节子样本比例来降低learning rate
接下来就可以调节子样本占总样本的比例,我准备尝试这些值:0.6,0.7,0.75,0.8,0.85,0.9。
#Grid seach on subsample and max_features
param_test5 = {'subsample':[0.6,0.7,0.75,0.8,0.85,0.9]}
gsearch5 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, n_estimators=60,max_depth=9,
min_samples_split=1200, min_samples_leaf=60, subsample=0.8, random_state=10, max_features=7),
param_grid = param_test5, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch5.fit(train[predictors],train[target])

gsearch5.grid_scores_, gsearch5.best_params_, gsearch5.best_score_
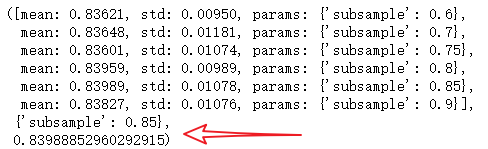
给出的结果是0.85。这样所有的参数都设定好了,现在我们要做的就是进一步减少learning rate,就相应地增加了树的数量。需要注意的是树的个数是被动改变的,可能不是最佳的,但也很合适。随着树个数的增加,找到最佳值和CV的计算量也会加大,为了看出模型执行效率,我还提供了我每个模型在比赛的排行分数(leaderboard score),怎么得到这个数据不是公开的,你很难重现这个数字,它只是为了更好地帮助我们理解模型表现。
现在我们先把learning rate降一半,至0.05,这样树的个数就相应地加倍到120。
#Choose all predictors except target & IDcols
predictors = [x for x in train.columns if x not in [target, IDcol]]
gbm_tuned_1 = GradientBoostingClassifier(learning_rate=0.05, n_estimators=120,max_depth=9, min_samples_split=1200,
min_samples_leaf=60, subsample=0.85, random_state=10, max_features=7)
modelfit(gbm_tuned_1, train, test, predictors)
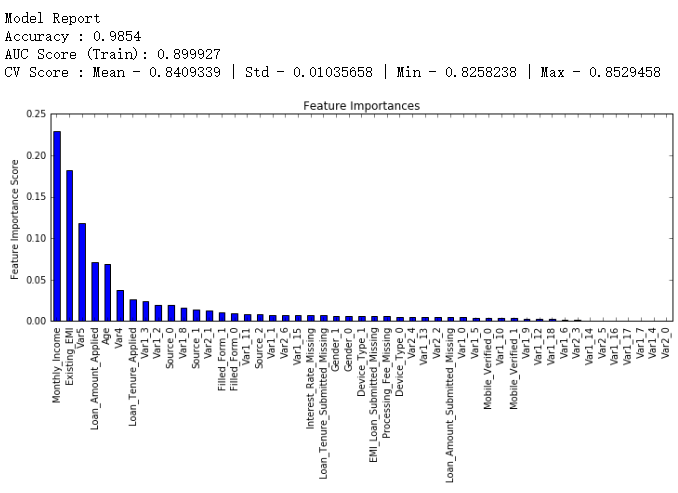
接下来我们把learning rate进一步减小到原值的十分之一,即0.01,相应地,树的个数变为600。
#Choose all predictors except target & IDcols
predictors = [x for x in train.columns if x not in [target, IDcol]]
gbm_tuned_2 = GradientBoostingClassifier(learning_rate=0.01, n_estimators=600,max_depth=9, min_samples_split=1200,
min_samples_leaf=60, subsample=0.85, random_state=10, max_features=7)
modelfit(gbm_tuned_2, train, test, predictors)
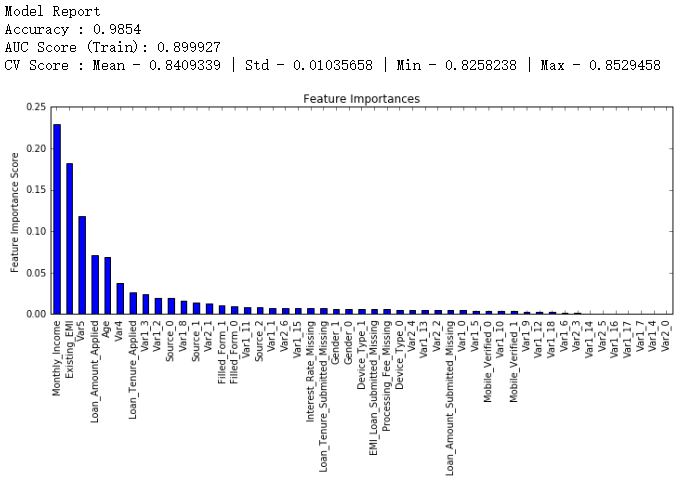
继续把learning rate缩小至二十分之一,即0.005,这时候我们有1200个树。
#Choose all predictors except target & IDcols
predictors = [x for x in train.columns if x not in [target, IDcol]]
gbm_tuned_3 = GradientBoostingClassifier(learning_rate=0.005, n_estimators=1200,max_depth=9, min_samples_split=1200,
min_samples_leaf=60, subsample=0.85, random_state=10, max_features=7,
warm_start=True)
modelfit(gbm_tuned_3, train, test, predictors, performCV=False)
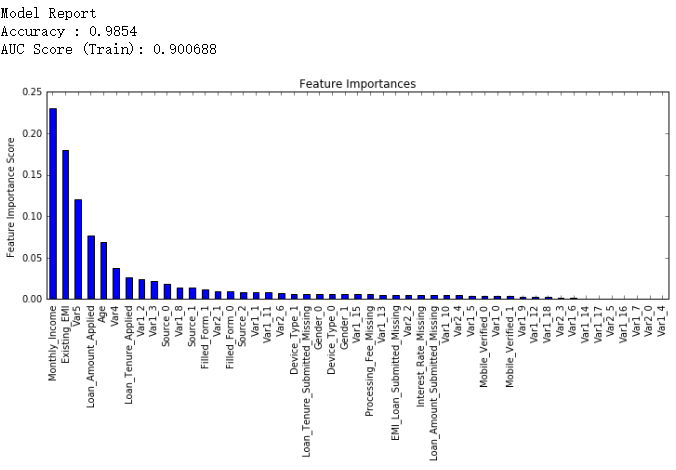
排行得分稍微降低了,我们停止减少learning rate,只单方面增加树的个数,试试1500个树。
#Choose all predictors except target & IDcols
predictors = [x for x in train.columns if x not in [target, IDcol]]
gbm_tuned_4 = GradientBoostingClassifier(learning_rate=0.005, n_estimators=1500,max_depth=9, min_samples_split=1200,
min_samples_leaf=60, subsample=0.85, random_state=10, max_features=7,
warm_start=True)
modelfit(gbm_tuned_4, train, test, predictors, performCV=False)
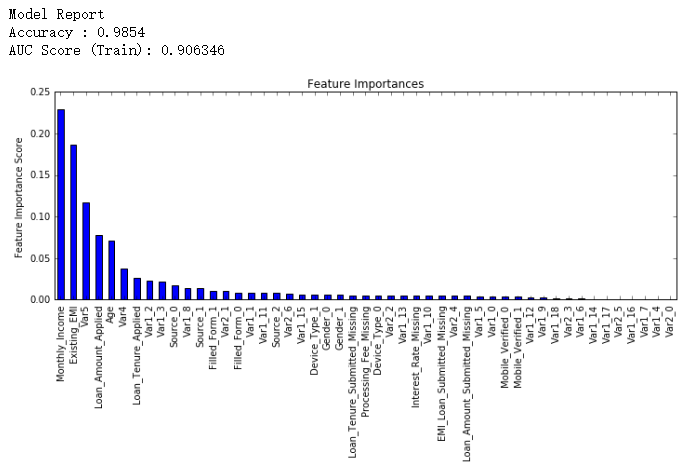
还有一个技巧就是用“warm_start”选项。这样每次用不同个数的树都不用重新开始
参考文献:
【1】scikit-learn 梯度提升树(GBDT)调参小结
【2】Gradient Boosting Machine(GBM)调参方法详解
【3】https://github.com/aarshayj/Analytics_Vidhya/tree/master/Articles

 浙公网安备 33010602011771号
浙公网安备 33010602011771号