
22(6).模型融合---LightGBM
一、LightGBM简介:
- 所属:boosting迭代型、树类算法
- 适用范围:回归/分类/排序
- LightGBM工具包:lightGBM英文文档 | lightGBM中文文档
- 论文链接
- 优点:
- 基于Histogram的决策树算法
- 带深度限制的Leaf-wise的叶子生长策略
- 直方图做差加速
- 直接支持类别特征(Categorical Feature)
- Cache命中率优化
- 基于直方图的稀疏特征优化
- 多线程优化
LightGBM提出的主要原因是为了解决GBDT在海量数据遇到的问题,让GBDT可以更好更快地用于工业实践。
二、XGboost缺点
XGboost的不足之处主要有:
1.精确贪心算法
每轮迭代时,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。
优点:可以找到精确的划分条件
缺点:
- 计算量巨大;
- 内存占用巨大;
- 易产生过拟合
2.预排序方法(pre-sorted)
首先,空间消耗大。这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如排序后的索引,为了后续快速的计算分割点),这里需要消耗训练数据两倍的内存。其次时间上也有较大的开销,在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
优点:
- 可以使用多线程
- 可以加速精确贪心算法
缺点:效率低下,可能产生不必要的叶结点
3.level-wise
生成决策树是level-wise级别的,也就是预先设置好树的深度之后,每一颗树都需要生长到设置的那个深度,这样有些树在某一次分裂之后效果甚至没有提升但仍然会继续划分树枝,然后再次划分....之后就是无用功了,耗时。
4.对cache优化不友好
在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
三、LightGBM对Xgboost的优化
1.基于Histogram的决策树算法
思想:将连续的浮点特征离散成k个离散值,具体过程是首先确定对于每一个特征需要多少的桶bin,然后均分,将属于该桶的样本数据更新为bin的值,最后用直方图表示。在进行特征选择时,只需要根据直方图的离散值,遍历寻找最优的分割点。
使用直方图算法有很多优点。首先最明显就是内存消耗的降低,直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8。
然后在计算上的代价也大幅降低,预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次(k可以认为是常数),时间复杂度从O(#data*#feature)优化到O(k*#features)。
Histogram算法有几个需要注意的地方:
- 使用bin替代原始数据相当于增加了正则化;
- 使用bin意味着很多数据的细节特征被放弃了,相似的数据可能被划分到相同的桶中,这样的数据之间的差异就消失了;
- bin数量选择决定了正则化的程度,bin越少惩罚越严重,欠拟合风险越高。
- 构建直方图时不需要对数据进行排序(比XGBoost快),因为预先设定了bin的范围;
- 直方图除了保存划分阈值和当前bin内样本数以外还保存了当前bin内所有样本的一阶梯度和(一阶梯度和的平方的均值等价于均方损失);
- 阈值的选取是按照直方图从小到大遍历,使用了上面的一阶梯度和,目的是得到划分之后△loss最大的特征及阈值。
Histogram算法的优缺点:
- Histogram算法并不是完美的。由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但在实际的数据集上表明,离散化的分裂点对最终的精度影响并不大,甚至会好一些。原因在于decision tree本身就是一个弱学习器,采用Histogram算法会起到正则化的效果,有效地防止模型的过拟合。
- 时间上的开销由原来的O(#data * #features)降到O(k * #features)。由于离散化,#bin远小于#data,因此时间上有很大的提升。
Histogram算法还可以进一步加速:
- 一个叶子节点的Histogram可以直接由父节点的Histogram和兄弟节点的Histogram做差得到。一般情况下,构造Histogram需要遍历该叶子上的所有数据,通过该方法,只需要遍历Histogram的k个捅。速度提升了一倍。
2.带深度限制的Leaf-wise的叶子生长策略
在Histogram算法之上,LightGBM进行进一步的优化。首先它抛弃了大多数GBDT工具使用的按层生长 (level-wise)的决策树生长策略,而使用了带有深度限制的按叶子生长 (leaf-wise)算法。
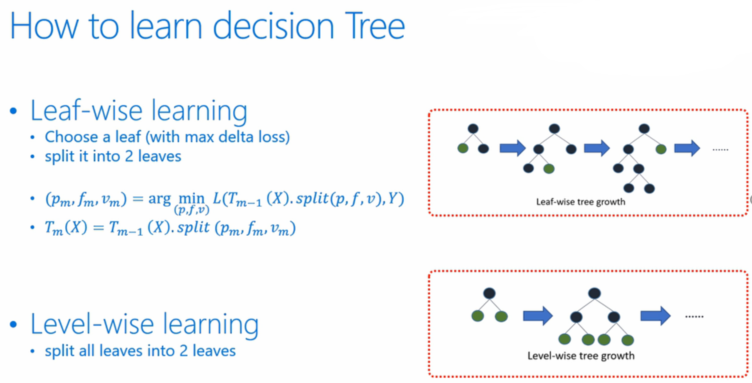
XGBoost采用的是按层生长level(depth)-wise生长策略,能够同时分裂同一层的叶子,从而进行多线程优化,不容易过拟合;但不加区分的对待同一层的叶子,带来了很多没必要的开销。因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
LightGBM采用leaf-wise生长策略,每次从当前所有叶子中找到分裂增益最大(一般也是数据量最大)的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
3.直方图做差加速
一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。利用这个方法,LightGBM可以在构造一个叶子的直方图后,可以用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍。

4.直接支持类别特征
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化one-hot特征,降低了空间和时间的效率。而类别特征的使用是在实践中很常用的。基于这个考虑,LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1展开。并在决策树算法上增加了类别特征的决策规则。
one-hot编码是处理类别特征的一个通用方法,然而在树模型中,这可能并不一定是一个好的方法,尤其当类别特征中类别个数很多的情况下。主要的问题是:
- 可能无法在这个类别特征上进行切分(即浪费了这个特征)。使用one-hot编码的话,意味着在每一个决策节点上只能使用one vs rest(例如是不是狗,是不是猫等)的切分方式。当类别值很多时,每个类别上的数据可能会比较少,这时候切分会产生不平衡,这意味着切分增益也会很小(比较直观的理解是,不平衡的切分和不切分没有区别)。
- 会影响决策树的学习。因为就算可以在这个类别特征进行切分,也会把数据切分到很多零碎的小空间上,如图1左边所示。而决策树学习时利用的是统计信息,在这些数据量小的空间上,统计信息不准确,学习会变差。但如果使用下图右边的分裂方式,数据会被切分到两个比较大的空间,进一步的学习也会更好。
下图右边叶子节点的含义是X=A或者X=C放到左孩子,其余放到右孩子。
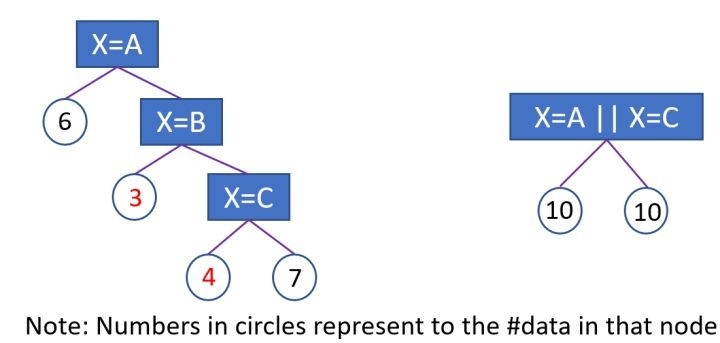
具体实现方法:
为了解决one-hot编码处理类别特征的不足。LightGBM采用了Many vs many的切分方式,实现了类别特征的最优切分。用LightGBM可以直接输入类别特征,并产生上图右边的效果。在1个k维的类别特征中寻找最优切分,朴素的枚举算法的复杂度是,而LightGBM采用了如On Grouping For Maximum Homogeneity的方法实现了的算法。
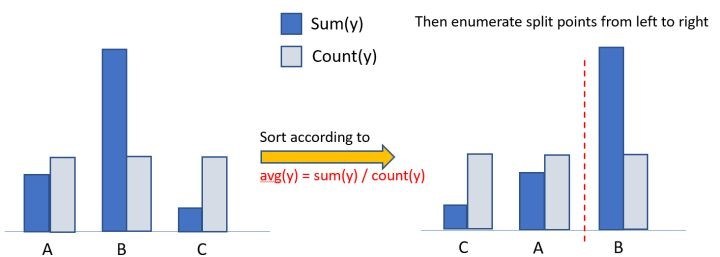
算法流程下图所示:在枚举分割点之前,先把直方图按每个类别的均值进行排序;然后按照均值的结果依次枚举最优分割点。从下图可以看到,Sum(y)/Count(y)为类别的均值。当然,这个方法很容易过拟合,所以在LGBM中加入了很多对这个方法的约束和正则化。
- 离散特征建立直方图的过程:统计该特征下每一种离散值出现的次数,并从高到低排序,并过滤掉出现次数较少的特征值, 然后为每一个特征值,建立一个bin容器, 对于在bin容器内出现次数较少的特征值直接过滤掉,不建立bin容器。
- 计算分裂阈值的过程:
- 先看该特征下划分出的bin容器的个数,如果bin容器的数量小于4,直接使用one vs other方式, 逐个扫描每一个bin容器,找出最佳分裂点;
- 对于bin容器较多的情况, 先进行过滤,只让子集合较大的bin容器参加划分阈值计算, 对每一个符合条件的bin容器进行公式计算(公式如下: 该bin容器下所有样本的一阶梯度之和/该bin容器下所有样本的二阶梯度之和 + 正则项(参数cat_smooth),这里为什么不是label的均值呢?其实上例中只是为了便于理解,只针对了学习一棵树且是回归问题的情况, 这时候一阶导数是Y, 二阶导数是1),得到一个值,根据该值对bin容器从小到大进行排序,然后分从左到右、从右到左进行搜索,得到最优分裂阈值。但是有一点,没有搜索所有的bin容器,而是设定了一个搜索bin容器数量的上限值,程序中设定是32,即参数max_num_cat。LightGBM中对离散特征实行的是many vs many 策略,这32个bin中最优划分的阈值的左边或者右边所有的bin容器就是一个many集合,而其他的bin容器就是另一个many集合。
- 对于连续特征,划分阈值只有一个,对于离散值可能会有多个划分阈值,每一个划分阈值对应着一个bin容器编号,当使用离散特征进行分裂时,只要数据样本对应的bin容器编号在这些阈值对应的bin集合之中,这条数据就加入分裂后的左子树,否则加入分裂后的右子树。
5.Cache命中率优化
6.基于直方图的稀疏特征优化
7.多线程优化
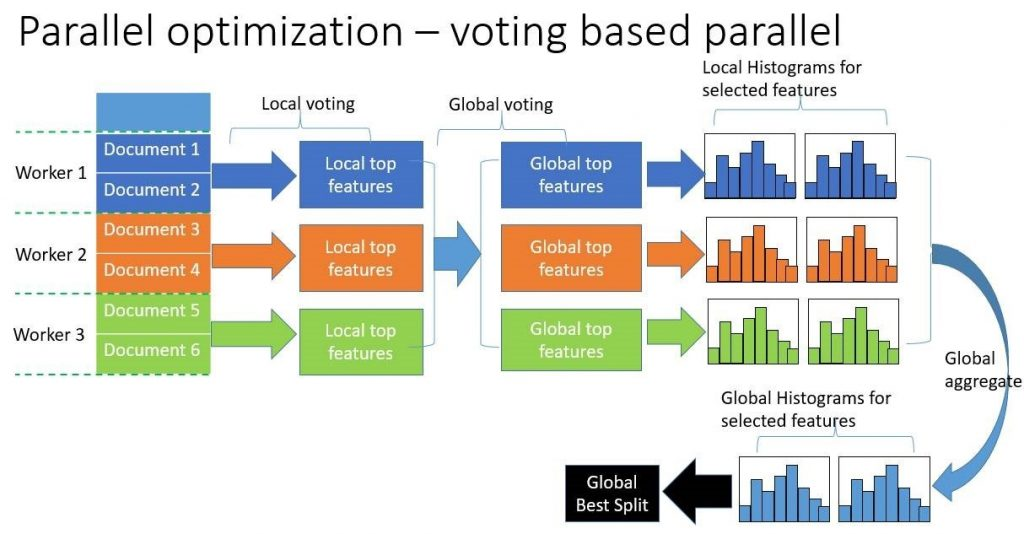
LightGBM原生支持并行学习,目前支持特征并行和数据并行的两种。特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。

LightGBM针对这两种并行方法都做了优化,在特征并行算法中,通过在本地保存全部数据避免对数据切分结果的通信;在数据并行中使用分散规约(Reduce scatter)把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减少了一半的通信量。
基于投票的数据并行则进一步优化数据并行中的通信代价,使通信代价变成常数级别。在数据量很大的时候,使用投票并行可以得到非常好的加速效果。
四、LightGBM原理
为了能够在不损害准确率的条件下加快GBDT模型的训练速度,lightGBM在传统的GBDT算法上加了两个技术:
- 单边梯度采样 Gradient-based One-Side Sampling (GOSS):排除大部分小梯度的样本,仅用剩下的样本计算信息增益。
- 互斥稀疏特征绑定Exclusive Feature Bundling (EFB):从减少特征角度
GBDT虽然没有数据权重,但每个数据实例有不同的梯度,根据计算信息增益的定义,梯度大的实例对信息增益有更大的影响,因此在下采样时,我们应该尽量保留梯度大的样本(预先设定阈值,或者最高百分位间),随机去掉梯度小的样本。我们证明此措施在相同的采样率下比随机采样获得更准确的结果,尤其是在信息增益范围较大时。
捆绑互斥特征,也就是他们很少同时取非零值(也就是用一个合成特征代替)。通常应用中,虽然特征量比较多,但是由于特征空间十分稀疏,是否可以设计一种无损的方法来减少有效特征呢?特别在稀疏特征空间上,许多特征几乎是互斥的(例如许多特征不会同时为非零值,像one-hot),我们可以捆绑互斥的特征。最后,我们将捆绑问题归约到图着色问题,通过贪心算法求得近似解。
1. Gradient-based One-Side Sampling(GOSS)
GOSS在进行数据采样的时候只保留了梯度较大的数据,但是如果直接将所有梯度较小的数据都丢弃掉势必会影响数据的总体分布.为了抵消对数据分布的影响,计算信息增益的时候,GOSS对小梯度的数据引入常量乘数。GOSS首先根据数据的梯度绝对值排序,选取top a个实例。然后在剩余的数据中随机采样b个实例。接着计算信息增益时为采样出的小梯度数据乘以(1-a)/b,这样算法就会更关注训练不足的实例,而不会过多改变原数据集的分布。
- 首先根据数据的梯度将训练降序排序。
- 保留top a个数据实例,作为数据子集A。
- 对于剩下的数据的实例,随机采样获得大小为b的数据子集B。
- 最后我们通过以下方程估计信息增益:
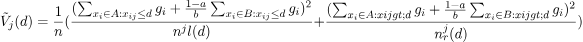

2. Exclusive Feature Bundling(EFB)
EFB是通过特征捆绑的方式减少特征维度(其实是降维技术)的方式,来提升计算效率。通常被捆绑的特征都是互斥的(一个特征值为零,一个特征值不为零),这样两个特征捆绑起来才不会丢失信息。如果两个特征并不是完全互斥(部分情况下两个特征都是非零值),可以用一个指标对特征不互斥程度进行衡量,称之为冲突比率,当这个值较小时,我们可以选择把不完全互斥的两个特征捆绑,而不影响最后的精度。
EBF的算法步骤如下:
- 将特征按照非零值的个数进行排序
- 计算不同特征之间的冲突比率
- 遍历每个特征并尝试合并特征,使冲突比率最小化
高位的数据通常是稀疏的,这种稀疏性启发我们设计一种无损地方法来减少特征的维度。特别的,稀疏特征空间中,许多特征是互斥的,例如他们从不同时为非零值。我们可以绑定互斥的特征为单一特征,通过仔细设计特征臊面算法,我们从特征捆绑中构建了与单个特征相同的特征直方图。这种方式的间直方图时间复杂度从O(#data * #feature)降到O(#data * #bundle),由于#bundle << # feature,我们能够极大地加速GBDT的训练过程而且损失精度。
有两个问题:
- 怎么判定那些特征应该绑在一起(build bundled)?
- 怎么把特征绑为一个(merge feature)?
理论1:将特征分割为较小量的互斥特征群是NP难的
bundle(什么样的特征被绑定)算法流程:
- 建立一个图,每个点代表特征,每个边有权重,其权重和特征之间总体冲突相关。
- 按照降序排列图中的度数来排序特征。
- 检查排序之后的每个特征,对他进行特征绑定或者建立新的绑定使得操作之后的总体冲突最小。
merging features(特征合并):
如何合并同一个bundle的特征来降低训练时间复杂度。关键在于原始特征值可以从bundle中区分出来。鉴于直方图算法存储离散值而不是连续特征值,我们通过将互斥特征放在不同的箱中来构建bundle。这可以通过将偏移量添加到特征原始值中实现,例如,假设bundle中有两个特征,原始特征A取值[0, 10],B取值[0, 20]。我们添加偏移量10到B中,因此B取值[10, 30]。通过这种做法,就可以安全地将A、B特征合并,使用一个取值[0, 30]的特征取代AB。
EFB算法能够将许多互斥的特征变为低维稠密的特征,就能够有效的避免不必要0值特征的计算。实际,通过用表记录数据中的非零值,来忽略零值特征,达到优化基础的直方图算法。通过扫描表中的数据,建直方图的时间复杂度将从O(#data)降到O(#non_zero_data)。当然,这种方法在构建树过程中需要而额外的内存和计算开销来维持预特征表。我们在lightGBM中将此优化作为基本函数,因为当bundles是稀疏的时候,这个优化与EFB不冲突(可以用于EFB)

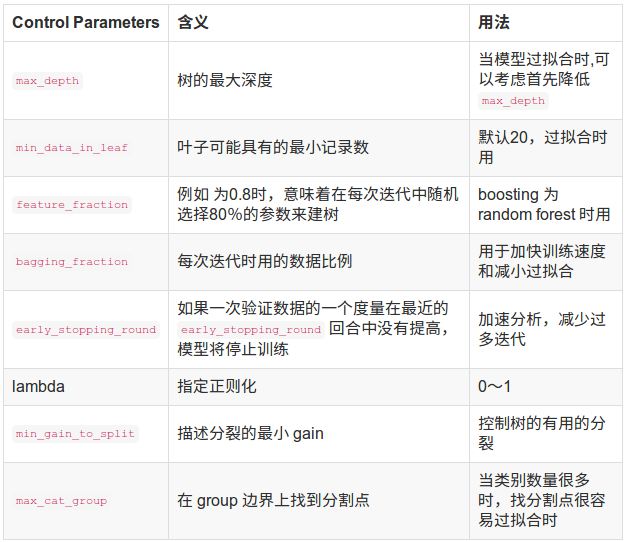
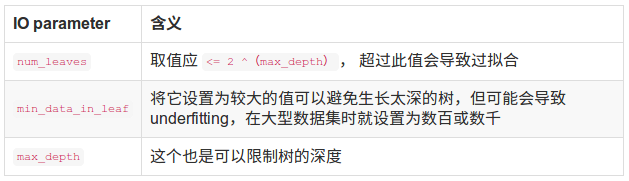
五、LightGBM参数调优
下面几张表为重要参数的含义和如何应用


接下来是调参
下表对应了Faster Spread,better accuracy,over-fitting三种目的时,可以调整的参数

参考文献:
【3】LightGBM——提升机器算法(图解+理论+安装方法+python代码)
【4】https://www.bilibili.com/video/av47496956?from=search&seid=11905257687121452350


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现