
sklearn---线性回归
1. 普通线性回归 Linear Regression

(1)目标:
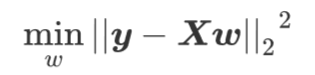

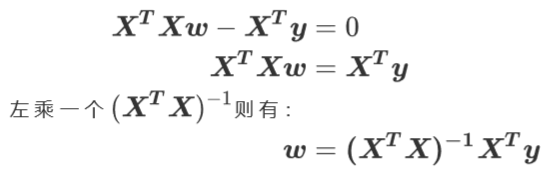
1 | class sklearn.linear_model.LinearRegression (fit_intercept=True, normalize=False, copy_X=True, n_jobs=None) |
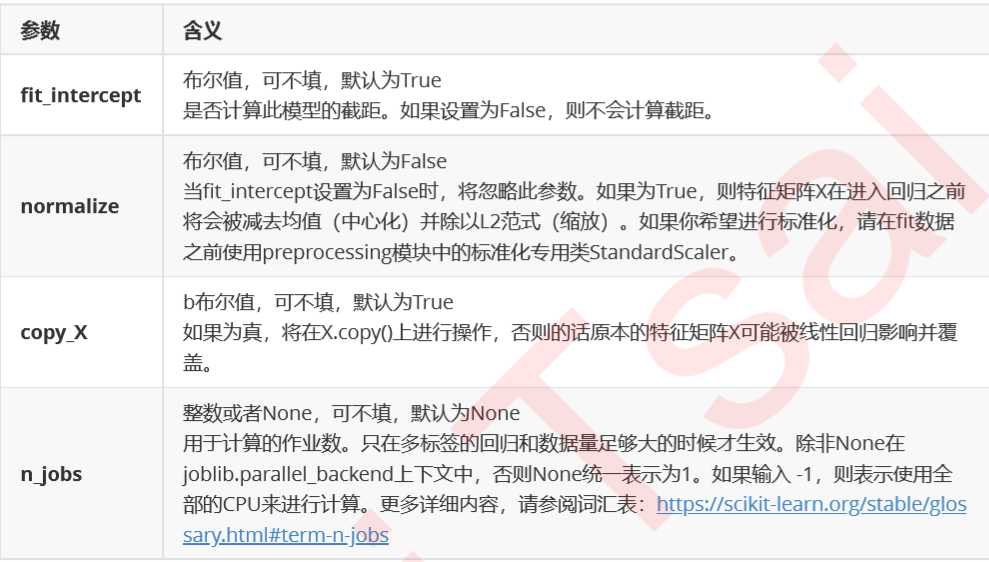
(2)参数:

(3)sklearn的三个坑
【1】均方误差为负
我们在决策树和随机森林中都提到过,虽然均方误差永远为正,但是sklearn中的参数scoring下,均方误差作为评 判标准时,却是计算”负均方误差“(neg_mean_squared_error)。这是因为sklearn在计算模型评估指标的时候, 会考虑指标本身的性质,均方误差本身是一种误差,所以被sklearn划分为模型的一种损失(loss)。在sklearn当中, 所有的损失都使用负数表示,因此均方误差也被显示为负数了。真正的均方误差MSE的数值,其实就是 neg_mean_squared_error去掉负号的数字。
除了MSE,我们还有与MSE类似的MAE(Mean absolute error,绝对均值误差)
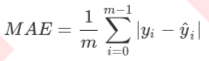
其表达的概念与均方误差完全一致,不过在真实标签和预测值之间的差异外我们使用的是L1范式(绝对值)。现实 使用中,MSE和MAE选一个来使用就好了。在sklearn当中,我们使用命令from sklearn.metrics import mean_absolute_error来调用MAE,同时,我们也可以使用交叉验证中的scoring = "neg_mean_absolute_error",以此在交叉验证时调用MAE。
【2】相同的评估指标不同的结果
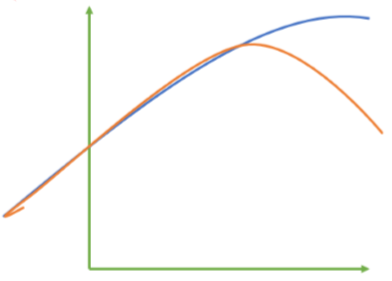
来看这张图,其中红色线是我们的真实标签,而蓝色线是我们的拟合模型。这是一种比较极端,但的确可能发生的 情况。这张图像上,前半部分的拟合非常成功,看上去我们的真实标签和我们的预测结果几乎重合,但后半部分的拟合却非常糟糕,模型向着与真实标签完全相反的方向去了。对于这样的一个拟合模型,如果我们使用MSE来对它 进行判断,它的MSE会很小,因为大部分样本其实都被完美拟合了,少数样本的真实值和预测值的巨大差异在被均分到每个样本上之后,MSE就会很小。但这样的拟合结果必然不是一个好结果,因为一旦我的新样本是处于拟合曲线的后半段的,我的预测结果必然会有巨大的偏差,而这不是我们希望看到的。所以,我们希望找到新的指标,除了判断预测的数值是否正确之外,还能够判断我们的模型是否拟合了足够多的,数值之外的信息。
在我们学习降维算法PCA的时候,我们提到我们使用方差来衡量数据上的信息量。如果方差越大,代表数据上的信 息量越多,而这个信息量不仅包括了数值的大小,还包括了我们希望模型捕捉的那些规律。为了衡量模型对数据上 的信息量的捕捉,我们定义了 和可解释性方差分数(explained_variance_score,EVS)来帮助我们
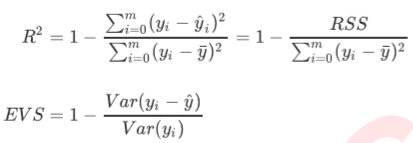
其中y是我们的真实标签, y^是我们的预测结果, y-是我们的均值,Var表示方差。方差的本质是任意一个y值和样本 均值的差异,差异越大,这些值所带的信息越多。在R2和EVS中,分子是真实值和预测值之差的差值,也就是我们的模型没有捕获到的信息总量,分母是真实标签所带的信息量,所以两者都衡量1 - 我们的模型没有捕获到的信息量占真实标签中所带的信息量的比例,所以,两者都是越接近1越好.

在我们的分类模型的评价指标当中,我们进行的是一种 if a == b的对比,这种判断和if b == a其实完全是一种概念,所以我们在进行模型评估的时候,从未踩到我们现在在的这个坑里。然而看R2的计算公式,R2明显和分类模型的指标中的accuracy或者precision不一样,R2涉及到的计算中对预测值和真实值有极大的区别,必须是预测值在分子,真实值在分母,所以我们在调用metrcis模块中的模型评估指标的时候,必须要检查清楚,指标的参数中,究竟是要求我们先输入真实值还是先输入预测值。
我们观察到,虽然我们在加利福尼亚房子价值数据集上的MSE相当小,但我们的R2却不高,这证明我们的模型比较好地拟合了数据的数值,却没有能正确拟合数据的分布。让我们与绘图来看看,究竟是不是这样一回事。我们可以绘制一张图上的两条曲线,一条曲线是我们的真实标签Ytest,另一条曲线是我们的预测结果yhat,两条曲线的交叠越多,我们的模型拟合就越好。
【3】负的R2
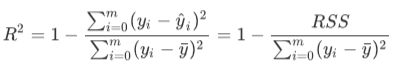
一直以来,众多的机器学习教材中都有这样的解读:
除了RSS之外,我们还有解释平方和ESS(Explained Sum of Squares,也叫做SSR回归平方和)以及总离差平方和 TSS(Total Sum of Squares,也叫做SST总离差平方和)。解释平方和ESS定义了我们的预测值和样本均值之间的 差异,而总离差平方和定义了真实值和样本均值之间的差异,两个指标分别写作:

而我们有公式: TSS = RSS + ESS
看我们的R2的公式,如果带入我们的TSS和ESS,那就有

而ESS和TSS都带平方,所以必然都是正数,那 怎么可能是负的呢?
好了,颠覆认知的时刻到来了——公式TSS = RSS + ESS不是永远成立的!就算所有的教材和许多博客里都理所当然这样写了大家也请抱着怀疑精神研究一下,你很快就会发现很多新世界。我们来看一看我们是如何证明(1)这个公 式的
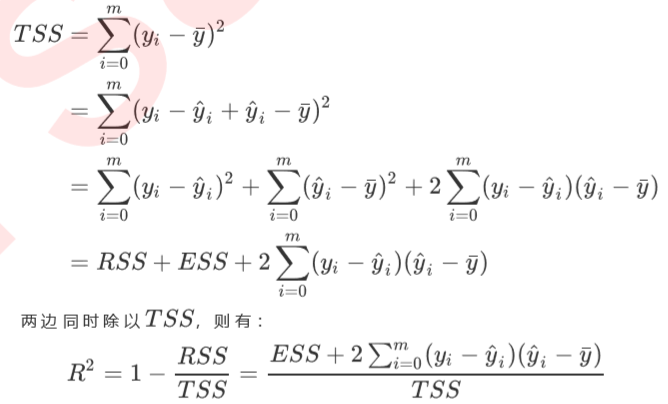

看下面这张图,蓝色的横线是我们的均值线y-,橙色的线是我们的模型y^,蓝色的点是我们的样本点。现在对于xi来说,我们的真实标签减预测值的值(yi-yi^)为正,但我们的预测值(yi^-y-)却是一个负数,这说明,数据本身的均值,比我们对数据的拟合模型本身更接近数据的真实值,那我们的模型就是废的,完全没有作用,类似于分类模 型中的分类准确率为50%,不如瞎猜.

也就是说,当我们的R2显示为负的时候,这证明我们的模型对我们的数据的拟合非常糟糕,模型完全不能使用。 所有,一个负的R2是合理的。当然了,现实应用中,如果你发现你的线性回归模型出现了负的 ,不代表你就要接受他了,首先检查你的建模过程和数据处理过程是否正确,也许你已经伤害了数据本身,也许你的建模过程是存在bug的。如果你检查了所有的代码,也确定了你的预处理没有问题,但你的R2也还是负的,那这就证明,线性回归模型不适合你的数据,试试看其他的算法吧.
(4)举例
1 2 3 4 5 6 | def linear_regression(x_train,y_train,x_test): model = LR() reg = model.fit(x_train,y_train) pred = reg.predict(x_test)# print(reg.coef_) print(pred) |
2. 岭回归Ridge
(1)

(2)举例:
先找到最好的alpha,然后将alpha带入线性模型中训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | def find_min_alpha(x_train, y_train): alphas = np.logspace(-2, 3, 200) # print(alphas) test_scores = [] alpha_score = [] for alpha in alphas: clf = Ridge(alpha) test_score = -cross_validation.cross_val_score(clf, x_train, y_train, cv=10, scoring='neg_mean_squared_error') test_scores.append(np.mean(test_score)) alpha_score.append([alpha, np.mean(test_score)]) print("final test score:")# print(test_scores)# print(alpha_score) sorted_alpha = sorted(alpha_score, key=lambda x: x[1], reverse=False)# print(sorted_alpha) alpha = sorted_alpha[0][0] print("best alpha:" + str(alpha)) return alpha |
1 2 3 4 5 6 7 8 9 10 11 12 | def linear_regression_with_Ridge(x_train,y_train,x_test,alpha): clf = Ridge(alpha=alpha) scores = -cross_validation.cross_val_score(clf,x_train,y_train, cv=10,scoring='neg_mean_squared_error') print('scores',scores) print('mean score',scores.mean()) clf.fit(x_train,y_train)# print(clf.coef_)# print(clf.intercept_) ans = clf.predict(x_test)# print('ans',ans.shape) |
以Ridge线性回归为基回归器的随机森林
1 2 3 4 5 6 7 8 9 10 11 | def create_model(x_train,y_train,alpha): print('begin to train') model = Ridge(alpha=alpha) clf1 = ensemble.BaggingRegressor(model,n_jobs=1,n_estimators=900) scores = -cross_validation.cross_val_score(model,x_train,y_train,cv=10,scoring='neg_mean_squared_error') print('========================') print('Scores:') print(scores.mean()) clf1.fit(x_train,y_train) print('Finish') return clf1 |
3. LASSO

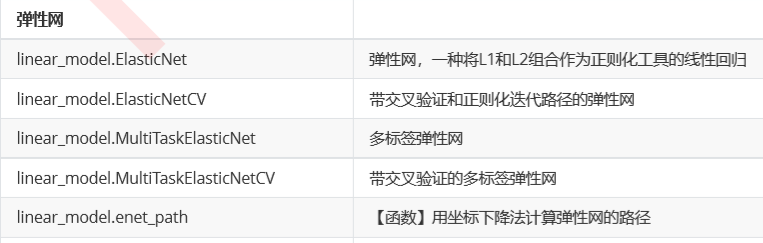
4. 弹性网
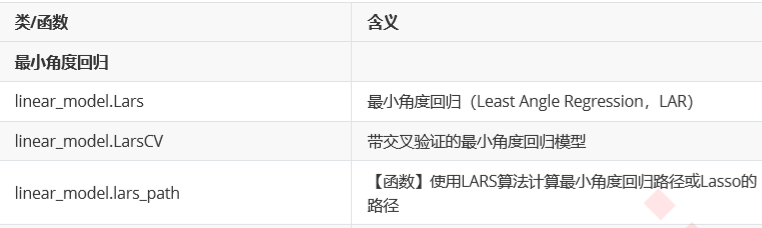
5. 最小角度回归
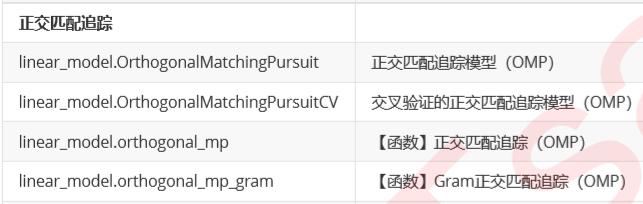
6.正交匹配追踪
7.贝叶斯回归

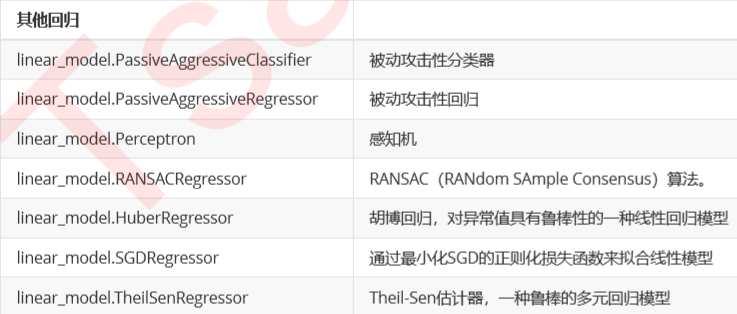
8.其他回归


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现