

22(4).模型融合---Xgboost
一、简介
全称:eXtreme Gradient Boosting
作者:陈天奇
基础:GBDT
所属:boosting迭代型、树类算法
适用范围:回归,分类,排序
xgboost工具包:sklearn xgboost链接 | xgboost工具包(中文)链接 | xgboost工具包(英文)链接
优点:
- 显示的把树模型复杂度作为正则项加到优化目标中。
- 公式推导中用到了二阶导数,用了二阶泰勒展开。
- 实现了分裂点寻找近似算法。
- 利用了特征的稀疏性。
- 数据事先排序并且以block形式存储,有利于并行计算。
- 基于分布式通信框架rabit,可以运行在MPI和yarn上。
- 实现做了面向体系结构的优化,针对cache和内存做了性能优化。
缺点:(与LightGBM相比)
- XGBoost采用预排序,在迭代之前,对结点的特征做预排序,遍历选择最优分割点,数据量大时,贪心法耗时,LightGBM方法采用histogram算法,占用的内存低,数据分割的复杂度更低;
- XGBoost采用level-wise生成决策树,同时分裂同一层的叶子,从而进行多线程优化,不容易过拟合,但很多叶子节点的分裂增益较低,没必要进行跟进一步的分裂,这就带来了不必要的开销;LightGBM采用深度优化,leaf-wise生长策略,每次从当前叶子中选择增益最大的结点进行分裂,循环迭代,但会生长出更深的决策树,产生过拟合,因此引入了一个阈值进行限制,防止过拟合;
二、Xgboost
1.损失函数
xgboost 也是使用与提升树相同的前向分步算法。其区别在于:xgboost 通过结构风险极小化来确定下一个决策树的参数 :
最初损失函数:
在GBDT损失函数的基础上,加入正则项其中,J是叶子节点的个数,是第j个叶子节点的最优值,这里的和GBDT中的是一个意思,Xgboost论文中用的是w表示叶子的值,这里和论文保持一致。
损失函数的二阶展开:
为了方便,记第i个样本在第t个弱学习器的一阶和二阶导数分别为:
则损失函数可以表达为:
第一项是常数,对最小化loss无影响,可以去掉,同时由于每个决策树的第j个叶子节点的取值最终是同一个值,因此损失函数简化为:
把每个叶子节点区域样本的一阶和二阶导数的和单独表示如下:
最终损失函数的形式可以表示为:
问题1:xgboost如何使用MAE或MAPE作为目标函数?参考链接
xgboost需要目标函数的二阶导数信息(或者hess矩阵),在回归问题中经常将MAE或MAPE作为目标函数,然而,这两个目标函数二阶导数不存在。
,
其中,是真实值,是预测值
方法(1):利用可导的函数逼近MAE或MAPE---MSE、Huber loss、Pseudo-Huber loss
利用MSE逼近是可以的,但是MSE在训练初误差较大的时候,loss是其平方,会使得训练偏离MAE的目标函数,一般难以达到高精度的要求。
利用Huber loss进行逼近也可以,但是Huber loss是分段函数,不方便计算,其中是可调节参数。
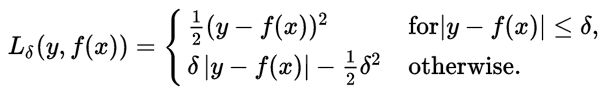

实际采用Huber loss的可导逼近形式:Pseudo-Huber loss function
![]()
一阶导数:
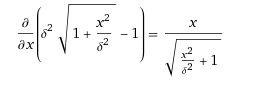
二阶导数:
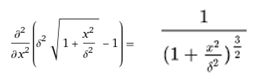
方法(2):自定义二阶导数的值:
用以及进行逼近


的一阶导数:
的二阶导数:
2.结构分
3.寻找分裂节点的候选集
Xgboost框架用tree_method[默认为’auto’] 指定了构建树的算法,可以为下列的值(分布式,以及外存版本的算法只支持 ‘approx’,’hist’,’gpu_hist’ 等近似算法):
1 2 3 4 5 6 7 8 9 | ‘auto’: 使用启发式算法来选择一个更快的tree_method: 对于小的和中等的训练集,使用exact greedy 算法分裂节点 对于非常大的训练集,使用近似算法分裂节点 旧版本在单机上总是使用exact greedy 分裂节点‘exact’: 使用exact greedy 算法分裂节点‘approx’: 使用近似算法分裂节点‘hist’: 使用histogram 优化的近似算法分裂节点(比如使用了bin cacheing 优化)‘gpu_exact’: 基于GPU 的exact greedy 算法分裂节点‘gpu_hist’: 基于GPU 的histogram 算法分裂节点 |
3.1 暴力枚举(exact greedy)
(1)第一种方法是对现有的叶节点加入一个分裂,然后考虑分裂之后目标函数降低多少。
- 如果目标函数下降,则说明可以分裂;
- 如果目标函数不下降,则说明该叶节点不宜分裂。
(2)对于一个叶节点,加入给定其分裂点,定义划分到左子样本节点的集合为:,则有:

(3)定义叶节点的分裂增益为:
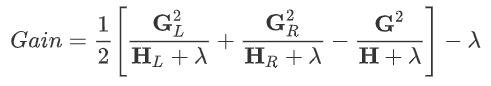
其中,
- 表示:该叶节点的左子树的结构分
- 表示:该叶节点的右子树的结构分
- 表示:如果不分裂,则该叶节点自身的结构分
- 表示:因为分裂导致叶节点数量增大1,从而导致增益的下降。
每次只有一个叶节点分裂,因此其他叶节点不会发生变化,因此:
- 若,则该叶节点应该分裂;
- 若,则该叶节点不宜分裂。
(4)现在的问题是:不知道分裂点,对于每个叶节点,存在多个分裂点,且可能很多分裂点都能带来增益。
解决办法:对于叶节点中的所有可能的分裂点进行一次扫描。然后计算每个分裂点的增益,选取增益最大的分裂点作为本叶节点的最优分裂点。
(5)最优分裂点贪心算法

输入:,属于当前叶节点的样本集的下标集合
输出:当前叶节点最佳分裂点
算法:
step1:初始化 ,,
step2:遍历各维度 $k=1,2,...,m$:
a)初始化:
b)如果第维特征为连续值,则将当前叶节点中的样本从小到大排序。然后用顺序遍历排序后的样本下标。
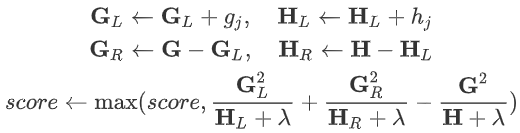
c)如果第维特征为离散值ka_j\mathbb{I_j}j=1,2,...,n_k$:

step3:选取最大的对应的维度和拆分点作为最优拆分点。
分裂点贪心算法尝试所有特征和所有分裂位置,从而求得最优分裂点。当样本太大且特征为连续值时,这种暴力做法的计算量太大。
3.2 近似算法(approx)
(1)近似算法寻找最优分裂点时不会枚举所有的特征值,而是对特征值进行聚合统计,然后形成若干个桶。然后仅仅将桶边界上的特征的值作为分裂点的候选,从而获取计算性能的提升。
(2)对第k个特征进行分桶,分桶的数量l就是所有样本在第k个特征上的取值的数量。
如果第k个特征为连续特征,则执行百分位分桶,得到分桶的区间为:,其中,分桶的数量、分桶的区间都是超参数,需要仔细挑选
如果第k个特征为离散特征,则执行按离散值分桶,得到的分桶为:,其中, 为第k个特征的所有可能的离散值。
(3)最优分裂点近似算法

算法流程:
输入:数据集,属于当前叶结点的样本集的下标集合
输出:当前叶节点最佳分裂点
step1:对每个特征进行分桶。假设对第k个特征上的值进行分桶为:,如果第k个特征为连续特征,则要求满足
step2:初始化:
step3:遍历各维度:
初始化:
遍历各拆分点,即遍历:
如果是连续特征,即设叶节点的样本中,第k个特征取值在区间的样本的下标集合为,则:

如果是离散特征,则设叶结点的样本中,第k个特征取值等于的样本的下标集合为 ,则:

选取最大的score对应的维度和拆分点作为最优拆分点。
(4)分桶有两种模式:
全局模式:在算法开始时,对每个维度分桶一次,后续的分裂都依赖于该分桶并不再更新;
优点:只需要计算一次,不需要重复计算;
缺点:在经过多次分裂之后,叶节点的样本有可能在很多全局桶中是空的。
局部模式:每次拆分之后再重新分桶;
优点:每次分桶都能保证各桶中的样本数量都是均匀的;
缺点:计算量较大。
全局模式会构造更多的候选拆分点,而局部模式会更适合构造构造更深的树。
(5)分桶时的桶区间间隔大小是个重要的参数。区间间隔越小,则桶越多,划分的越精细,候选的拆分点就越多。
3.2.1 Quantile
(1)-quantile
Quantile就是ranking。如果有个元素,那么-quantile就是指rank在的元素。例如,首先排序为,则. 上面的是exact quantile寻找方法,如果数据集非常大,难以排序,则需要引入

该方法为离线算法(所有的数必须要排序,再找分位点),是不适用于数据流的。
(2)-approximate -quantiles
-quantile是在区间

当增加时,-quantile的“正确”答案(-近似)的集合增加。因此,您可以从输入流中删除一些元素,并仍保留ε近似分位数查询的正确答案(=询问近似分位数的查询)

回到XGBoost的建树过程,在建立第i棵树的时候已经知道数据集在前面i−1棵树的误差,因此采样的时候是需要考虑误差,对于误差大的特征值采样粒度要加大,误差小的特征值采样粒度可以减小,也就是说采样的样本是需要权重的。
重新审视目标函数:
通过配方可以得到
因此可以将该目标看做是第棵决策树,关于真实标签为和权重为的、损失函数为平方损失的形式。
3.2.2 Weighted Quantile Sketch
(1)二阶导数为权重的解释
如果损失函数是Square loss,即,则,那么实际上是不带权;如果损失函数是Log Loss,则。这是个开口朝下的一元二次函数,所以最大值在0.5。当在0.5附近,这个值是非常不稳定的,很容易误判,h作为权重则因此变大,那么直方图划分,这部分就会被切分的更细。
(2)问题转换
假设候选样本的第k维特征,及候选样本的损失函数的二阶偏导数为:
定义排序函数:表示样本的第个特征
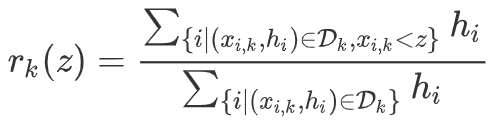
它刻画的是:第维特征小于的样本的之和,占总的之和的比例,其中二阶导数可以视为权重,在这个排序函数下,找到一组点,满足:。
其中,,为采样率,直观上理解,最后会得到个分界点。其中表示样本的第个特征,即:
最小的拆分点:所有样本第维的最小值;
最大的拆分点:所有样本第维的最大值;
中间的拆分点:选取拆分点,使得相邻拆分点的排序函数值小于(分桶的桶宽)。其意义为:第维大于等于,小于的样本的之和,占总的之和的比例小于;这种拆分点使得每个桶内的以为权重的样本数量比较均匀,而不是样本个数比较均匀。
举例:
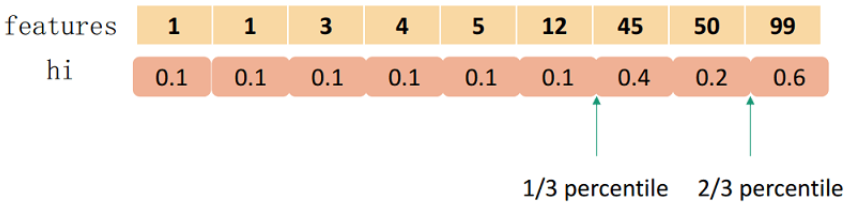
要切分为3个,总和为1.8,因此第1个在0.6处,第2个在1.2处。
对于每个样本都有相同权重的问题,有quantile sketch算法解决该问题,作者提出Weighted Quantile Sketch算法解决这种weighted datasets的情况
(3)Weighted Quantile Sketch算法
问题:To design an algorithm, you must first design an adequate data structure to maintain the information used by the algorithm
a) []


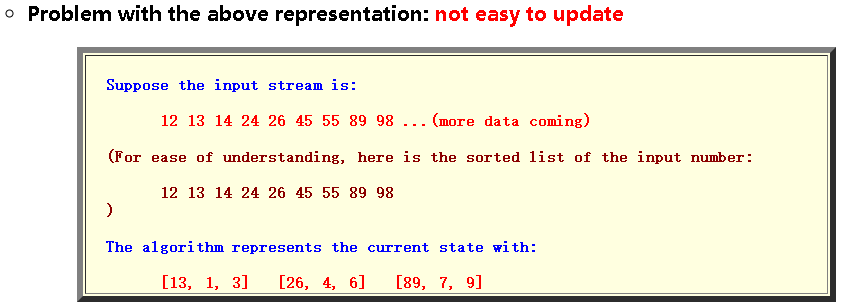
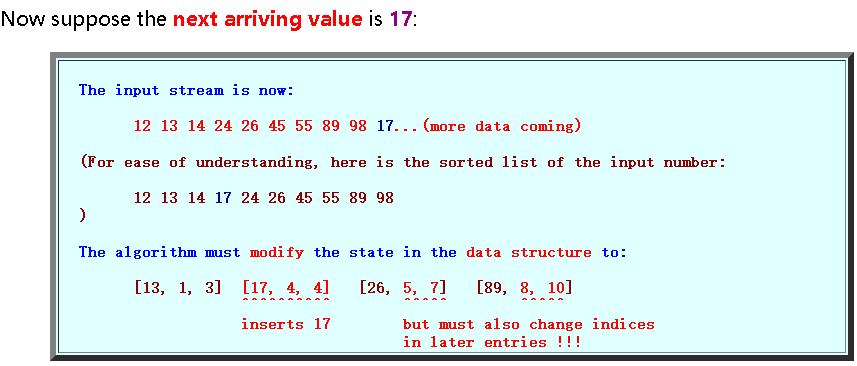
该数据结构需要每插入值进行大量操作。 虽然它很有用,但效率不高
b) []



这个数据结构存在问题:它不包含足够的信息来删除不必要的条目
c) Greenwald & Khanna's 算法:[]
定义:

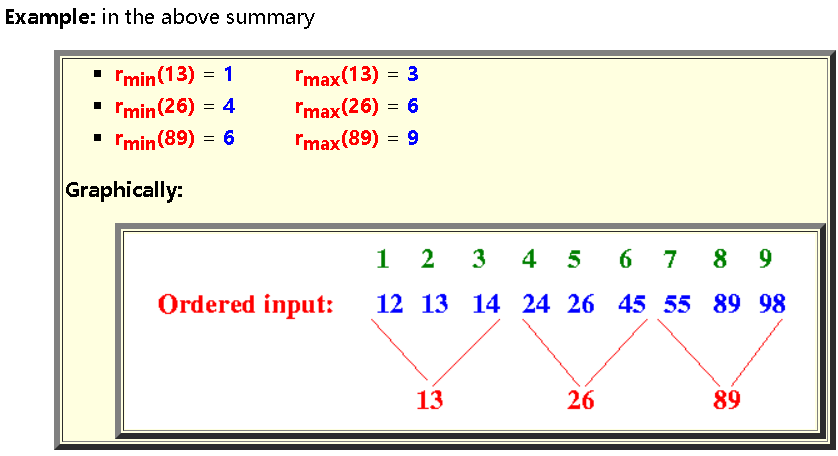
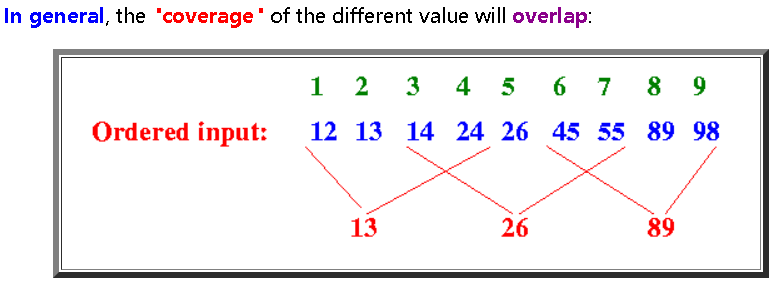

=目前为止遇到的最小的数
=目前为止遇到的最大的数
三个性质:
- 性质1:

- 性质2:

- 性质3:

举例:

命题1:summary达到的准确度,误差

推论1:Greenwald和Khanna算法的不变性

GK算法框架:先判断是否要合并,再插入

插入算法:
- Inserting an arriving value must maintain the consistency of the information in the summary

删除算法:

how to use the quantile summary?
- The quantile summary is used to answer quantile queries
- Given a ε-approximate quantile summary, how do we use it to answer a quantile queries ?

3.3 直方图算法(hist)
直方图聚合是树木生长中的主要计算瓶颈。我们引入了一种新的树生长方法hist,其中只考虑了可能的分裂值的子集。与FastBDT和LightGBM一样,连续特征被分成不连续的区域。由于较少的索引操作,直方图累积变得更快
新方法与tree_method = approx有何不同?
- xgboost中现有的近似分裂方法还将连续特征存储到离散区间以加速训练。 approx方法为每次迭代生成一组新的bin,而hist方法在多次迭代中重用bin。
hist方法可以实现approx方法无法实现的额外优化,如下所示:
- 箱的缓存:用bin ID替换训练数据中的连续特征值并缓存数据结构
- 直方图减法技巧:为了计算一个节点的直方图,我们简单地取其父和兄弟的直方图之间的差异。
除了上述改进之外,还有一些亮点
- 自然支持稀疏矩阵的有效表示,如xgboost,稀疏矩阵,混合稀疏+密集矩阵的有效加速
- 可扩展到xgboost中的其他现有功能,例如单调约束,语言绑定。
如何使用?
- 只需将tree_method设置为hist即可。您可能还需要设置max_bin,它表示存储连续特征的(最大)离散区间数。默认情况下,max_bin设置为256.增加此数字可以提高分割的最佳性,但代价是计算时间较长。
4.缺失值
(1)真实场景中,有很多可能导致产生稀疏。如:数据缺失、某个特征上出现很多 0 项、人工进行 one-hot 编码导致的大量的 0。
- 理论上,数据缺失和数值0的含义是不同的,数值 0 是有效的。
- 实际上,数值0的处理方式类似缺失值的处理方式,都视为稀疏特征。
- 在xgboost 中,数值0的处理方式和缺失值的处理方式是统一的。这只是一个计算上的优化,用于加速对稀疏特征的处理速度。
- 对于稀疏特征,只需要对有效值进行处理,无效值则采用默认的分裂方向。
注意:每个结点的默认分裂方向可能不同。
(2)在xgboost 算法的实现中,允许对数值0进行不同的处理。可以将数值0视作缺失值,也可以将其视作有效值。 如果数值0是有真实意义的,则建议将其视作有效值。
(3)缺失值处理算法
输入:数据集
属于当前叶结点的样本集的下标集合
属于当前叶节点,且第维特征有效的样本的下标集合
输出:当前叶节点最佳分裂点
step1:初始化:
step3:遍历各维度:
先从左边开始遍历:
初始化:
遍历各拆分点:沿着第维,将当前有效的叶节点的样本从小到大排序。这相当于所有无效特征值的样本放在最右侧,因此可以保证无效的特征值都在右子树。然后用顺序遍历排序后的样本下标:

再从右边开始遍历:
初始化:
遍历各拆分点:沿着第维,将当前有效的叶节点的样本从大到小排序。这相当于所有无效特征值的样本放在最左侧,因此可以保证无效的特征值都在左子树。然后用逆序遍历排序后的样本下标:
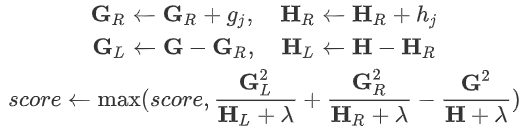
选取最大的score对应的维度和拆分点作为最优拆分点。
缺失值处理算法中,通过两轮遍历可以确保稀疏值位于左子树和右子树的情形。
5. 其他优化
5.1 正则化
xgboost在学习过程中使用了如下的正则化策略来缓解过拟合:
- 通过学习率来更新模型:,,也叫shrinkage
- 类似于随机森林,采取随机属性选择,也叫col_sample
5.2 计算速度提升
xgboost在以下方面提出改进来提升计算速度:
- 预排序pre-sorted;
- cache-aware预取;
- Out-of-Core大数据集
5.2.1 预排序
(1)xgboost提出column block数据结构来降低排序时间。
- 每一个block代表一个特征的值,样本在该block中按照它在该特征的值排好序。这些block只需要在程序开始的时候计算一次,后续排序只需要线性扫描这些block即可。
- Block中的数据以稀疏格式CSC进行存储。
- 由于属性之间是独立的,因此在每个维度寻找划分点可以并行计算。
时间复杂度减少:
- 在Exact greedy算法中,将整个数据集存放在一个Block中。这样,复杂度从原来的降为,其中为训练集中非缺失值的个数。这样,Exact greedy算法就省去了每一步中的排序开销。 在近似算法中,使用多个Block,每个Block对应原来数据的子集。不同的Block可以在不同的机器上计算。该方法对Local策略尤其有效,因为Local策略每次分支都重新生成候选切分点。
(2)block可以仅存放样本的索引,而不是样本本身,这样节省了大量的存储空间。
如:block_1代表所有样本在feature_1上的从小到大排序:sample_no1,sample_no2,...
其中样本编号出现的位置代表了该样本的排序。
可以看出,只需在建树前排序依次,后面节点分裂时可以直接根据索引得到梯度信息。
5.2.2 预取
(1)由于在column block中,样本的顺序会被打乱,这会使得从导数数组中获取时的缓存命中率较低。
因此,xgboost提出了cache-aware预取算法,对每个线程分配一个连续的buffer,读取梯度信息并存入Buffer中(这样就实现了非连续到连续的转化),然后再统计梯度信息。该方式在训练样本数大的时候特别有用,用于提升缓存命中率。
(2)xgboost会以minibatch的方式累加数据,然后在后台开启一个线程来加载需要用到的导数。
这里有个折中:minibatch太大,会引起cache miss;太小,则并行程度较低。
5.2.3 Out-of-Core
(1)xgboost利用硬盘来处理超过内存容量的大数据量,其中使用了下列技术:
- 使用block压缩技术来缓解内存和硬盘的数据交换IO:数据按列压缩,并且在硬盘到内存的传输过程中被自动解压缩;
- 数据随机分片到多个硬盘,每个硬盘对应一个预取线程,从而加大“内存-硬盘”交换数据的吞吐量。
参考文献:
【5】『我爱机器学习』集成学习(三)XGBoost - 细语呢喃
【6】gbdt.pdf
【7】Xgboost系统设计:分块并行、缓存优化和Blocks for Out-of-core Computation - anshuai_aw1的博客 - CSDN博客


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构