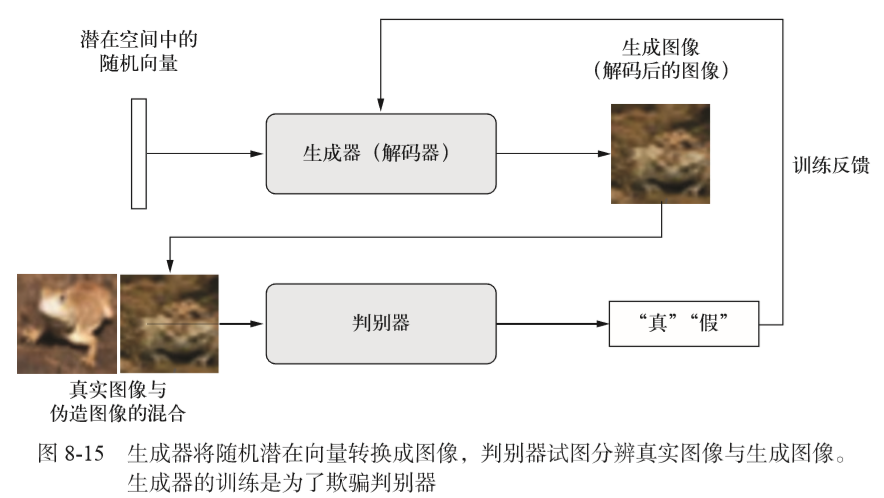
生成式对抗网络(GAN,generative adversarial network)由Goodfellow等人于2014年提出,它可以替代VAE来学习图像的潜在空间。它能够迫使生成图像与真实图像在统计上几乎无法区别,从而生成相当逼真的合成图像。
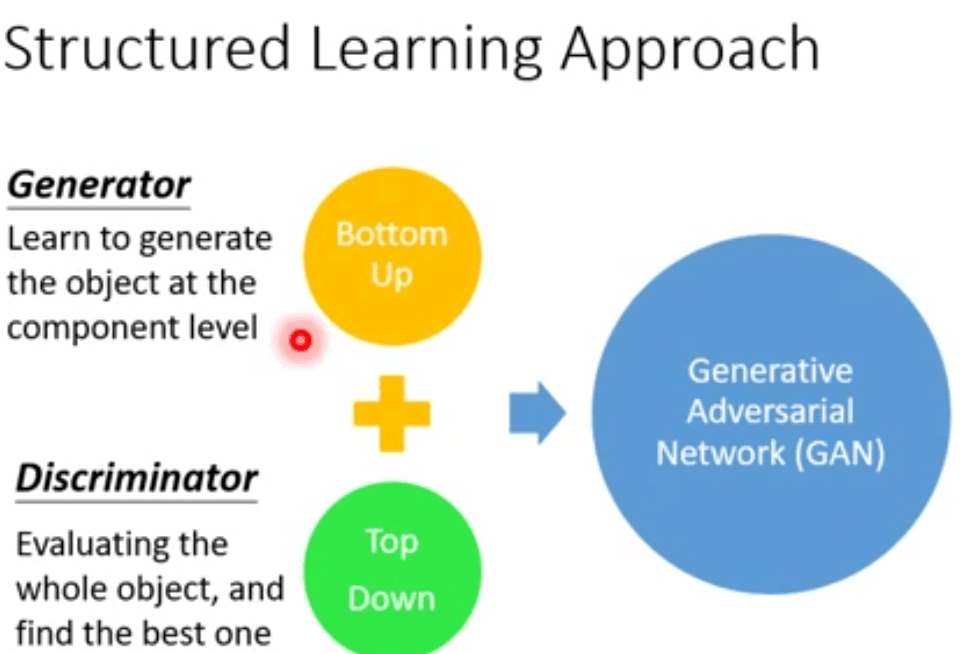
1.GAN是什么?
简单来说就是由两部分组成,生成器generator网络和判别器discriminator网络。一部分不断进化,使其对立部分也不断进化,实现共同进化的过程。
对GAN的一种直观理解是,想象我们想要试图生成一个二次元头像。一开始,我们并不擅长这项任务,就将自己的一些噪音二次元头像和真的二次元头像混在一起,并将其展示给discriminator。discriminator对每个头像进行真实性评估,并向我们给出反馈,告诉我们是什么让二次元头像看起来像真的二次元头像,我们回到自己的工作室,并准备一些新的二次元头像。随着时间的推移,我们变得越来越擅长模仿二次元头像的风格,discriminator也变得越来越擅长找出假的二次元头像。最后,我们手上拥有了一些优秀的二次元头像。

2.为什么?
【1】为什么我们有真的二次元头像和假的二次元头像,为什么不自己用监督学习生成新的二次元头像呢?
generator无法自己独立学习的原因是,以vae为例,输出layer层输出的是各像素点,而他们在输出时是独立的,没有相互作用的,因此无法判断总体的效果进行自主学习。对于discriminator,其输入是生成的整张图像,因此可以从总体上进行判断。
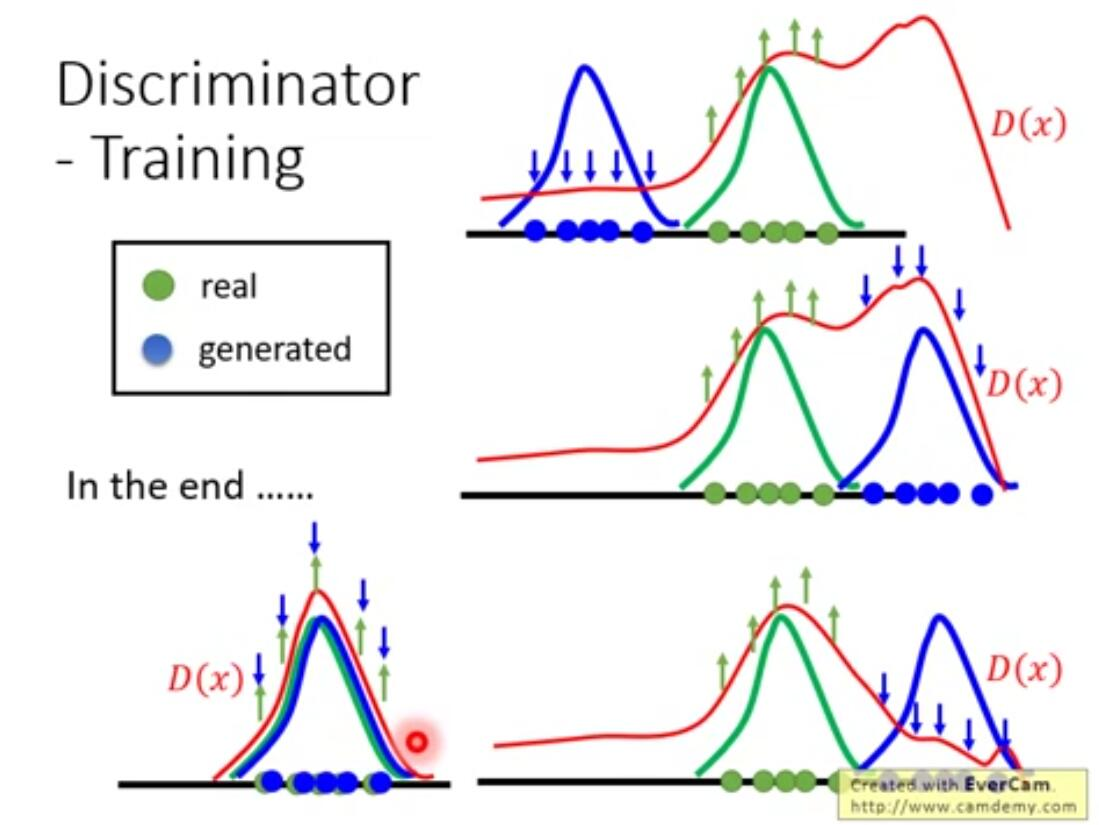
需要注意的是,discriminator对于输入的真实图像都应是高分,那么如果训练时只给它真实图像的话,他就无法实现正确的判断,会将所有输入都判为高分。所以需要一些差的图像送给discriminator进行训练,并且这些差的图像不应是简单的加些噪声之类的能让它轻易分辨的。因此,训练它的方法是,除真实图像外先给它一些随机生成的差的例子,然后对discriminator解argmaxD(x)做generation生成出一些他觉得好的图像,然后将原本极差的图像换为这些图像再进行训练,如此往复,discriminator会不断产生更好的图像,将这些作为negative examples给其学习,达到训练的目的。
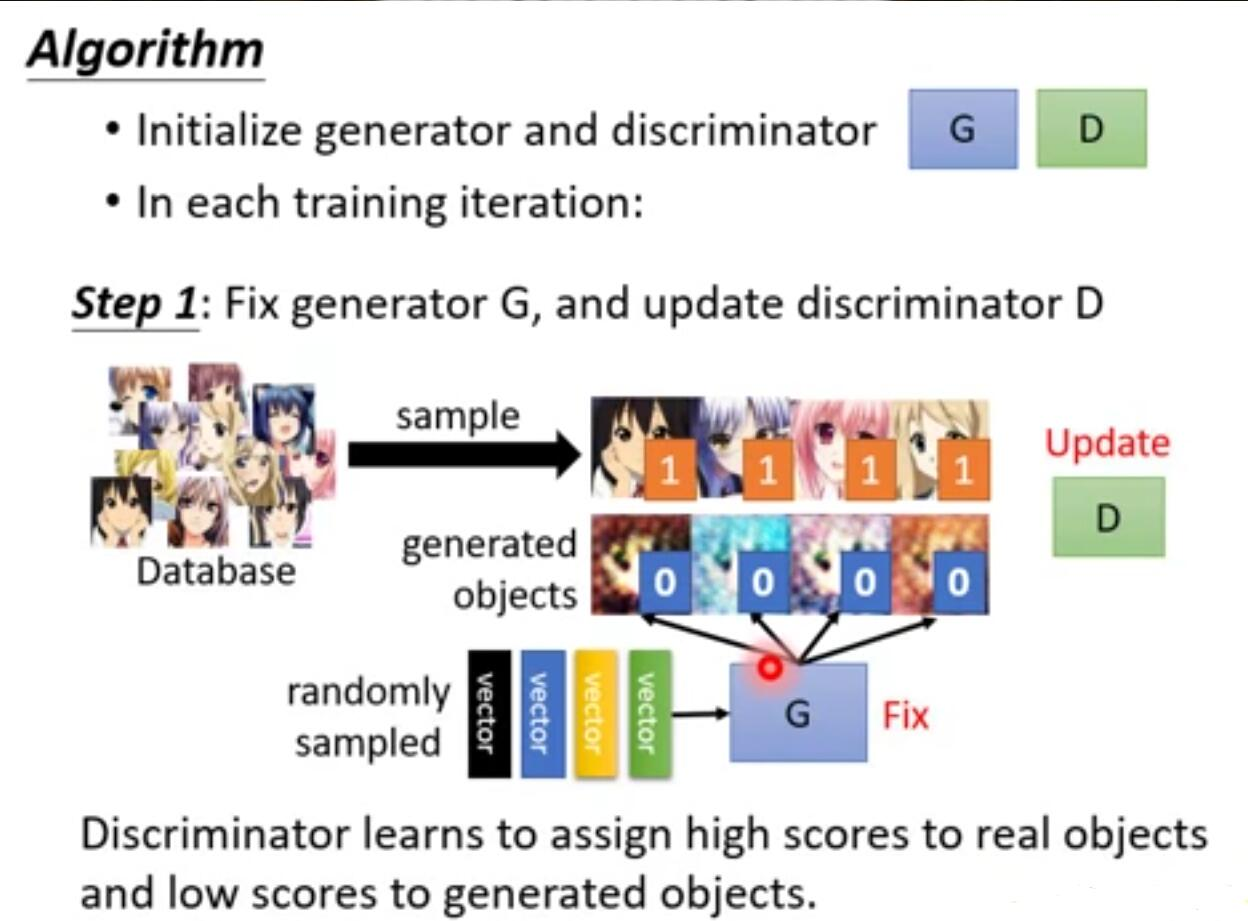
【2】discriminator对真的二次元头像这么了解,为什么他不自己做,而是要来指导我们做呢?
那既然如此,为什么还需要generator呢?discriminator自己也可以生成图像啊?
这是因为discriminator生成图像需要解argmaxD(x), 难度较大,一般需要假设一些条件才会好解,比如网络假设为线性时,但这样会限制图像的生成效果。而generator生成非常快,因此将二者结合起来共同学习实现输出好的结果。二者优缺点如下所示:

总而言之,因为generator没有全局观,所以需要结合discriminator学习,对于discriminator,使用generator生成图像比自己解方程生成更简单高效,这二者的优缺点相互补充。
GAN的目的是为了生成,而VAE目的是为了压缩,目的不同效果自然不同。比如,由于二范数的原因,VAE的生成是模糊的。而GAN的生成是犀利的。

数据集为CIFAR10,包含50000张32*32的RGB图像,这些图像属于10个类别(每个类别5000张图像),这里我们只使用属于“frog”(青蛙)类别的图像
1 2 3 | import keras
from keras import layers
import numpy as np
|
|
|
|
生成器网络:将一个向量(来自潜在空间,训练过程中对其随机采样)转换为一张候选图像
生成器从未直接见过训练集中的图像,它所知道的关于数据的信息都来自于判别器。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | latent_dim = 32
height = 32
width = 32
channels = 3
generator_input = keras.Input(shape=(latent_dim,))
x = layers.Dense(128*16*16)(generator_input)
x = layers.LeakyReLU()(x)
x = layers.Reshape((16,16,128))(x)
x = layers.Conv2D(256,5,padding='same')(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2DTranspose(256,4,strides=2,padding='same')(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(256,5,padding='same')(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(256,5,padding='same')(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(channels,7,activation='tanh',padding='same')(x)
generator = keras.models.Model(generator_input,x)
generator.summary()
|
|

|
|
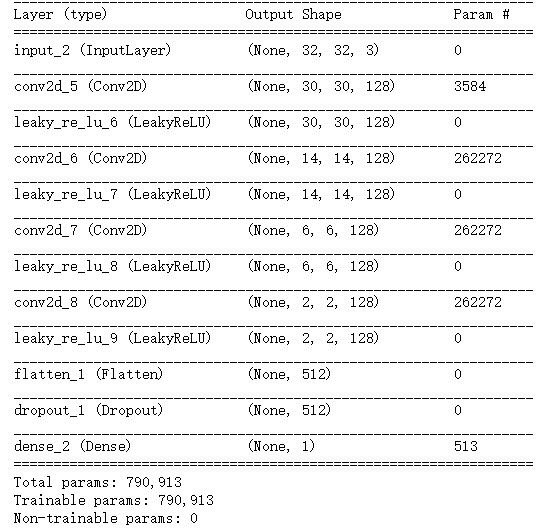
判别器网络:它接收一张候选图像(真实的或合成的)作为输入,并将其划分到这两个类别之一:"生成图像"或"来自训练集的真实图像"
|
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | discriminator_input = layers.Input(shape=(height,width,channels))
x = layers.Conv2D(128,3)(discriminator_input)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(128,4,strides=2)(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(128,4,strides=2)(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(128,4,strides=2)(x)
x = layers.LeakyReLU()(x)
x = layers.Flatten()(x)
x = layers.Dropout(0.4)(x)
x = layers.Dense(1,activation='sigmoid')(x)
discriminator = keras.models.Model(discriminator_input,x)
discriminator.summary()
|
|
|
|
1 2 3 4 5 6 7 8 | discriminator_optimizer = keras.optimizers.RMSprop(
lr=0.0008,
clipvalue = 1.0,
decay = 1e-8,
)
discriminator.compile(optimizer=discriminator_optimizer,
loss='binary_crossentropy')
|
|
设置GAN,将生成器和判别器连接在一起 训练时,这个模型将让生成器向某个方向移动,从而提高它欺骗判别器的能力。这个模型将潜在空间的点转换为一个分类决策(即"真"或"假") 它训练的标签都是"真实图像"。因此,训练gan将会更新generator得到权重,使得discriminator在观测假图像时更有可能预测为"真"。
|
|
对抗网络
|
|
1 2 3 4 5 6 7 | discriminator.trainable = True
gan_input = keras.Input(shape=(latent_dim,))
gan_output = discriminator(generator(gan_input))
gan = keras.models.Model(gan_input,gan_output)
gan_optimizer = keras.optimizers.RMSprop(lr=0.0004,clipvalue=1.0,decay=1e-8)
gan.compile(optimizer=gan_optimizer,loss='binary_crossentropy')
|
|
注意:在训练过程中需要将判别器设置为冻结(即不可训练),这样在训练gan时它的权重才不会更新。 如果在此过程中可以对判别器的权重进行更新,那么我们就是在训练判别器始终预测"真",但这并不是我们想要的。
|
|
实现GAN的训练
|
|
1 2 3 4 5 6 | import os
from keras.preprocessing import image
(x_train,y_train),(_,_) = keras.datasets.cifar10.load_data()
x_train = x_train[y_train.flatten() == 6]
x_train = x_train.reshape((x_train.shape[0],) + (height,width,channels)).astype('float32')/255.
|
|
|
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | iterations = 1000
batch_size = 2
save_dir = 'frog_dir'
start = 0
for step in range(iterations):
random_latent_vectors = np.random.normal(size=(batch_size,latent_dim))
generated_images = generator.predict(random_latent_vectors)
stop = start + batch_size
real_images = x_train[start:stop]
combined_images = np.concatenate([generated_images,
real_images])
labels = np.concatenate([np.ones((batch_size,1)),
np.zeros((batch_size,1))])
labels += 0.05 * np.random.random(labels.shape)
d_loss = discriminator.train_on_batch(combined_images,labels)
random_latent_vectors = np.random.normal(size=(batch_size,latent_dim))
misleading_targets = np.zeros((batch_size,1))
a_loss = gan.train_on_batch(random_latent_vectors,misleading_targets)
start += batch_size
if start > len(x_train) - batch_size:
start = 0
if step % 2 == 0:
gan.save_weights('gan.h5')
print('discriminator loss:',d_loss)
print('adversarial loss:',a_loss)
img = image.array_to_img(generated_images[0] * 255.,scale=False)
img.save(os.path.join(save_dir,'generated_frog'+str(step)+'.png'))
img = image.array_to_img(real_images[0]*255.,scale=False)
img.save(os.path.join(save_dir,'real_frog'+str(step)+'.png'))
|
|
判别器损失:d_loss=(生成的图像和真实图像->标签)
gan损失:a_loss=(随机采样的点->全是'真'的标签)
第一次 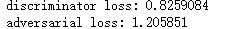
最后一次 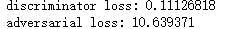
|



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现